Классификация текста
Naive Bayes, логистическая регрессия, CNN для текста — практические задачи.
Классификация текстов — от Naive Bayes до CNN
Определить тональность отзыва, отфильтровать спам, раскидать тикеты по категориям — всё это классификация текстов. Задача старая, решения проверенные. Хорошая новость: для 80% продакшн-задач хватает TF-IDF + LogReg. Плохая новость: на собесе спросят и про нейросетевые подходы.
Naive Bayes — удивительно сильный бейзлайн
Аналогия: ты получил письмо и решаешь — спам или нет. Видишь слово «скидка» — вероятность спама выросла. Видишь «отчёт» — упала. Naive Bayes делает то же самое: считает вероятность класса при условии наблюдаемых слов. «Наивное» допущение — слова независимы друг от друга. Это грубо неправда, но на практике работает неожиданно хорошо.
Naive Bayes для текста: вероятность класса c при документе d пропорциональна произведению априорной вероятности класса и likelihood каждого слова w_i
- Multinomial NB — считает количество вхождений слов. Стандартный выбор для текста
- Bernoulli NB — бинарные признаки: слово есть/нет. Лучше для коротких текстов
- Сглаживание Лапласа (α=1) — чтобы нулевая частота слова не обнулила всё произведение
- На практике: обучается за секунды, не переобучается на малых данных, отличная отправная точка
На собесе
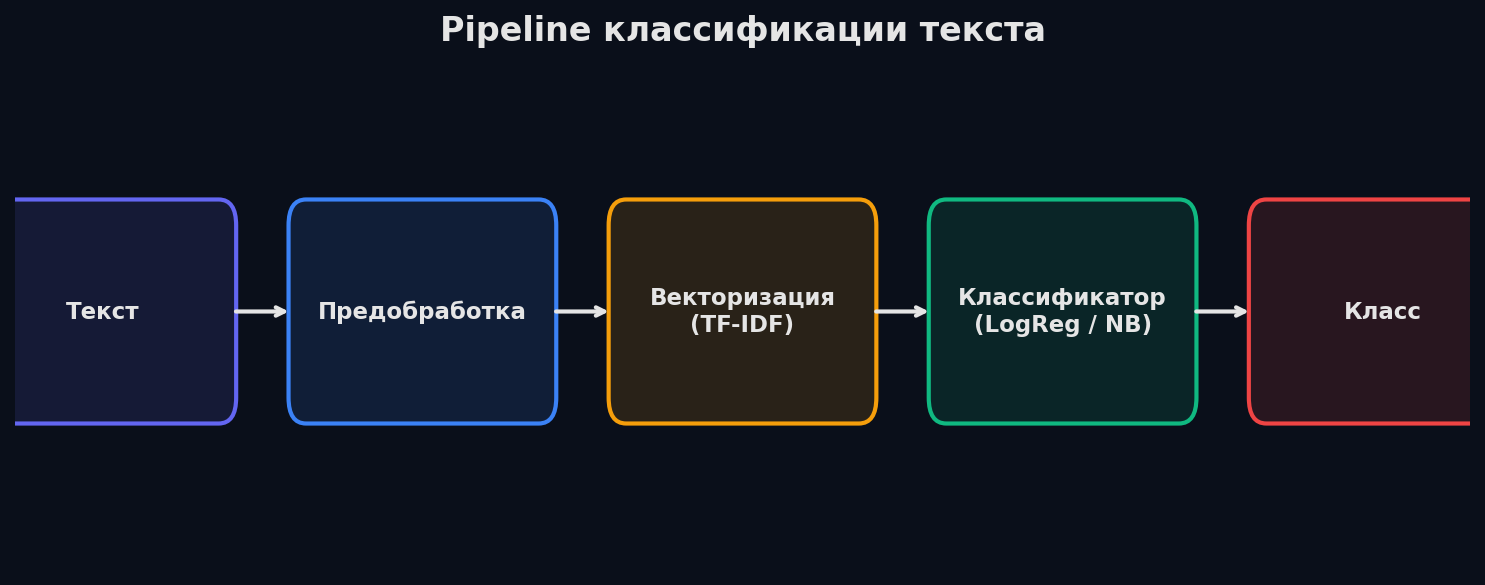
TF-IDF + LogReg — рабочая лошадка
TF-IDF превращает текст в разреженный вектор, логистическая регрессия проводит разделяющую гиперплоскость. Два шага, никакой магии. Работает на удивление хорошо: на задачах sentiment analysis и topic classification бьёт простые LSTM, если данных меньше 50k. Плюс — полная интерпретируемость: можно вытащить топ-слова для каждого класса и понять, что модель выучила.
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
pipe = Pipeline([("tfidf", TfidfVectorizer(ngram_range=(1,2))),
("clf", LogisticRegression(max_iter=1000))])
pipe.fit(X_train, y_train) # X_train — список строкПрактические нюансы
- ngram_range=(1,2) — добавить биграммы. «Не нравится» → фича «не_нравится» спасает sentiment
- max_features=50000 — ограничить словарь, иначе матрица может не влезть в память
- class_weight="balanced" — если классы несбалансированы (спам: 5%, не спам: 95%)
- Препроцессинг: lowercase, удалить HTML/URL, но НЕ убирать стоп-слова для LogReg — модель сама разберётся с весами
CNN для текста — свёртки по n-граммам
Yoon Kim, 2014. Идея простая: слова → матрица эмбеддингов (каждая строка — вектор слова). По этой матрице едут свёрточные фильтры разных размеров (3, 4, 5 слов) — по сути, детекторы n-грамм. Потом max pooling — из каждого фильтра берём самое сильное срабатывание. Получается вектор фиксированной длины → полносвязный слой → класс.
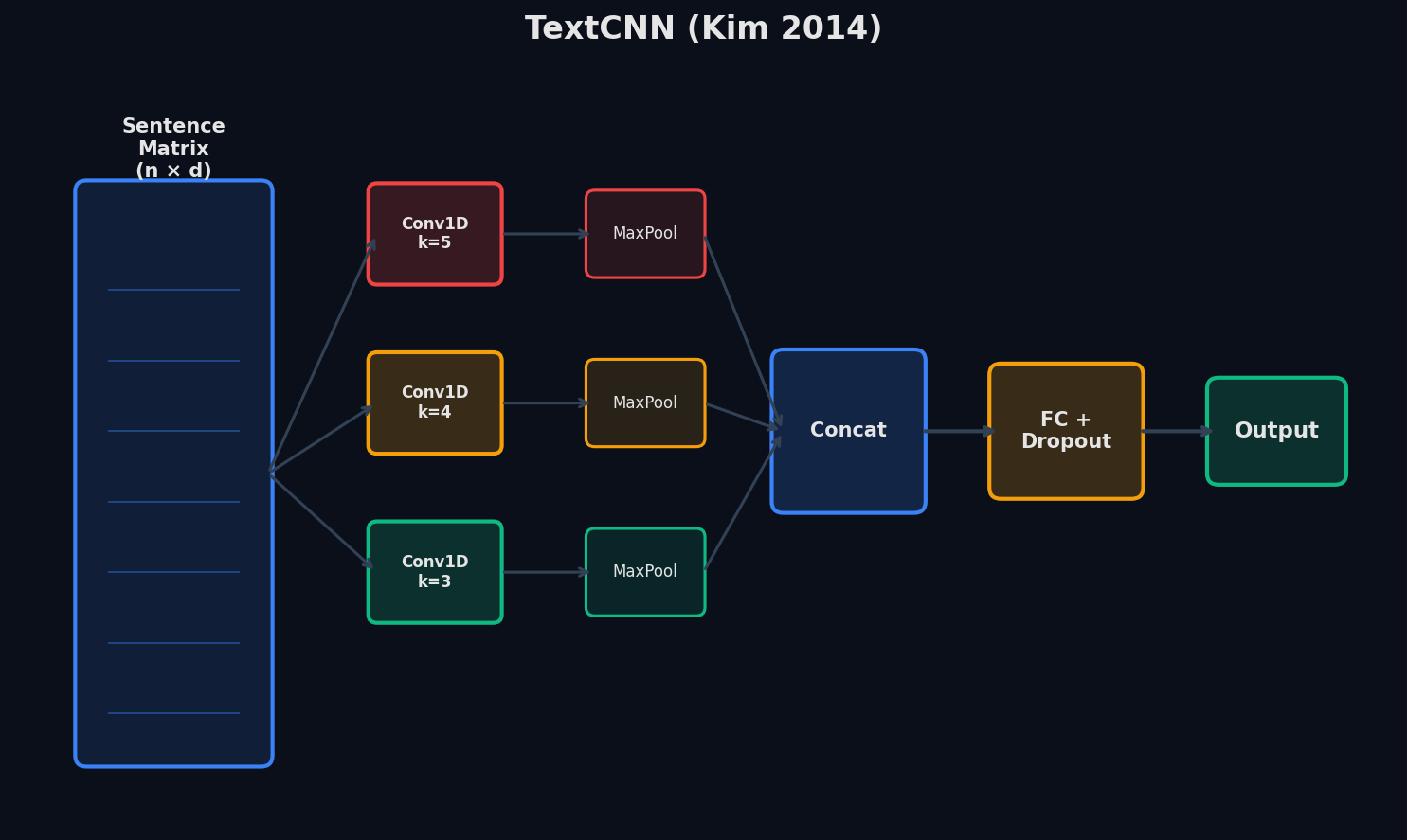
- Фильтр размера 3 — ловит триграммы («не очень хорошо»). Размера 5 — более длинные паттерны
- Max-over-time pooling — фиксированный выход независимо от длины текста
- Обычно используют предобученные эмбеддинги (Word2Vec, GloVe) и дообучают на задаче
- TextCNN обучается быстро (минуты на GPU), качество выше TF-IDF+LogReg при 50k+ примеров
На собесе
Когда что использовать
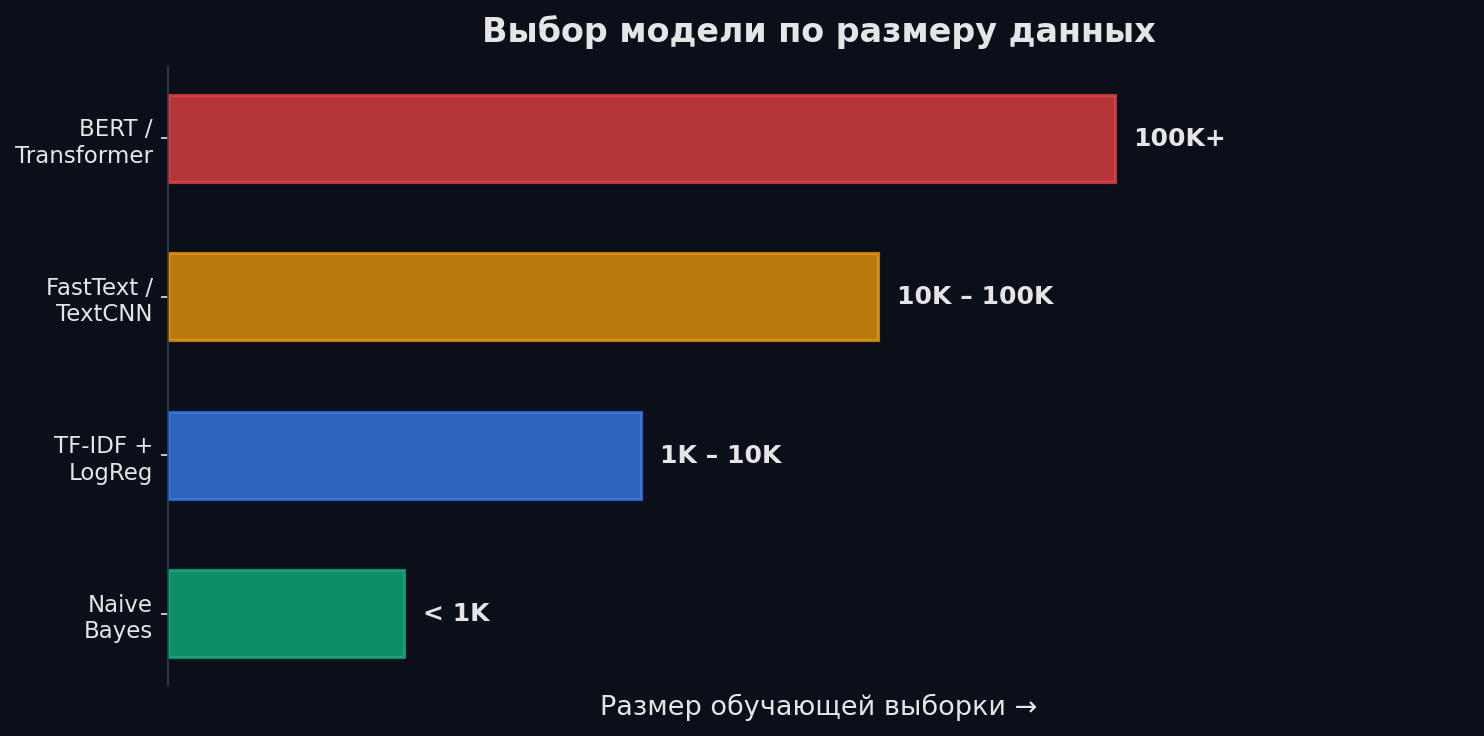
Выбор зависит от объёма данных и требований. Общее правило: начни с простого, усложняй по необходимости. Если TF-IDF + LogReg даёт F1 0.92 — не нужен BERT.
- < 1k примеров — Naive Bayes или TF-IDF + LogReg. Нейросети переобучатся
- 1k–50k — TF-IDF + LogReg/SVM как бейзлайн, TextCNN если нужно точнее
- 50k+ — TextCNN, BiLSTM с attention, или fine-tuned BERT если есть GPU
- Многоязычность — fasttext-классификатор: быстрый, поддерживает 170+ языков из коробки
Метрики для классификации текстов
Accuracy — обманчива при дисбалансе. Для спам-фильтра с 5% спама accuracy 95% достигается моделью «всё не спам». Используй macro/weighted F1, precision/recall по классам. Для sentiment (позитив/негатив/нейтрал) — macro F1. Для токсичности — precision важнее: лучше пропустить токсик, чем заблокировать нормальный комментарий. Метрика зависит от бизнес-задачи, не от модели.
🎯 Суть для собеса
Материалы
Интерактивный разбор подходов к классификации текстов: от BoW до CNN.
Оригинальная статья TextCNN. Короткая, понятная, must-read.
Лекция Мэннинга по нейросетевым подходам к классификации текстов.
Практический туториал sklearn: от загрузки данных до оценки качества.