Векторные представления слов
Word2Vec, GloVe, FastText — как слова становятся векторами.
Word Embeddings — как научить компьютер понимать слова
Нейросеть не умеет работать со словами напрямую — ей нужны числа. Самый наивный способ: присвоить каждому слову номер. «Кот» = 42, «собака» = 137. Но тогда модель решит, что «собака» в три раза больше «кота» — бессмысленно. Нужно представление, которое сохраняет смысловые отношения между словами.
Word embeddings (векторные представления слов) — именно такое представление. Каждое слово превращается в вектор из 100-300 чисел, и эти числа подобраны так, что семантически близкие слова оказываются рядом в пространстве. «Кот» и «кошка» — рядом. «Кот» и «бетономешалка» — далеко.
В основе лежит простая, но мощная идея — дистрибутивная гипотеза (distributional hypothesis): смысл слова определяется контекстом, в котором оно появляется. Джон Фёрс, 1957: «You shall know a word by the company it keeps» — «Ты узнаешь слово по компании, которую оно водит». Если «кот» и «собака» регулярно появляются в одних и тех же контекстах («гулять с ___», «покормить ___», «___ спит на диване»), значит они семантически похожи.
Модель не «понимает» смысл слова. Она просто замечает закономерности в статистике совместной встречаемости. И этого оказывается достаточно, чтобы выучить удивительно точные семантические отношения.
Большая картина: от one-hot к плотным векторам
До эмбеддингов слова представляли one-hot векторами: словарь из 50 000 слов → вектор длиной 50 000, где ровно одна единица (позиция слова), а остальные нули. Проблемы очевидны:
- Огромная размерность. Словарь в 100K слов → векторы длиной 100K. Хранить и обрабатывать дорого.
- Нулевое сходство. Косинусное сходство любых двух one-hot векторов = 0. Для модели «кот» и «кошка» так же далеки, как «кот» и «квантовая механика».
- Нет обобщения. Модель, выучившая что-то про «кота», ничего не знает про «кошку» — это совершенно разные точки в пространстве.
Плотные (dense) эмбеддинги решают все три проблемы. Вместо разреженного вектора длиной |V| каждое слово получает плотный вектор из d чисел (обычно d = 100-300). Каждое измерение кодирует какой-то аспект смысла: «одушевлённость», «размер», «абстрактность» — хотя модель не называет эти оси явно, они возникают из данных.
Аналогия: one-hot — это адрес квартиры (ул. Пушкина, 42). Он уникален, но ничего не говорит о самой квартире. Плотный эмбеддинг — это описание: [площадь=65м², этаж=3, до метро=500м, цена=8М]. Теперь можно сравнивать квартиры и находить похожие.

Word2Vec — революция 2013 года
Word2Vec (Миколов и команда, Google, 2013) — первый метод, который сделал эмбеддинги массовыми. Идея гениально проста: обучить маленькую нейросеть предсказывать слова по контексту (или контекст по слову), а потом взять веса этой сети как эмбеддинги.
Две архитектуры — два подхода к одной задаче:
CBOW vs Skip-gram
Аналогия: представь предложение с пропущенным словом. CBOW (Continuous Bag of Words) — ты видишь контекст и угадываешь пропущенное слово: «покормить ___ на кухне» → «кота». Skip-gram — наоборот: тебе дают слово, а ты восстанавливаешь контекст: «кота» → «покормить», «на», «кухне».


На практике Skip-gram чаще побеждает: он генерирует больше обучающих пар (одно слово → несколько контекстных), и каждое редкое слово получает достаточно обновлений. CBOW усредняет контекст — теряет тонкости.
Negative Sampling — ускорение на порядки
Главная проблема: на выходе модели — softmax по всему словарю. Если словарь 300K слов, каждый шаг обучения требует вычислить 300K экспонент — это безумно дорого.
Negative sampling элегантно решает проблему: вместо «предскажи правильное слово из 300K» учимся решать бинарную задачу — «настоящая ли это пара (слово, контекст)?». Берём реальную пару из текста (positive) и K случайных «фальшивых» пар (negative). Теперь вместо softmax по 300K — всего K+1 вычислений.
v_w — вектор целевого слова, v_c — вектор контекстного слова (positive), v_n — вектор случайного слова (negative), σ — сигмоида, K — число негативных примеров (обычно 5-15)
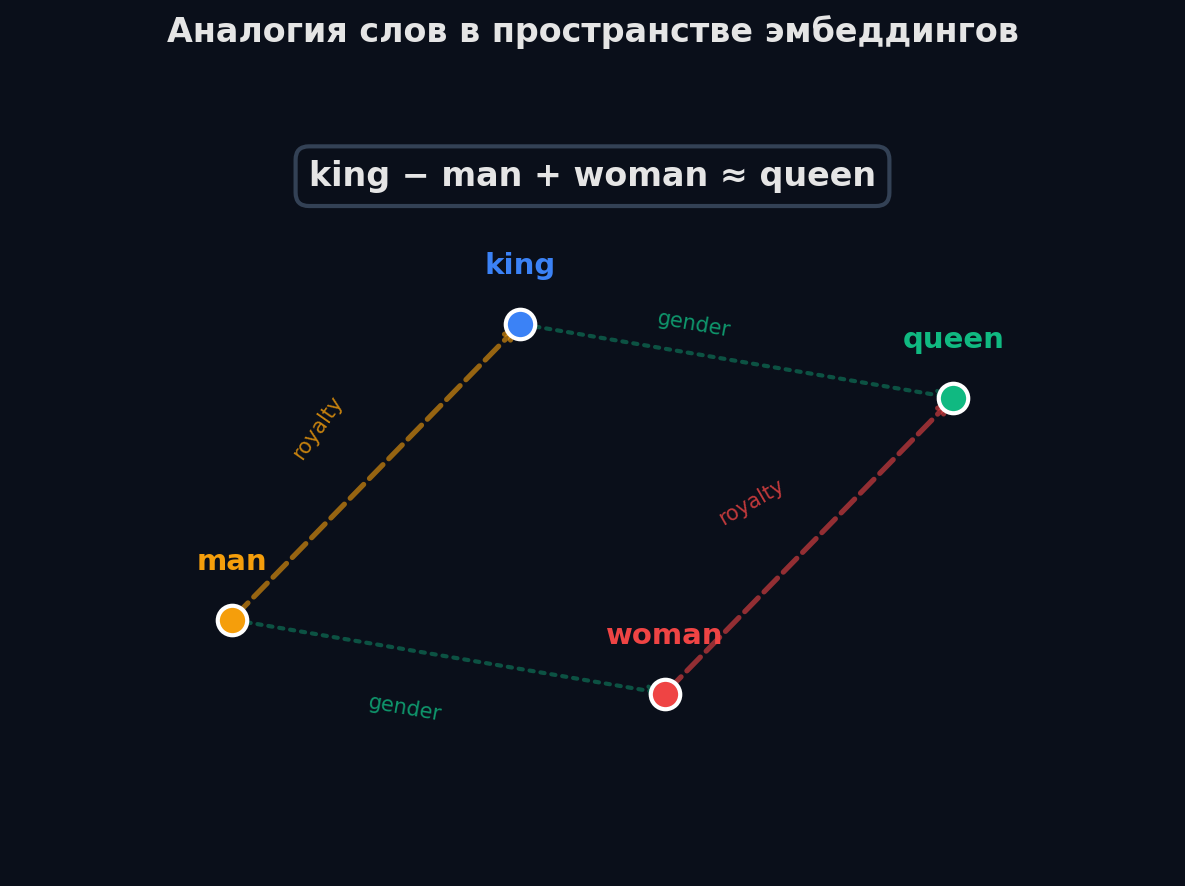
Словесные аналогии — king − man + woman ≈ queen
Самый знаменитый результат Word2Vec: арифметика на векторах слов. vector("король") − vector("мужчина") + vector("женщина") ≈ vector("королева"). Модель уловила, что разница между «король» и «королева» — та же, что между «мужчина» и «женщина». Направление «гендер» выучилось как вектор в пространстве.
Это работает не только для гендера: «Париж» − «Франция» + «Италия» ≈ «Рим» (столицы), «плавал» − «плавать» + «бегать» ≈ «бегал» (времена глаголов). Пространство эмбеддингов структурировано — семантические отношения кодируются как направления.
Загрузка интерактивного виджета...
Загрузка интерактивного виджета...
GloVe — глобальная статистика вместо окна
GloVe (Global Vectors, Pennington et al., Stanford, 2014) подходит к эмбеддингам с другой стороны. Word2Vec — предиктивная модель: обучается предсказывать через скользящее окно. GloVe — count-based: сначала посчитай матрицу совместной встречаемости слов по всему корпусу, а потом факторизуй её.
Матрица ко-встречаемости X_{ij} — сколько раз слово i появилось рядом со словом j во всём корпусе. GloVe подбирает векторы так, чтобы скалярное произведение двух векторов приближало логарифм их совместной частоты: v_i · v_j ≈ log(X_{ij}).
X_{ij} — число совместных появлений слов i и j, f — весовая функция (срезает сверхчастые пары, чтобы «the» не доминировал), b — bias-ы. V — размер словаря
Ключевое отличие от Word2Vec: GloVe напрямую оптимизирует глобальную статистику, а Word2Vec делает это неявно через предсказание в окне. На практике качество эмбеддингов сопоставимо — выбор между ними скорее дело вкуса и удобства. GloVe иногда лучше ловит глобальные паттерны (ко-встречаемость по всему корпусу), Word2Vec — локальные (что рядом в окне).
FastText — морфология решает
У Word2Vec и GloVe есть фатальная проблема: если слова нет в словаре (OOV — out-of-vocabulary), вектора нет. Совсем. Опечатка, новое слово, редкая словоформа — модель беспомощна.
FastText (Bojanowski et al., Facebook, 2016) решает это элегантно: разбивает слово на символьные n-граммы и строит вектор слова как сумму векторов его частей. Слово «бегущий» при n=3 раскладывается на: <бе, бег, егу, гущ, ущи, щий, ий>.
Теперь даже незнакомое слово получает осмысленный вектор из своих частей. А для русского языка с его богатой морфологией это особенно ценно: «бежал», «бегу», «бежать», «перебежчик» — все содержат n-граммы от корня «бег» и получают похожие векторы.
- OOV-слова получают вектор — критично для морфологически богатых языков (русский, финский, турецкий)
- Опечатки обрабатываются корректнее: «привет», «приветик», «привееет» — близкие векторы, потому что разделяют n-граммы
- Редкие слова точнее: для слова, встретившегося 2 раза, Word2Vec даст шумный вектор. FastText вытянет информацию из частей, общих с частыми словами
- N-граммы: обычно от 3 до 6 символов. Плюс само слово целиком — чтобы частые слова имели свой уникальный вектор
Контекстные эмбеддинги: почему статические недостаточны
Word2Vec, GloVe и FastText дают одному слову один вектор навсегда. Но «замок» (дверной) и «замок» (крепость) — разные значения. «Тяжёлый чемодан» и «тяжёлый характер» — разные «тяжёлые». Статические эмбеддинги просто усредняют все значения в один вектор — полисемия игнорируется.
ELMo (Embeddings from Language Models, Peters et al., 2018) — первый массовый подход к решению этой проблемы. Двунаправленная LSTM читает предложение слева направо и справа налево, а вектор слова — конкатенация скрытых состояний. Теперь «замок» в «починить замок» и «увидеть замок» получают разные векторы, потому что контекст разный.
BERT (2018) пошёл дальше: вместо LSTM — трансформер, вместо конкатенации двух направлений — настоящая двунаправленность (каждый токен видит и левый, и правый контекст одновременно). Качество эмбеддингов выросло настолько, что BERT стал новым стандартом. Подробнее — в ноде BERT.
Но статические эмбеддинги не умерли. Они по-прежнему полезны там, где нужны скорость и простота: поиск по сходству (nearest neighbor search), фичи для лёгких моделей, кластеризация текстов, визуализация. Один lookup в таблице вместо forward pass через 12 слоёв BERT.
Практика: как получить и использовать эмбеддинги
Два пути: обучить свои на корпусе или взять предобученные. Для большинства задач предобученные работают отлично — они обучены на миллиардах слов.
Обучение с gensim
from gensim.models import Word2Vec
# Корпус — список предложений, каждое предложение — список слов
sentences = [
["кот", "спит", "на", "диване"],
["собака", "спит", "на", "коврике"],
["кот", "ест", "рыбу"],
["собака", "ест", "мясо"],
["кот", "и", "собака", "играют"],
]
# Обучаем Skip-gram (sg=1), вектор 100 размерностей, окно 3
model = Word2Vec(sentences, vector_size=100, window=3, sg=1, min_count=1, epochs=100)
# Самые похожие слова
model.wv.most_similar("кот", topn=3)
# [('собака', 0.98), ('ест', 0.91), ('спит', 0.89)]
# Арифметика на векторах
model.wv.most_similar(positive=["король", "женщина"], negative=["мужчина"])Предобученные эмбеддинги
Для реальных задач лучше использовать предобученные модели — обучение на 5 предложениях, как выше, даст мусор. Источники:
- gensim-data:
api.load("word2vec-google-news-300")— 300d, обучены на Google News (3M слов) - FastText: предобученные для 157 языков, включая русский —
fasttext.cc - Navec (для русского): компактные (50d), быстрые, хорошее качество —
natasha/navec - HuggingFace: контекстные эмбеддинги через
transformers— BERT, RoBERTa и др.
Визуализация через t-SNE
300-мерные векторы нельзя увидеть глазами. t-SNE (t-distributed Stochastic Neighbor Embedding) проецирует их в 2D, стараясь сохранить соседство: близкие в 300D должны остаться близкими в 2D.
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
words = ["кот", "собака", "кошка", "щенок", "Москва", "Париж", "Лондон"]
vectors = [model.wv[w] for w in words]
tsne = TSNE(n_components=2, perplexity=5, random_state=42)
coords = tsne.fit_transform(vectors)
plt.figure(figsize=(8, 6))
for i, word in enumerate(words):
plt.scatter(coords[i, 0], coords[i, 1])
plt.annotate(word, (coords[i, 0] + 0.5, coords[i, 1] + 0.5))
plt.title("t-SNE визуализация эмбеддингов")
plt.show()Осторожно с t-SNE
Как оценить качество эмбеддингов
Cosine Similarity — основная мера близости
Для сравнения эмбеддингов используют косинусное сходство — косинус угла между двумя векторами. Значения от −1 (противоположные) до 1 (идентичные). Почему не евклидово расстояние? Косинус не зависит от длины вектора — важно только направление. Два вектора могут иметь разную величину, но одинаковый смысл.
a · b — скалярное произведение, ||a|| и ||b|| — нормы (длины) векторов
Intrinsic vs Extrinsic оценка
Intrinsic оценка — проверяем сами эмбеддинги «в вакууме»:
- Задачи на аналогии: king − man + woman = ? Точность на стандартном датасете (Google Analogy Test)
- Корреляция с человеческими оценками: SimLex-999, WordSim-353 — люди оценили пары слов по сходству, смотрим корреляцию с cosine similarity эмбеддингов
- Категоризация: правильно ли эмбеддинги группируют слова по темам
Extrinsic оценка — подставляем эмбеддинги в реальную задачу (классификация текстов, NER, sentiment analysis) и сравниваем метрики. Extrinsic надёжнее: хорошие аналогии не гарантируют хорошую классификацию, а посредственные эмбеддинги иногда отлично работают на конкретной задаче.
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Эволюция представления слов: one-hot (разреженный, без семантики) → Word2Vec/GloVe (плотные статические эмбеддинги, дистрибутивная гипотеза) → FastText (subword, решает OOV) → ELMo/BERT (контекстные эмбеддинги, решают полисемию).
Если запомнить одну вещь из этой ноды: слово = вектор, и похожие слова = близкие векторы. Вся магия word embeddings — в том, что этот принцип, основанный на простой статистике совместной встречаемости, выучивает удивительно глубокие семантические отношения.
Дальше на роадмапе: RNN и LSTM используют эмбеддинги как входные представления для последовательных моделей, а Transformer заменяет последовательную обработку на self-attention — и именно его контекстные эмбеддинги стали новым стандартом.
Материалы
Интерактивный разбор Word2Vec, GloVe и свойств эмбеддингов. Лучший бесплатный материал по теме.
Визуальное пошаговое объяснение Word2Vec с отличными диаграммами.
Лекция Мэннинга: Word2Vec, GloVe, математика за эмбеддингами.
Оригинальная страница GloVe с предобученными моделями и статьёй.
Предобученные модели для 157 языков, обучение своих эмбеддингов, классификация текстов.