Transformer
Self-attention, multi-head attention, positional encoding — архитектура, изменившая NLP.
Transformer — архитектура, которая изменила всё
До 2017 года нейросети читали текст последовательно — слово за словом, как человек читает книгу. RNN и LSTM справлялись с короткими фразами, но на длинных текстах «забывали» начало, пока добирались до конца. А ещё их невозможно было эффективно параллелить: пока не обработаешь слово 3, нельзя начать слово 4.
Transformer решает обе проблемы радикально: он обрабатывает все слова одновременно. Вместо последовательного чтения — каждый токен «смотрит» на все остальные и решает, кто ему важен. Это механизм self-attention (самовнимание), и именно он стал фундаментом для всех современных языковых моделей — от BERT до GPT.
Статья «Attention Is All You Need» (2017) — одна из самых цитируемых в истории ML. Идея оказалась настолько мощной, что трансформеры захватили не только NLP, но и компьютерное зрение (ViT), рекомендации (SASRec), аудио (Whisper) и даже биологию (AlphaFold).
Большая картина: что происходит от входа до выхода
Прежде чем углубляться в детали, посмотрим на трансформер целиком — как «чёрный ящик». Оригинальная архитектура состоит из двух частей: энкодер (encoder) и декодер (decoder).
Аналогия: представь переводчика-синхрониста. Сначала он слушает всё предложение на исходном языке и строит у себя в голове полное понимание смысла — это энкодер. Затем он проговаривает перевод слово за словом, каждый раз обращаясь к своему пониманию оригинала — это декодер.
Вот путь одного предложения через трансформер за 5 шагов: Шаг 1. Токенизация + эмбеддинги. Текст разбивается на токены (слова или части слов). Каждый токен превращается в числовой вектор — эмбеддинг. Шаг 2. Позиционное кодирование. К эмбеддингу добавляется информация о позиции токена в предложении (потому что attention сам по себе не знает порядок слов). Шаг 3. Энкодер (N слоёв). Токены проходят через стопку одинаковых слоёв. В каждом слое: self-attention (токены «смотрят» друг на друга) → Feed-Forward сеть (обработка информации). Между ними — residual connections и нормализация. Шаг 4. Декодер (N слоёв). Генерация выхода токен за токеном. Каждый слой декодера делает три вещи: masked self-attention (смотрит только на уже сгенерированные токены) → cross-attention (обращается к выходу энкодера) → Feed-Forward сеть. Шаг 5. Выходной слой. Линейная проекция + softmax — получаем вероятности для следующего токена.
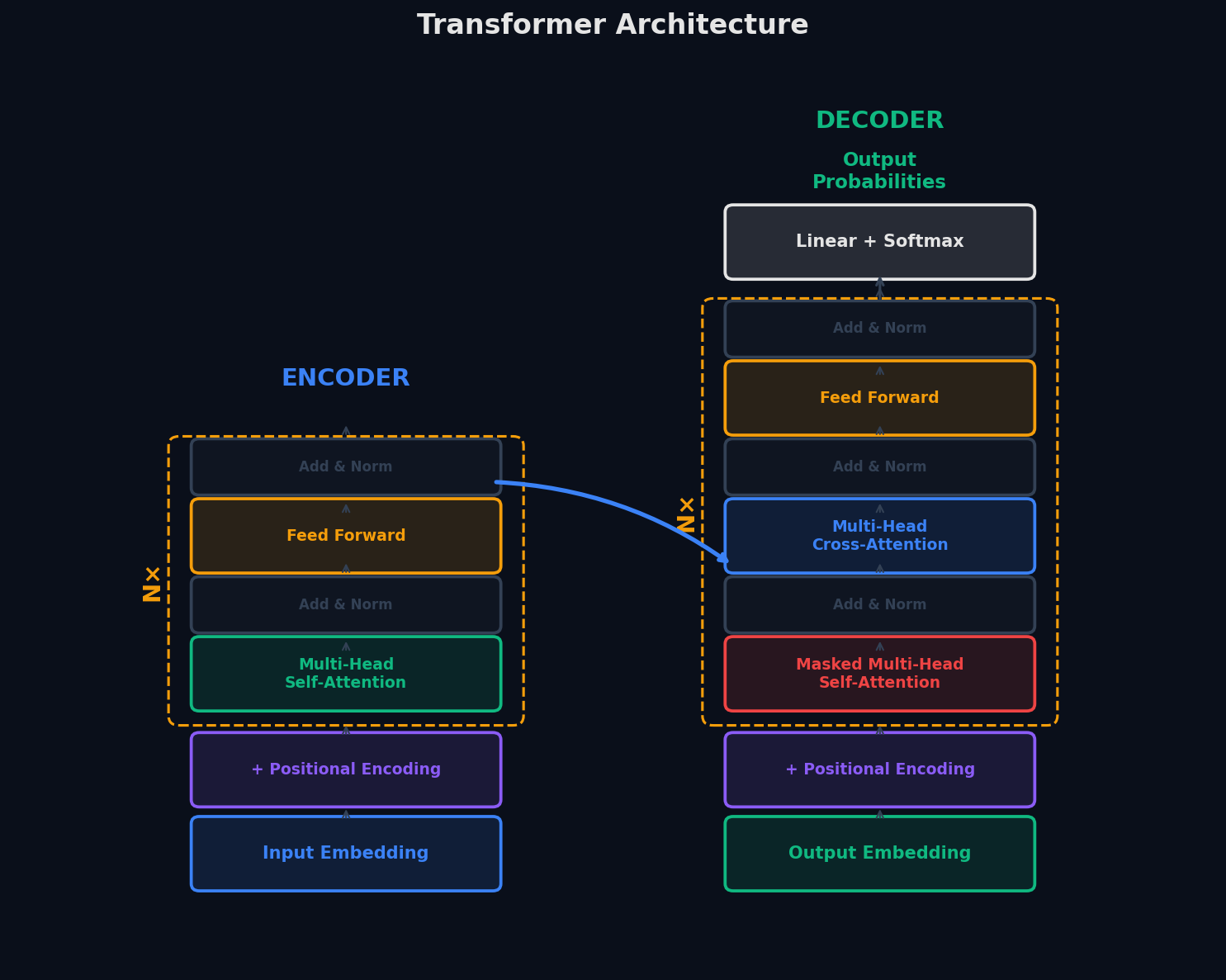

Три варианта трансформера
Self-Attention: как токены «разговаривают» друг с другом
Self-attention — ключевой механизм трансформера. Его задача: для каждого токена собрать релевантную информацию из всех остальных токенов в предложении.
Аналогия: ты на совещании, и каждый участник по очереди «обновляет» своё понимание задачи. Ты слушаешь всех, но не одинаково — на финансового директора обращаешь внимание, когда речь о бюджете, а на дизайнера — когда о макете. Self-attention делает то же: каждый токен оценивает «релевантность» каждого другого токена к себе и забирает у них информацию пропорционально этой релевантности.
Query, Key, Value — три роли каждого токена
Чтобы реализовать этот механизм, каждый токен получает три представления (три вектора), образованных умножением его эмбеддинга на три обучаемых матрицы: • Query (Q — запрос): «Что я ищу? Какая информация мне нужна?» • Key (K — ключ): «Что я могу предложить? Какая информация у меня есть?» • Value (V — значение): «Вот моя информация — забирай» Внимание между двумя токенами — это совместимость Query одного с Key другого. Чем выше совместимость, тем больше Value этого токена попадёт в результат.
Аналогия с библиотекой: ты приходишь с запросом (Query) — «мне нужна книга про нейросети». Каждая книга на полке имеет ярлык (Key) — «машинное обучение», «кулинария», «история». Ты сравниваешь запрос с каждым ярлыком и берёшь содержание (Value) тех книг, чьи ярлыки совпали с запросом.
Загрузка интерактивного виджета...

Формула Scaled Dot-Product Attention
Теперь запишем это математически. Алгоритм за 4 шага: 1. Вычисляем скоры: скалярное произведение Query и Key — QK^T. Получаем матрицу N×N (N — длина последовательности), где каждая ячейка — «похожесть» двух токенов. 2. Масштабируем: делим на √d_k (корень из размерности ключей). Зачем — объясняем ниже. 3. Softmax: превращаем скоры в вероятности (сумма по строке = 1). 4. Взвешенная сумма: умножаем на V — каждый токен получает смесь значений других токенов, пропорционально их весам.
Q — матрица запросов (N×d_k), K — матрица ключей (N×d_k), V — матрица значений (N×d_v), d_k — размерность ключей
Зачем делить на √d_k?
import torch
import torch.nn.functional as F
# Q, K, V: [batch, seq_len, d_k]
scores = Q @ K.transpose(-2, -1) / (Q.size(-1) ** 0.5) # [batch, seq_len, seq_len]
attn_weights = F.softmax(scores, dim=-1) # каждая строка — распределение
output = attn_weights @ V # [batch, seq_len, d_v]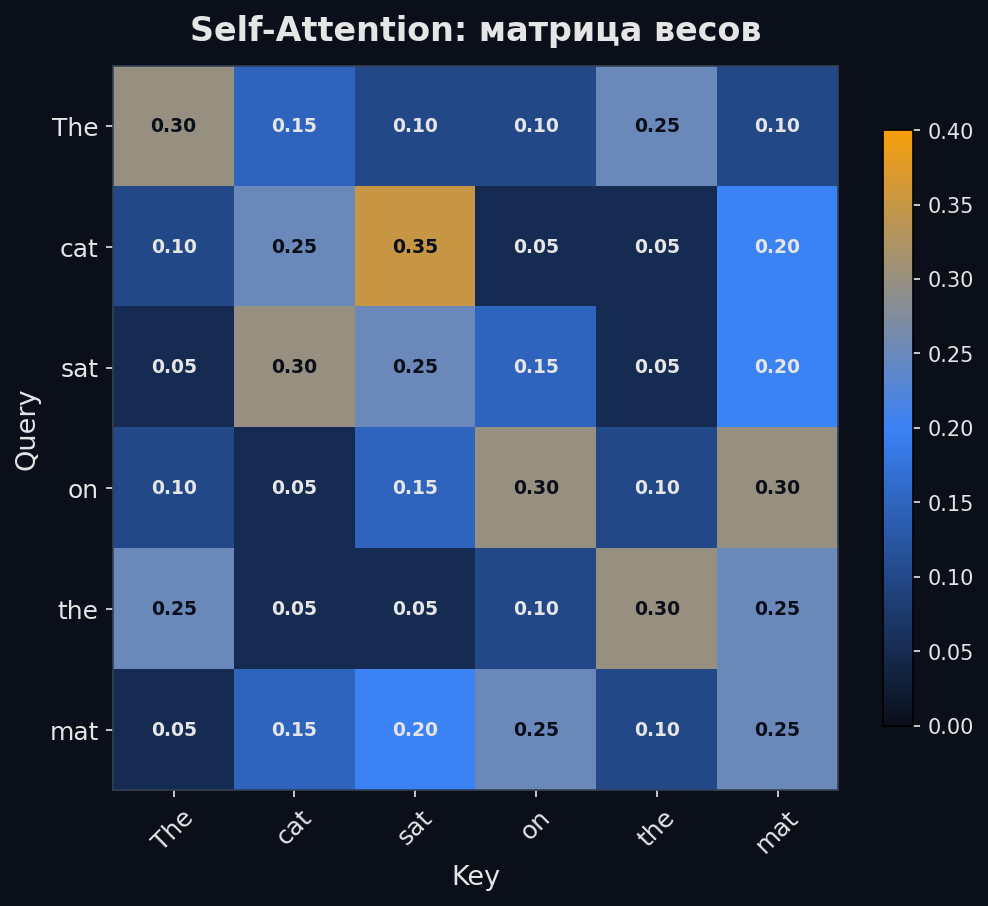
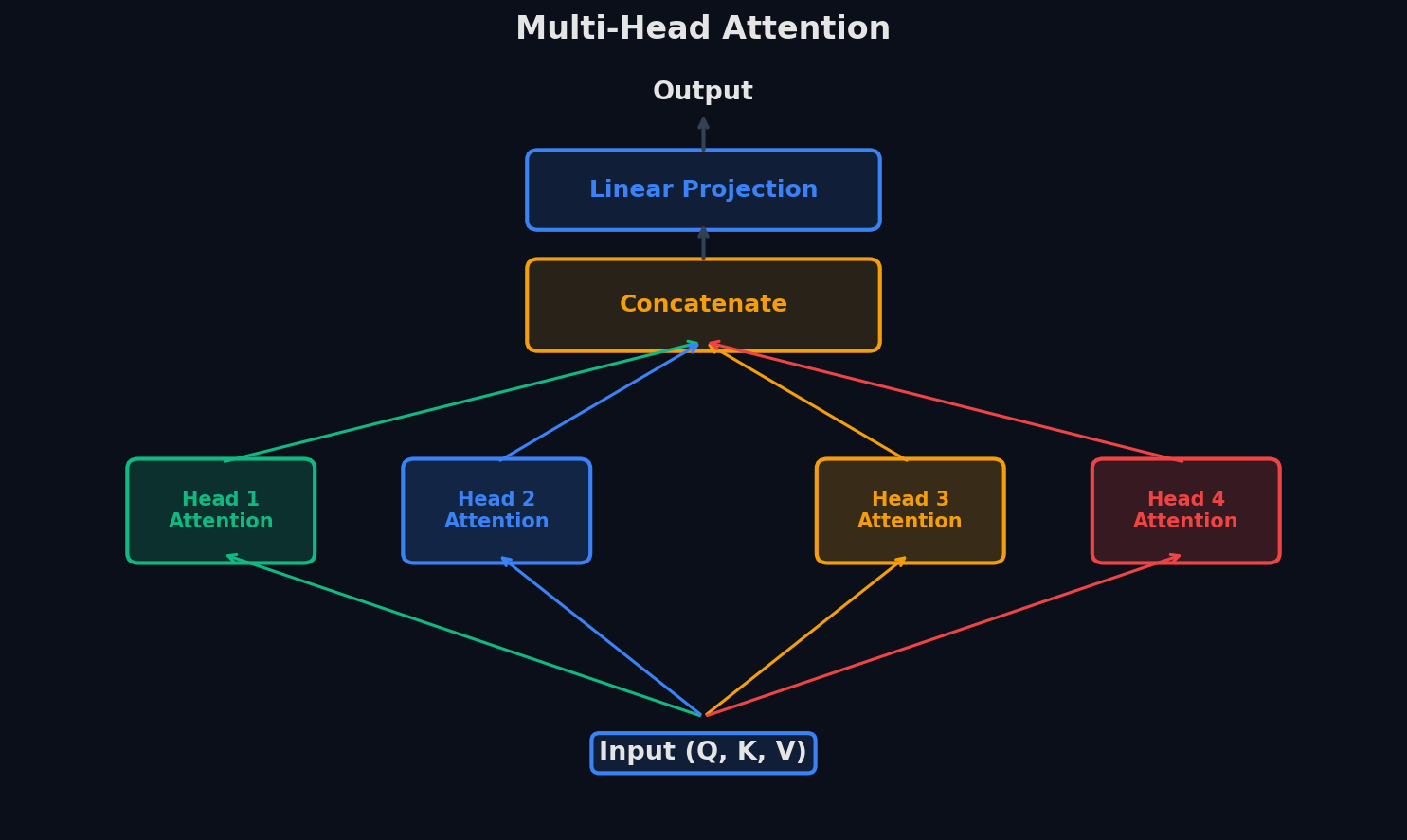
Multi-Head Attention — несколько взглядов одновременно
Одна «голова» attention ловит один тип зависимости — например, синтаксическую связь между подлежащим и сказуемым. Но в языке одновременно есть и синтаксис, и семантика, и кореференция («он» → кто именно?), и позиционные паттерны.
Multi-Head Attention решает это элегантно: вместо одного attention с d_model-мерными Q, K, V запускаем h голов параллельно, каждая с размерностью d_k = d_model/h. У каждой головы свои обучаемые матрицы W_Q, W_K, W_V — значит, каждая учится фокусироваться на своём. Результаты всех голов конкатенируются и проецируются обратно в d_model.
Пример: d_model = 512, h = 8 голов → каждая работает с d_k = 64. Вычислительная стоимость — та же, что у одной головы с d_k = 512, но модель может одновременно отслеживать 8 разных типов связей.
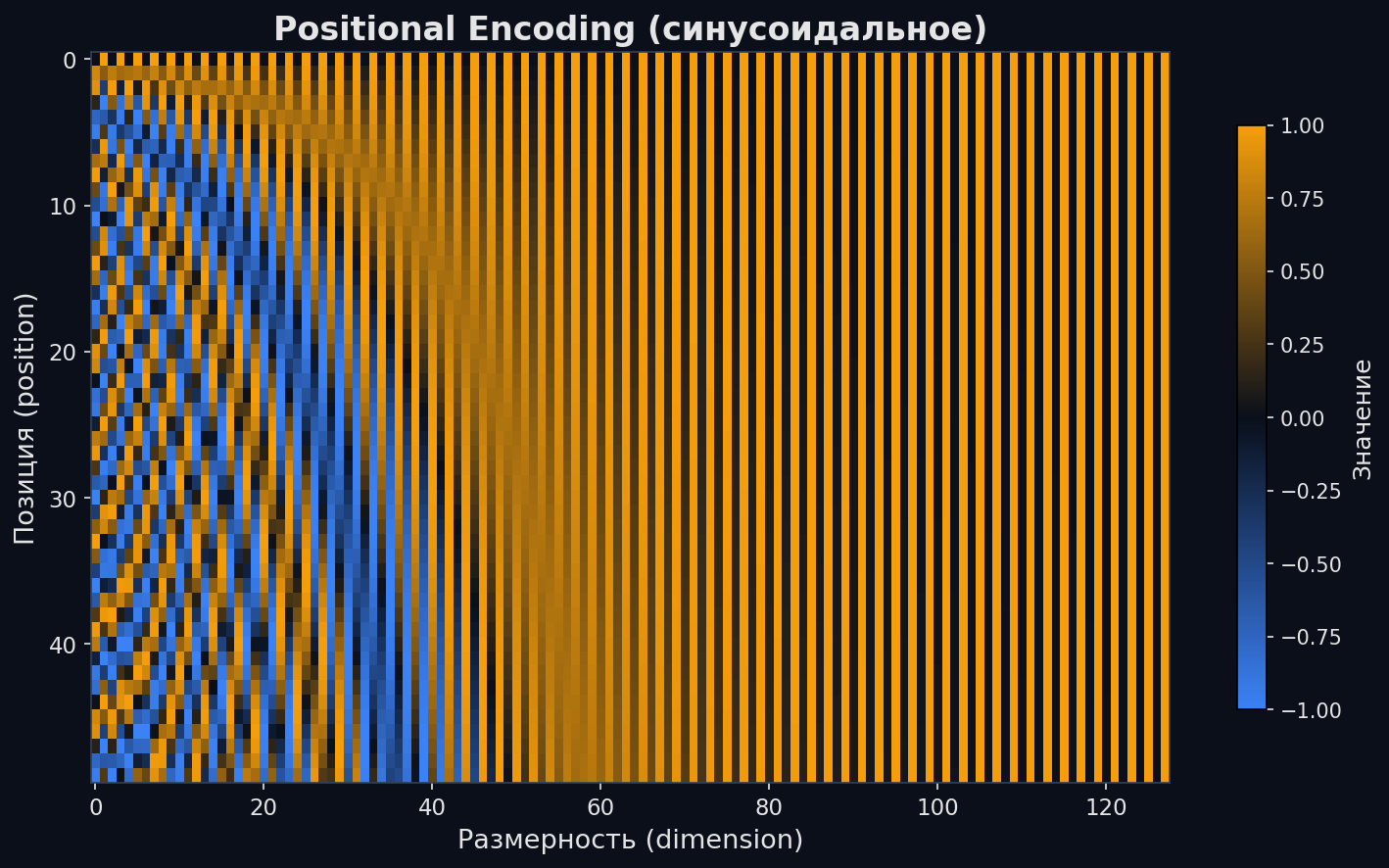
Positional Encoding — как трансформер узнаёт порядок слов
У self-attention есть неожиданная проблема: он работает с множеством, а не с последовательностью. Если перемешать токены местами, результат attention не изменится — операция симметрична. Но порядок слов критичен: «кот съел рыбу» ≠ «рыба съела кота».
Positional Encoding решает это: к эмбеддингу каждого токена прибавляется вектор, кодирующий его позицию. В оригинальном трансформере используется синусоидальное кодирование — чередование sin и cos разных частот. Каждая позиция получает уникальный паттерн, и модель может различать «первый токен» от «пятого».
pos — позиция токена в последовательности, i — индекс в векторе эмбеддинга, d — размерность эмбеддинга. Разные частоты позволяют кодировать и близкие, и далёкие позиции
Почему именно синусоиды? Авторы заметили, что относительную позицию можно выразить как линейную функцию от абсолютной (PE_{pos+k} — линейная комбинация PE_{pos}). Это позволяет модели обобщаться на длины, не встречавшиеся при обучении. Современные модели часто используют обучаемые позиционные эмбеддинги или RoPE (Rotary Position Embedding), но принцип тот же — нужно явно сообщить модели, где какой токен стоит.
Feed-Forward, Residual Connections и Layer Norm — «скелет» трансформера
Self-attention — это «коммуникация» между токенами. Но после того как токен собрал информацию от соседей, ему нужно обработать её. Для этого в каждом слое после attention стоит Feed-Forward Network (FFN) — два линейных слоя с нелинейностью между ними.
Аналогия: attention — это совещание, где ты собрал мнения коллег. FFN — это момент после совещания, когда ты сидишь за столом и обдумываешь услышанное, принимаешь решения.
W₁ расширяет вектор из d_model до 4·d_model (внутренняя размерность), W₂ сжимает обратно. ReLU — нелинейная активация
Residual connections (остаточные связи) — простой, но критически важный приём. Вместо output = sublayer(x) используется output = sublayer(x) + x. Вход «пролетает» мимо подслоя и складывается с его результатом. Зачем? Трансформер глубокий (6-96 слоёв), и без skip-connections градиенты затухают — модель не обучается.
Аналогия: ты правишь текст. Вместо переписывания с нуля берёшь оригинал и добавляешь правки — если правка плохая, оригинал остаётся.
Layer Normalization нормализует активации внутри каждого токена (по размерности d_model). В отличие от Batch Norm, который нормализует по батчу, LayerNorm работает с одним примером — это удобно для последовательностей разной длины. LayerNorm стабилизирует обучение и ускоряет сходимость.
Итого, один слой трансформера (один «блок») выглядит так:
``
x → [Multi-Head Attention] → Add(x, ·) → LayerNorm → [FFN] → Add(·, ·) → LayerNorm → out
``
Этих блоков в стандартном трансформере 6 (в энкодере) и 6 (в декодере). Современные LLM используют 32-128 слоёв.

Forward Pass: как токен проходит через трансформер (end-to-end)
Проследим конкретный путь. Допустим, мы переводим «The cat sat» с английского на другой язык с трансформером encoder-decoder.
Энкодер: 1. Токенизация: ["The", "cat", "sat"] → три ID в словаре 2. Эмбеддинги: каждый ID → вектор размерности d_model=512 3. + Positional Encoding: к каждому вектору прибавляем позиционный вектор 4. Слой 1: — Self-attention: каждый из 3 токенов вычисляет Q, K, V. Токен «sat» обращает внимание на «cat» (кто сидел?) — получает высокий вес. Результат — новое представление каждого токена, обогащённое контекстом. — Add & Norm: складываем с входом (residual), нормализуем — FFN: обрабатываем каждый токен индивидуально — Add & Norm 5. Слои 2-6: повторяем. С каждым слоем представления токенов становятся всё более «контекстуальными» — токен «cat» несёт информацию не только о себе, но и обо всём предложении.
Декодер (генерация токен за токеном): 1. Начинаем с токена [START] 2. Слой 1 декодера: — Masked self-attention: [START] смотрит только на себя (causal mask — будущее закрыто) — Cross-attention: Query из декодера, Key и Value — из выхода энкодера. Так декодер «читает» исходное предложение — FFN 3. Слои 2-6 декодера: повторяем 4. Выходной слой: линейная проекция d_model → |vocab|, softmax → распределение вероятностей 5. Выбираем токен с наибольшей вероятностью (или beam search) → например, первый токен перевода 6. Добавляем сгенерированный токен ко входу декодера, повторяем до токена [END]
Загрузка интерактивного виджета...
Causal Mask — запрет подглядывать в будущее
Pre-Norm vs Post-Norm — куда ставить нормализацию
В оригинальном трансформере нормализация стоит после residual connection (Post-Norm): x → Attention → Add(x, ·) → LayerNorm. Современные LLM (GPT-3, LLaMA, Mistral) используют Pre-Norm: нормализация перед подслоем: x → LayerNorm → Attention → Add(x, ·).
Почему Pre-Norm стабильнее? В Post-Norm градиенты проходят через LayerNorm на residual path — нормализация «сжимает» их, и при глубоких сетях (64-128 слоёв) они затухают. В Pre-Norm residual path чистый: output = x + Attention(LayerNorm(x)). Градиент по x проходит «мимо» нормализации и attention, как скоростная магистраль — прямой gradient highway, аналогичный ResNet.
Ещё одна деталь: современные модели заменяют LayerNorm на RMSNorm — упрощённую версию, которая не вычитает среднее, а только нормализует по RMS (root mean square). Это на 10-15% быстрее при том же качестве.
Ограничения трансформера
O(n²) по памяти и вычислениям. Self-attention считает попарные связи всех n токенов — матрица N×N. При n=1000 это 1 млн ячеек, при n=100 000 — 10 млрд. Для длинных текстов это проблема: и по памяти, и по скорости.
Контекстное окно. Из-за квадратичной сложности у каждой модели есть ограничение на длину входа: 512 токенов в оригинальном трансформере, 4K-8K в ранних GPT, 128K-1M в современных моделях. Всё, что не влезает — модель не видит.
Решения (кратко): • FlashAttention — IO-aware реализация: тот же результат, но без материализации N×N матрицы в памяти GPU. В 2-4× быстрее. • Sliding Window Attention — каждый токен видит только w ближайших соседей. Сложность O(n·w) вместо O(n²). • GQA (Grouped Query Attention) — несколько Q-голов делят одну пару K/V, экономя KV-cache. • Линейный attention, SSM (Mamba) — альтернативные архитектуры с O(n) сложностью. Подробнее — в ноде «Современные архитектуры LLM».
Почему трансформеры победили RNN
- Параллелизм. RNN обрабатывает токены последовательно (нельзя начать шаг 4, пока не закончен шаг 3). Трансформер — все токены одновременно. На GPU это разница в порядки.
- Прямой доступ к любому токену. В RNN сигнал от первого слова до последнего проходит n шагов, затухая. В трансформере — один шаг attention, прямая связь между любыми двумя токенами.
- Масштабируемость. Трансформеры идеально ложатся на кластеры GPU. Scaling laws показывают: чем больше модель и данных — тем лучше качество. Это привело к взрывному росту LLM.
- Цена. Квадратичная сложность O(n²) по длине последовательности — главный компромисс.
Практический пример: минимальный Transformer block на PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerBlock(nn.Module):
"""Один блок трансформера (Pre-Norm, как в современных LLM)."""
def __init__(self, d_model: int = 512, n_heads: int = 8, d_ff: int = 2048):
super().__init__()
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.attn = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model),
)
def forward(self, x, mask=None):
# Pre-Norm: нормализуем ДО подслоя
h = self.norm1(x)
h = x + self.attn(h, h, h, attn_mask=mask)[0] # residual
out = h + self.ffn(self.norm2(h)) # residual
return out
# Пример: батч из 2 последовательностей по 10 токенов, d_model=512
block = TransformerBlock()
x = torch.randn(2, 10, 512)
out = block(x)
print(out.shape) # torch.Size([2, 10, 512])🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Трансформер — это архитектура, построенная на одной идее: вместо последовательной обработки пусть каждый токен сразу видит все остальные. Self-attention вычисляет, на кого обратить внимание (Q·K^T → softmax → ×V). Multi-Head позволяет смотреть «с разных углов». Positional Encoding добавляет порядок. FFN обрабатывает собранную информацию. Residual connections и LayerNorm позволяют строить глубокие сети.
Если запомнить одну вещь из этой ноды: трансформер = self-attention + позиционное кодирование + FFN, повторённые N раз с residual connections. Всё остальное — вариации и оптимизации этой базовой идеи.
Дальше на роадмапе: BERT использует только энкодер для задач понимания, GPT использует только декодер для генерации, а современные архитектуры LLM расскажут, как решают проблему O(n²) и масштабируют трансформеры до сотен миллиардов параметров.
Материалы
Лучшая визуальная статья про трансформер. Обязательна к прочтению.
Пошаговое объяснение attention от seq2seq к трансформеру с интерактивными визуализациями.
Визуальное объяснение self-attention от 3Blue1Brown. Отличные анимации.
Оригинальная статья 2017 года. Читается за вечер, формулы простые.
Построчная реализация трансформера на PyTorch с подробными комментариями.