RNN и LSTM
Рекуррентные сети, затухание градиентов, LSTM/GRU, BiLSTM.
RNN и LSTM — как нейросети научились помнить
Загрузка интерактивного виджета...
Обычный MLP обрабатывает каждый вход независимо — подал картинку, получил класс. Но что, если данные — это последовательность, где порядок критичен? Предложение «кот съел рыбу» и «рыба съела кота» — одни и те же слова, но совсем разный смысл. Временной ряд цен акций — каждая точка бессмысленна без контекста предыдущих.
Рекуррентные нейросети (RNN) решают именно эту проблему: они обрабатывают данные шаг за шагом, передавая «память» о прошлом на каждый следующий шаг. Это первая архитектура, которая дала нейросетям способность работать с текстом, речью, музыкой и другими последовательностями.
Сегодня RNN уступили место трансформерам в большинстве задач NLP. Но понимание RNN и LSTM — не просто «история»: это фундамент, на котором строились seq2seq, attention, и в конечном итоге сам трансформер. А на собеседованиях RNN/LSTM спрашивают стабильно — и у джуниора, и у мидла.
Большая картина: hidden state как «память»
Аналогия: ты читаешь книгу. В каждый момент ты видишь одно слово (текущий вход x_t), но в голове держишь контекст — кто герои, что произошло, какая интрига (скрытое состояние h_t). Прочитав новое слово, ты обновляешь контекст: может, появился новый персонаж, может, сюжет повернулся. RNN работает точно так же.
Вот что происходит на каждом шаге: 1. RNN получает текущий вход x_t (например, эмбеддинг слова) 2. И предыдущее скрытое состояние h_{t−1} (память о всех прошлых шагах) 3. Из них вычисляет новое скрытое состояние h_t 4. Из h_t можно получить выход y_t (например, предсказание следующего слова) Ключевая идея: одна и та же сеть применяется на каждом шаге. Параметры (матрицы весов) — общие для всех позиций. Это называется развёртка во времени (unrolling).

Vanilla RNN — формула и forward pass пошагово
Vanilla RNN — простейшая рекуррентная архитектура. Обновление скрытого состояния — одна формула:
h_t — новое скрытое состояние, h_{t−1} — предыдущее, x_t — текущий вход, W_hh — рекуррентные веса, W_xh — веса входа, b_h — смещение, tanh — нелинейность (сжимает выход в [−1, +1])
Разберём по шагам: W_xh преобразует текущий вход, W_hh преобразует предыдущую память, всё складывается и проходит через tanh. Результат — новая память, которая содержит информацию и о текущем входе, и обо всём, что было раньше.
Числовой пример: forward pass
Возьмём крошечную RNN с размерностью скрытого состояния d_h = 2 и размерностью входа d_x = 2. Предложение из двух слов: x₁ = [1, 0], x₂ = [0, 1].
import numpy as np
# Параметры (инициализируем вручную для примера)
W_xh = np.array([[0.5, 0.0],
[0.0, 0.5]]) # 2×2: вход → скрытое
W_hh = np.array([[0.8, 0.0],
[0.0, 0.8]]) # 2×2: скрытое → скрытое
b_h = np.array([0.0, 0.0]) # смещение
h_0 = np.array([0.0, 0.0]) # начальное состояние — нули
# Шаг 1: x₁ = [1, 0]
z_1 = W_hh @ h_0 + W_xh @ np.array([1, 0]) + b_h # = [0, 0] + [0.5, 0] = [0.5, 0]
h_1 = np.tanh(z_1) # = [0.462, 0.0]
# Шаг 2: x₂ = [0, 1]
z_2 = W_hh @ h_1 + W_xh @ np.array([0, 1]) + b_h # = [0.370, 0] + [0, 0.5] = [0.370, 0.5]
h_2 = np.tanh(z_2) # = [0.354, 0.462]
print(f"h_1 = {h_1}") # [0.462, 0.0] — запомнили первое слово
print(f"h_2 = {h_2}") # [0.354, 0.462] — содержит инфо об обоих словахОбрати внимание: h₂ = [0.354, 0.462] содержит «след» от первого слова (0.354 — это затухшее 0.462 через W_hh) и информацию о втором слове (0.462). Так RNN накапливает контекст. Но с каждым шагом старая информация умножается на W_hh и проходит через tanh — она экспоненциально затухает. Это и есть корень проблемы.
Проблема vanishing gradients: почему RNN забывает
Представь предложение: «Мария, которая родилась в Париже и выросла в Лондоне, говорит по-французски». Чтобы правильно предсказать «говорит» (единственное число), модель должна помнить «Мария» через 10+ слов. Vanilla RNN с этим не справляется.
Почему? При обучении (BPTT — Backpropagation Through Time) градиент проходит назад по всем шагам. На каждом шаге он умножается на матрицу W_hh и на производную tanh. Производная tanh ∈ (0, 1], и собственные значения W_hh обычно < 1. Через 50 шагов: 0.9⁵⁰ ≈ 0.005 — градиент практически исчезает.
Градиент от h_T до h_1 — произведение T−1 матриц. Если спектральная норма каждого множителя < 1, произведение → 0 (vanishing). Если > 1 — → ∞ (exploding)
Два сценария: • Vanishing gradients (затухание): модель не может обучиться длинным зависимостям. Ранние слова не получают сигнала об ошибке. Это основная проблема. • Exploding gradients (взрыв): градиенты растут экспоненциально, веса «прыгают». Решается просто — gradient clipping (обрезка нормы). А вот vanishing gradient clipping не поможет — нечего обрезать, сигнала нет. На практике vanilla RNN помнит 10-20 токенов. Для одного предложения хватает, для абзаца — уже нет.
Частый вопрос на собесе
LSTM — долгая кратковременная память
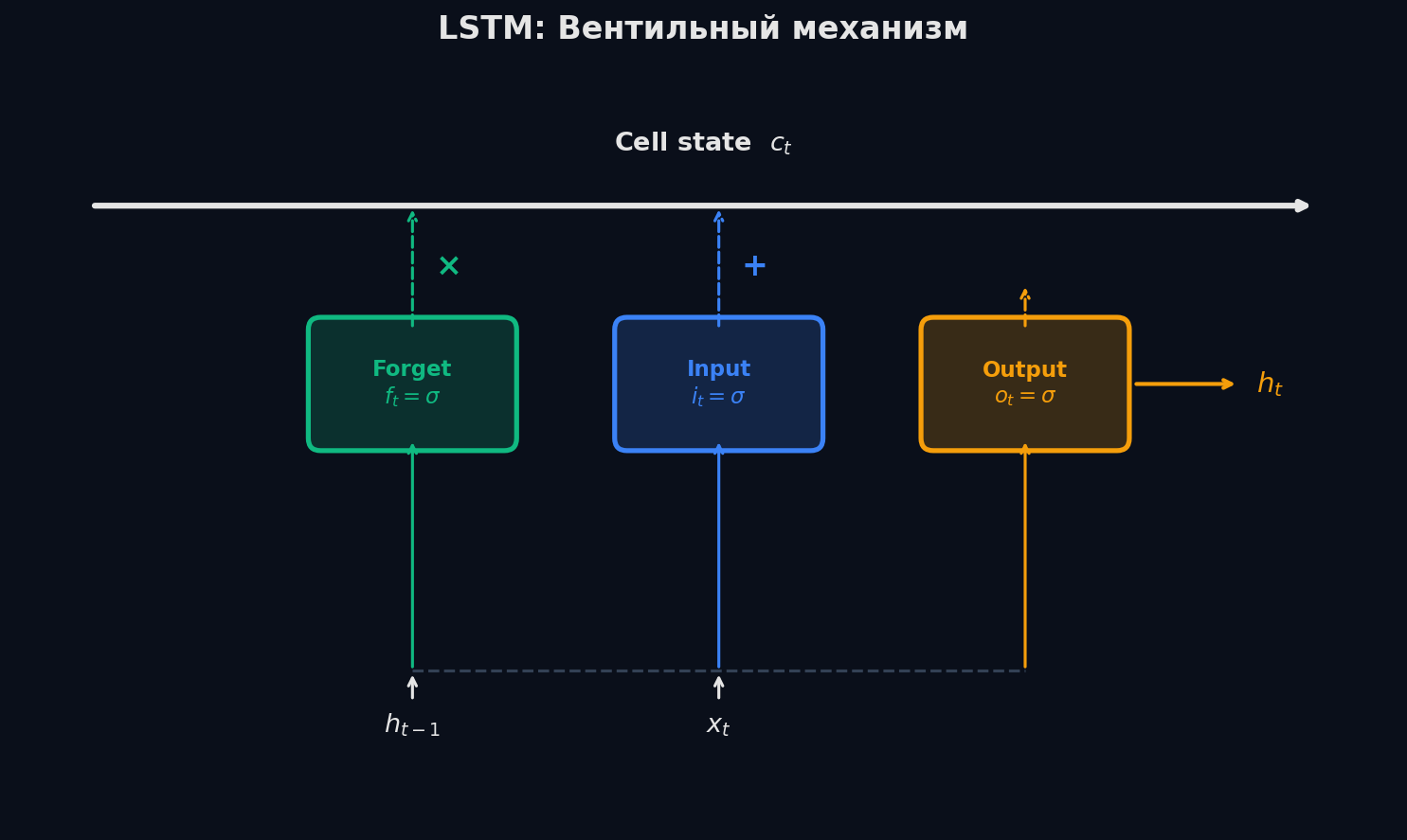
LSTM (Long Short-Term Memory, 1997) — архитектура, созданная специально для решения проблемы vanishing gradients. Ключевая идея: добавить отдельную ячейку памяти (cell state, C_t), через которую информация может проходить без изменений на протяжении многих шагов.
Аналогия: cell state — конвейерная лента на заводе. По ней едут детали (информация), и она идёт прямо, без поворотов. Рядом стоят трое рабочих (гейты): • Forget gate (забыть): решает, какие детали убрать с ленты. «Этот факт больше не нужен — выбрасываем» • Input gate (запомнить): решает, какие новые детали положить на ленту. «Это важный факт — кладём» • Output gate (отдать): решает, какую часть содержимого ленты показать на текущем шаге. «Вот что релевантно прямо сейчас»





Формулы LSTM: что делает каждый гейт
Все гейты имеют одинаковую структуру: линейная комбинация [h_{t−1}, x_t] → сигмоида (σ). Сигмоида выдаёт значение от 0 до 1 — это «степень открытия» гейта.
Forget gate: f_t ∈ [0, 1]. Значение 0 = «забудь всё», 1 = «помни всё». На практике обычно 0.9-0.99 — почти всё помнит
Input gate (i_t) + кандидат на запись (C̃_t). i_t решает, сколько записать, C̃_t — что именно записать
Обновление cell state: старая память × forget gate + новая информация × input gate. Символ ⊙ — поэлементное умножение
Output gate (o_t) фильтрует cell state → скрытое состояние h_t, которое идёт на выход и на следующий шаг
Числовой пример: LSTM по шагам
Представим: модель читает предложение и на позиции «Мария» забирает факт «субъект = женский род». Через 10 слов встречает глагол и должна выбрать правильное окончание. Упростим до конкретных чисел (скаляры вместо векторов для ясности):
# Упрощённый пример: скалярный LSTM
import numpy as np
def sigmoid(x): return 1 / (1 + np.exp(-x))
# Состояние после прочтения "Мария":
C_prev = 0.9 # cell state хранит "субъект = жен. род" (высокое значение)
h_prev = 0.7 # скрытое состояние
# Теперь читаем 5 "неважных" слов ("которая родилась в Париже и")
# Для каждого: forget gate ≈ 0.95 (почти всё помним), input gate ≈ 0.1 (мало нового)
C = C_prev
for step in range(5):
f_t = 0.95 # forget gate: помним почти всё
i_t = 0.1 # input gate: мало нового
C_cand = 0.2 # кандидат: слабый сигнал
C = f_t * C + i_t * C_cand # обновляем cell state
print(f"Шаг {step+1}: C = {C:.3f}")
# Шаг 1: C = 0.875
# Шаг 2: C = 0.851
# Шаг 3: C = 0.829
# Шаг 4: C = 0.807
# Шаг 5: C = 0.787
# Через 5 шагов C = 0.787 — всё ещё высокое! (было 0.9)
# В vanilla RNN: h * 0.8^5 = 0.9 * 0.328 = 0.295 — почти потеряно
# Теперь встречаем глагол — output gate открывается:
o_t = 0.9 # output gate: "сейчас это важно!"
h_t = o_t * np.tanh(C) # h_t = 0.9 * tanh(0.787) = 0.9 * 0.655 = 0.590
print(f"\nНа глаголе: h_t = {h_t:.3f} — информация о 'Мария' сохранилась!")Ключевой момент: cell state сохранил 87% информации (0.787 / 0.9) через 5 шагов, тогда как vanilla RNN потерял бы ~67%. На 50 шагах разница драматическая: LSTM с f_t = 0.95 сохранит 0.95⁵⁰ ≈ 7.7% (достаточно для сигнала), а RNN с множителем 0.8 — 0.8⁵⁰ ≈ 0.001% (полная потеря).
Почему LSTM решает vanishing gradient?
GRU — упрощённый LSTM
GRU (Gated Recurrent Unit, 2014) — упрощённая версия LSTM. Основные отличия: • 2 гейта вместо 3: update gate (z_t) объединяет роли forget и input, reset gate (r_t) контролирует, сколько прошлой памяти использовать при вычислении кандидата • Нет отдельного cell state — только скрытое состояние h_t • Меньше параметров — быстрее обучается, меньше переобучается на малых данных
z_t — update gate (что оставить от старого vs взять от нового), r_t — reset gate (сколько прошлого использовать для кандидата)
Скрытое состояние — взвешенная смесь: (1−z_t) × старое + z_t × новое. Если z_t ≈ 0, информация проходит без изменений
LSTM vs GRU — когда что выбирать? • Данных много + последовательности длинные → LSTM (отдельный cell state лучше хранит долгосрочную память) • Данных мало + нужна скорость → GRU (меньше параметров, быстрее обучается) • На практике разница в качестве часто незначительна. Cho et al. (2014) и множество сравнений показали: ни одна архитектура не доминирует всегда. Дефолтный выбор для новой задачи — GRU, если нет причин для LSTM.
Bidirectional RNN — читаем в обе стороны
Обычная RNN читает слева направо: для слова на позиции t она знает только контекст слева [x₁, …, x_t]. Но часто контекст справа не менее важен.
Пример: «Я пошёл в банк, чтобы снять деньги» vs «Я сел на банк у реки». Значение слова «банк» определяется тем, что идёт после него. Однонаправленная RNN, дойдя до «банк», ещё не видела «деньги» или «реки» — и не может разрешить неоднозначность.
BiLSTM (Bidirectional LSTM) запускает два LSTM параллельно: один читает слева направо (→), другой — справа налево (←). На каждой позиции их скрытые состояния конкатенируются: h_t = [h_t→ ; h_t←]. Теперь каждый токен имеет полный контекст предложения.
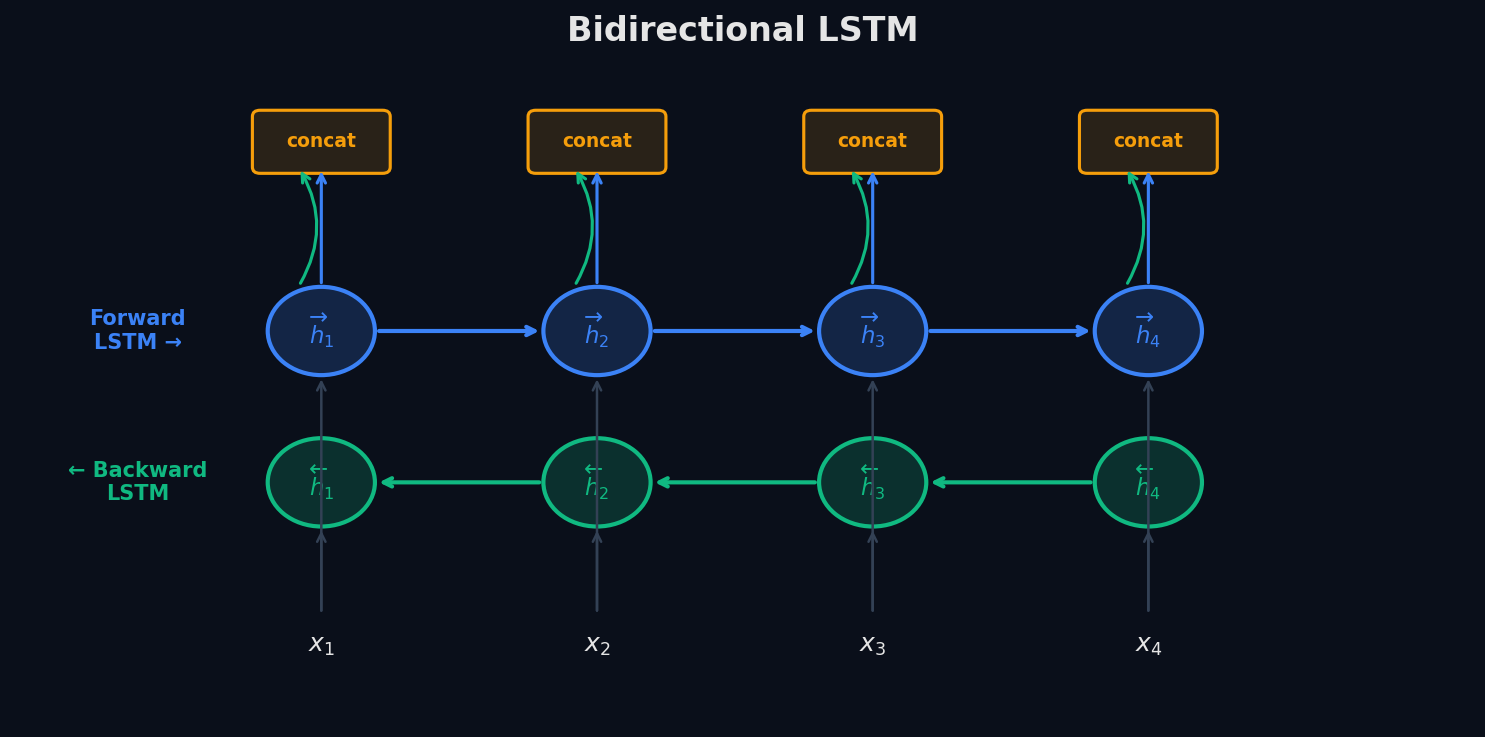
⚠️ Важное ограничение: BiLSTM нельзя использовать для генерации текста (авторегрессионные задачи). Если модель генерирует слово за словом, она не может «подсмотреть» в будущее — будущее ещё не создано. BiLSTM — для задач понимания: NER, PoS-tagging, классификация предложений, экстракция отношений.
Почему трансформер победил RNN
К 2018-2019 годам трансформеры практически вытеснили RNN из NLP. Две главные причины:
- Параллелизм. RNN обрабатывает токены строго последовательно: нельзя вычислить h_5, пока не готов h_4. Трансформер обрабатывает все токены одновременно — self-attention параллелится идеально. На GPU с тысячами ядер это разница в порядки: обучение GPT-3 на RNN заняло бы годы вместо месяцев.
- Длинные зависимости. В RNN сигнал от первого слова до сотого проходит 99 шагов, затухая на каждом. В трансформере — один шаг attention, прямое соединение между любыми двумя токенами. Информация не теряется, даже если зависимость длиной в тысячи токенов.
Есть и третья причина, менее очевидная: масштабируемость. Трансформеры идеально ложатся на кластеры GPU, и scaling laws показали: чем больше модель и данных — тем лучше. RNN масштабировать значительно сложнее из-за последовательной природы.
Где RNN ещё живы
Несмотря на доминирование трансформеров, RNN не исчезли полностью. Есть ниши, где их свойства — преимущество:
- Edge-устройства (телефоны, IoT). LSTM с 256 скрытых размерностей — ~500K параметров, помещается в 2 МБ. Для клавиатурного предиктора или детектора wake word ("Окей, Гугл") это идеально. Трансформер — избыточен.
- Стриминговые задачи. ASR (распознавание речи) в реальном времени: аудио приходит чанками, нужно выдавать транскрипцию с минимальной задержкой. RNN обрабатывает чанк и обновляет состояние — O(1) на токен. Трансформер пересчитывает attention по всей истории — O(n) или нужен KV-cache.
- Управление роботами. Принятие решений в реальном времени: простая RNN с частотой 100+ Hz на микроконтроллере. Трансформер не влезает.
- Гибридные модели. xLSTM (2024), Mamba (selective state spaces) — переосмысление идей RNN с линейной сложностью и конкурентным качеством для длинных контекстов.
Практический пример: LSTM на PyTorch
import torch
import torch.nn as nn
# Двуслойный BiLSTM для классификации текста
class TextClassifier(nn.Module):
def __init__(self, vocab_size, emb_dim=128, hidden_dim=64, num_classes=3):
super().__init__()
self.emb = nn.Embedding(vocab_size, emb_dim)
self.lstm = nn.LSTM(
input_size=emb_dim,
hidden_size=hidden_dim,
num_layers=2,
bidirectional=True, # BiLSTM
batch_first=True,
dropout=0.3, # dropout между слоями
)
# hidden_dim * 2 из-за bidirectional
self.fc = nn.Linear(hidden_dim * 2, num_classes)
def forward(self, x):
# x: [batch, seq_len] — id токенов
emb = self.emb(x) # [batch, seq_len, emb_dim]
output, (h_n, c_n) = self.lstm(emb) # output: [batch, seq_len, hidden*2]
# Берём последние hidden states обоих направлений
# h_n: [num_layers*2, batch, hidden]
h_forward = h_n[-2] # последний слой, прямое направление
h_backward = h_n[-1] # последний слой, обратное направление
h_cat = torch.cat([h_forward, h_backward], dim=-1) # [batch, hidden*2]
return self.fc(h_cat) # [batch, num_classes]
# Пример использования
model = TextClassifier(vocab_size=10000)
tokens = torch.randint(0, 10000, (4, 50)) # батч из 4 текстов по 50 токенов
logits = model(tokens)
print(logits.shape) # torch.Size([4, 3])🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
RNN — первая архитектура, которая дала нейросетям память. Vanilla RNN передаёт скрытое состояние с шага на шаг, но из-за vanishing gradients забывает длинные зависимости. LSTM решает это с помощью cell state (конвейерная лента для долгосрочной памяти) и трёх гейтов (forget, input, output), которые контролируют поток информации. GRU — упрощённая версия с двумя гейтами и сравнимым качеством. BiLSTM добавляет контекст справа, но только для задач понимания.
Если запомнить одну вещь из этой ноды: LSTM хранит долгосрочную память в cell state, а гейты решают, что забыть, что записать и что показать. Именно поэтому LSTM может обучиться зависимостям на сотнях шагов, где vanilla RNN бессильна.
Дальше на роадмапе: Seq2Seq и Attention — как LSTM стали основой для машинного перевода и как attention механизм позволил решить проблему «бутылочного горлышка» энкодера. А затем Transformer — архитектура, которая заменила RNN, взяв лучшее от attention и выбросив рекуррентность.
Материалы
Легендарный пост с визуализациями гейтов LSTM. Лучшее объяснение в интернете — с него стоит начать.
RNN/LSTM в контексте seq2seq задач. Отличные интерактивные иллюстрации.
Пошаговое визуальное объяснение LSTM. Идеально для первого знакомства.
Классический пост: RNN генерирует Shakespeare, код на C, LaTeX. Показывает мощь и красоту рекуррентных сетей.
Официальная документация с описанием параметров и формул.