GPT и авторегрессионные модели
GPT-1/2/3/4, scaling laws, emergent abilities, in-context learning.
GPT — генеративный трансформер, который научился думать текстом
Загрузка интерактивного виджета...
BERT читает текст в обе стороны и отлично понимает — но генерировать не умеет. GPT (Generative Pre-trained Transformer) — это decoder-only трансформер, обученный на одной задаче: предсказывай следующий токен. Одна простая задача, масштабированная до сотен миллиардов параметров, привела к ChatGPT и целой революции в AI.
Аналогия: представь автозаполнение в телефоне, но возведённое в абсолют. Ты набрал «Объясни квантовую механику простыми словами» — и модель токен за токеном достраивает ответ, каждый раз выбирая наиболее вероятное продолжение с учётом всего предыдущего контекста. Это и есть авторегрессионная генерация (autoregressive generation): сгенерировал токен → добавил к контексту → сгенерировал следующий → повторил.
История GPT — это не история архитектурных прорывов (архитектура почти не менялась с 2018 года). Это история масштабирования: больше параметров, больше данных, больше compute — и внезапно модель начинает решать задачи, которым её никто не учил.
Большая картина: от pretrain до emergent abilities
GPT обучается в два этапа. Сначала pre-training на гигантском корпусе текста (вся Википедия, книги, код, форумы — сотни миллиардов токенов). Задача одна: предсказать следующий токен. Никаких меток, никакой разметки — модель учит статистическую структуру языка, а заодно фактические знания, логику, стиль.
Второй этап — alignment (выравнивание с намерениями пользователя). Pre-trained модель хорошо продолжает текст, но не умеет «быть ассистентом». RLHF или DPO учат модель быть полезной, честной и безопасной (подробнее — ниже).
Самое удивительное: при достаточном масштабе возникают эмерджентные способности (emergent abilities) — навыки, которым модель не учили напрямую. Модель на 10B параметров не решает арифметику — а на 100B вдруг решает. Не постепенное улучшение, а скачок. Chain-of-thought reasoning, программирование, перевод, суммаризация — всё это «бесплатные бонусы» масштабирования.
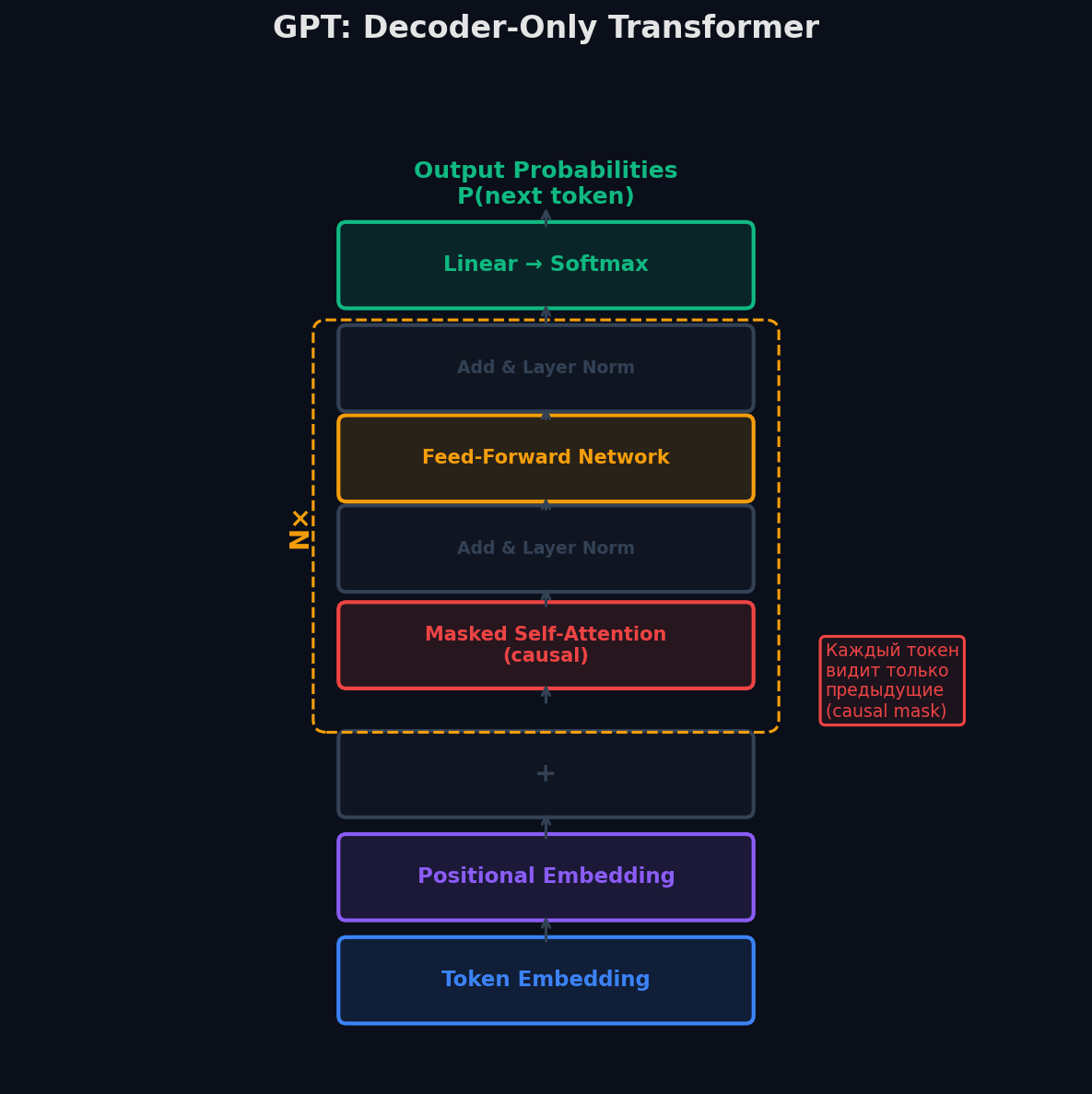
Архитектура: decoder-only и causal mask
Оригинальный трансформер состоит из энкодера и декодера. GPT использует только декодер — без энкодера и без cross-attention. Почему?
Задача GPT — генерация. При генерации нет «исходного предложения», которое нужно понять (как при переводе) — есть только текст, который нужно продолжить. Энкодер здесь просто не нужен. А decoder-only архитектура элегантно унифицирует обучение и генерацию: и при train, и при inference модель делает одно и то же — читает токены слева направо и предсказывает следующий.
Causal mask (причинная маска) — ключевой элемент. Это нижнетреугольная матрица, которая гарантирует: токен на позиции i видит только токены 0, 1, …, i−1. Будущее закрыто. Маска заполняется значениями −∞ (не нулями!), потому что softmax(−∞) = 0 — полная блокировка, а softmax(0) ≠ 0 — утечка информации.
При обучении все позиции считаются параллельно — это называется teacher forcing. Для предложения из 1000 токенов модель за один forward pass получает 1000 обучающих сигналов (loss на каждой позиции). Именно поэтому GPT обучается так эффективно — каждый текст даёт столько задач, сколько в нём токенов.
Почему decoder-only победил encoder-decoder?
Scaling Laws — предсказуемая сила масштаба
Kaplan et al. (2020) открыли удивительный факт: loss языковой модели убывает как степенная функция (power law) от трёх переменных — числа параметров N, объёма данных D и compute C. На логарифмическом графике — прямая линия, без «потолка» в исследованном диапазоне.
Это было неочевидно. Могло оказаться, что после 10B параметров рост прекратится, или что нужна принципиально новая архитектура. Но нет — power law работает на порядки, и это дало индустрии чёткий рецепт: хочешь лучше — масштабируй.
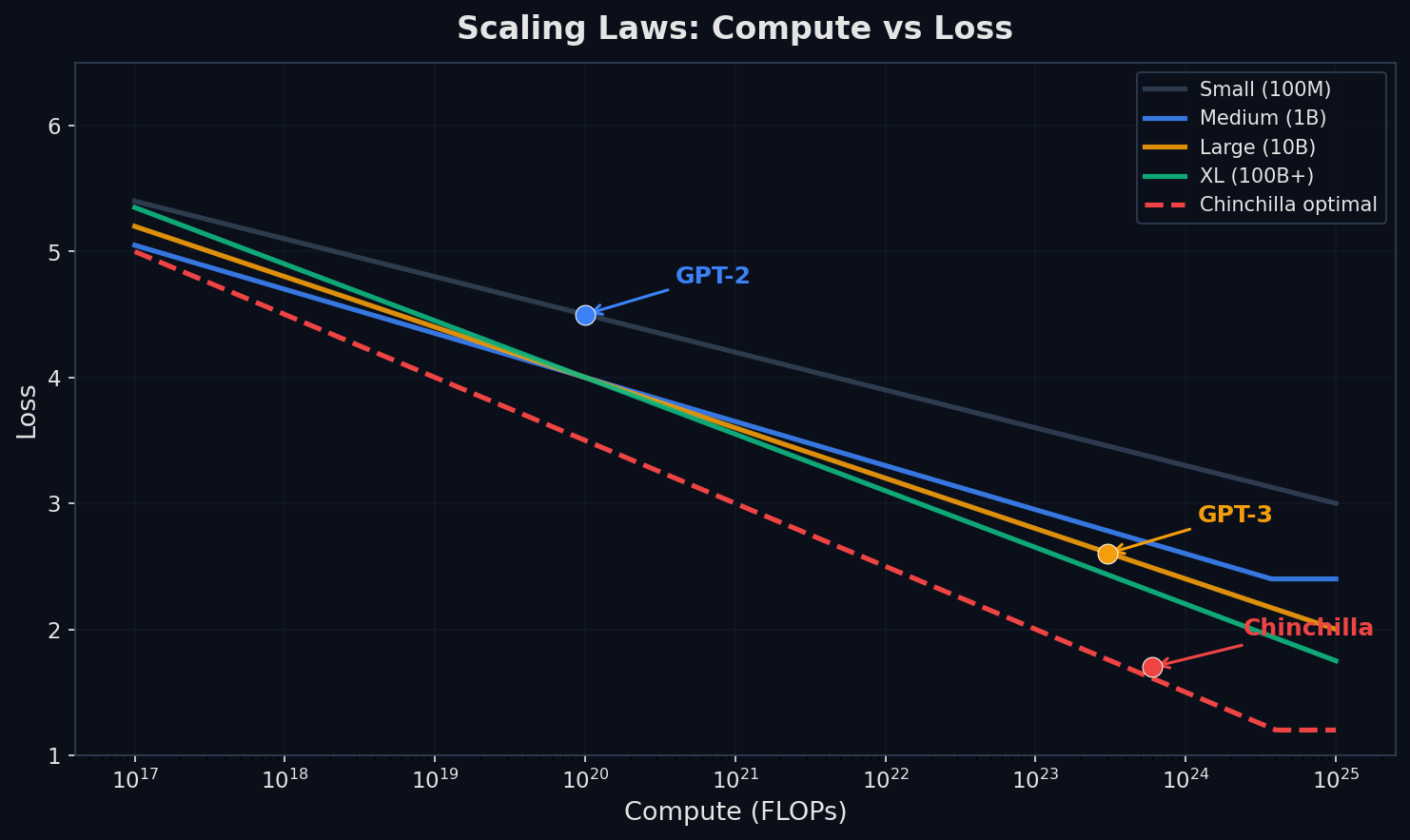
Формула compute и Chinchilla-optimal
Грубая оценка compute для обучения: C ≈ 6ND FLOPs, где N — число параметров, D — число токенов, 6 — множитель от forward (2ND) + backward (4ND) pass. Эта формула позволяет прикинуть стоимость обучения без экспериментов.
Chinchilla (Hoffmann et al., 2022) уточнил правила: параметры и данные надо масштабировать пропорционально. Оптимальное соотношение: D ≈ 20N (на 1B параметров — 20B токенов). GPT-3 с 175B параметров был underfitted — ему нужно было больше данных. Chinchilla с 70B параметров на 4× данных обогнал GPT-3.
- C ≈ 6ND — compute в FLOPs. Для GPT-3 (175B params, 300B tokens): C ≈ 3.1 × 10²³ FLOPs
- Chinchilla-optimal: D ≈ 20N. Для 7B модели — ~140B токенов
- Overtraining (2024-2025 тренд): LLaMA 3 8B обучена на 15T токенов (100× Chinchilla). SmolLM3 3B — 11T токенов. Зачем? Маленькая модель на огромных данных дешевле в инференсе для миллионов запросов
- Inference-aware scaling: дешевле потратить больше compute на training, если это позволит уменьшить N и ускорить каждый из миллиардов inference-запросов
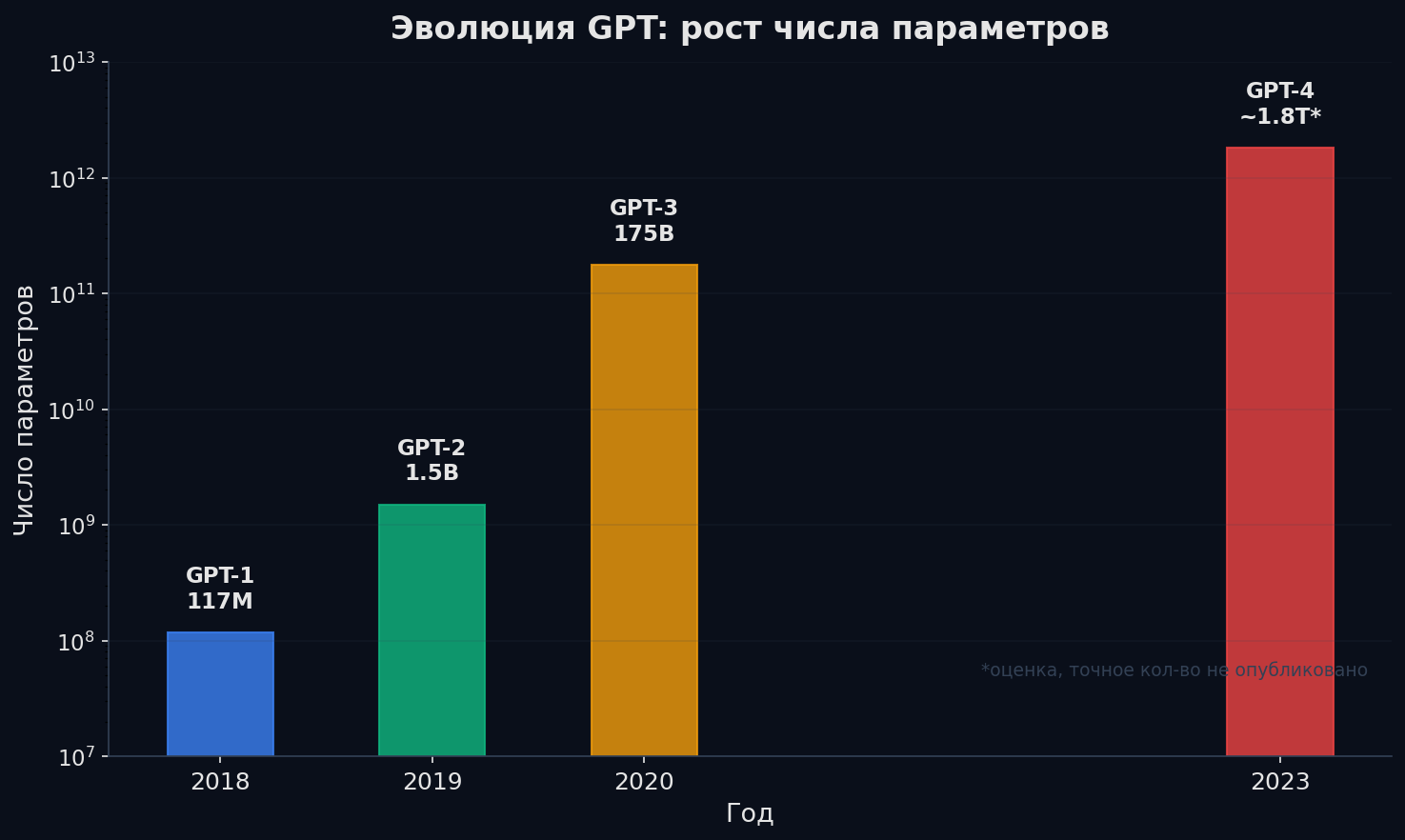
Эволюция: GPT-1 → GPT-2 → GPT-3 → GPT-4
История GPT — идеальная иллюстрация scaling laws. Архитектура почти не менялась — росли масштабы и возможности.
GPT-1 (2018, 117M параметров). Обучен на BookCorpus (~5GB текста). Главная идея: unsupervised pre-training + supervised fine-tuning работает для decoder-моделей. Показал, что один pre-trained трансформер можно адаптировать под разные задачи — но каждую задачу требовал отдельного fine-tuning.
GPT-2 (2019, 1.5B параметров). Обучен на WebText (40 ГБ, ~8M веб-страниц). Ключевое открытие: zero-shot transfer — модель решает задачи без fine-tuning, только по инструкции в промпте. Качество перевода, суммаризации, QA — на уровне простых baseline-ов, но без единого примера. OpenAI сначала побоялись выпускать «из-за рисков злоупотреблений».
GPT-3 (2020, 175B параметров). 570 ГБ текста, тренировка за ~$5M на кластере NVIDIA V100. Революция: in-context learning — модель решает задачи по нескольким примерам в промпте, без обновления весов. Пишет эссе, код, решает математику. Разрыв между GPT-2 и GPT-3 — не количественный, а качественный: эмерджентные способности.
GPT-4 (2023). Архитектура не раскрыта. Мультимодальный (текст + изображения). По слухам — Mixture of Experts. Уровень эксперта на SAT, LSAT, медицинских экзаменах. С RLHF/RLAIF — значительно лучше следует инструкциям и меньше галлюцинирует.
In-Context Learning — обучение без обучения
Главное открытие GPT-3: большая модель может решать задачу, просто увидев несколько примеров в промпте. Никакого градиентного спуска, никакого обновления весов — модель «понимает» задачу из контекста. Это in-context learning (ICL), и это одна из самых загадочных способностей LLM.
Три режима по количеству примеров: Zero-shot — только описание задачи: «Переведи на русский: Hello world →». Модель использует знания из pre-training. One-shot — один пример: «Hello → Привет. Good morning →». Модель «схватывает» формат. Few-shot — 3-5 примеров в промпте. Обычно достаточно для хорошего качества на большинстве задач.
# Few-shot in-context learning — модель "понимает" задачу по примерам
prompt = "" .
: "Отличный товар, рекомендую!"
:
: "Ужасное качество, деньги на ветер"
:
: "Нормальный телефон за свои деньги"
:""
# Модель ответит "нейтральная" — без обучения, без меток, без fine-tuningКак это работает? Полного объяснения пока нет, но есть гипотезы. Одна из них: в процессе pre-training модель видит огромное количество «задач» в естественном тексте — определения слов, переводы, примеры кода с объяснениями. При in-context learning модель не «учится новому», а вспоминает похожий паттерн из training data и применяет его. Другая гипотеза: attention-слои реализуют «неявный градиентный спуск» внутри forward pass.
Emergent abilities — способности, которые появляются только при достаточном масштабе. Арифметика, chain-of-thought reasoning, кодогенерация — модель на 10B не умеет, а на 100B — вдруг умеет. Механизм до конца не понят, и есть дискуссия: это настоящий «фазовый переход» или артефакт метрик (при непрерывных метриках переход выглядит плавным).
RLHF и DPO — как научить модель быть ассистентом
Pre-trained GPT отлично продолжает текст, но плохо следует инструкциям. Если попросить «напиши стихотворение», модель может продолжить «…написать стихотворение можно так:» вместо того, чтобы написать стих. Модель обучена продолжать текст из интернета, а не помогать пользователю.
Alignment (выравнивание) решает эту проблему в три шага: Шаг 1. SFT (Supervised Fine-Tuning) — fine-tune на диалогах «вопрос → качественный ответ», написанных людьми. Модель учится формату ассистента. Шаг 2. Reward Model — обучаем отдельную модель оценивать ответы. Людям показывают два ответа и просят выбрать лучший. Из этих сравнений обучается модель-судья. Шаг 3. RL — оптимизируем GPT с помощью PPO (Proximal Policy Optimization), чтобы максимизировать оценку от Reward Model, не уходя далеко от SFT-модели (KL-штраф).
DPO (Direct Preference Optimization, 2023) — упрощённая альтернатива RLHF. Вместо обучения отдельной Reward Model и RL-оптимизации, DPO напрямую оптимизирует модель по парам «хороший ответ vs плохой ответ». Математически эквивалентно RLHF, но проще в реализации: не нужен RL-loop, reward model и PPO. Большинство open-source моделей в 2024-2025 используют DPO или его вариации (SimPO, KTO, ORPO).
Зачем alignment нужен?
Инференс: как GPT генерирует текст эффективно
При авторегрессионной генерации модель запускает forward pass для каждого нового токена. Наивная реализация: на шаге t пересчитываем attention для всех t токенов — квадратичная стоимость. Но есть трюк.
KV-Cache — не считай одно и то же дважды
KV-cache — ключевая оптимизация инференса. Идея простая: при генерации токена t ключи (K) и значения (V) для токенов 0…t−1 уже были вычислены на предыдущих шагах. Зачем считать их заново? Кэшируем K и V, а на каждом шаге считаем Q, K, V только для нового токена и дописываем K, V в кэш.
Результат: вместо O(t²) attention на каждом шаге — O(t). Цена — память: KV-cache для длинного контекста (128K токенов) может занимать десятки ГБ. Отсюда — GQA (несколько Query-голов делят одну пару K/V, экономя кэш в 4-8×) и квантизация KV-cache.
Стратегии сэмплирования: температура, top-p, beam search
На каждом шаге модель выдаёт вектор logits размером |vocab|. Как выбрать следующий токен?
Температура (temperature) — делит logits на T перед softmax. T=1 — без изменений. T<1 — распределение «обостряется», модель увереннее выбирает топ-вариант (детерминировано). T>1 — распределение «размазывается», ответы разнообразнее (но более шумные). T→0 = greedy decoding.
Top-p (nucleus sampling) — сортируем токены по вероятности, берём минимальный набор, чья суммарная вероятность ≥ p. Из этого ядра (nucleus) сэмплируем. При p=0.9 отсекаем маловероятные токены, сохраняя разнообразие в пределах «разумного».
Beam search — на каждом шаге храним top-B гипотез (beam width), продолжаем каждую, оставляем лучшие B. Даёт более связный текст, но менее разнообразный. Хорош для перевода и суммаризации, плох для креативных задач.
from transformers import pipeline
gen = pipeline("text-generation", model="gpt2")
# Greedy (temperature → 0): детерминированный, но скучный
result = gen("Трансформеры изменили NLP, потому что",
max_new_tokens=30, do_sample=False)
# Творческий (temperature=0.9, top_p=0.95)
result = gen("Трансформеры изменили NLP, потому что",
max_new_tokens=30, do_sample=True,
temperature=0.9, top_p=0.95)
print(result[0]["generated_text"])Ограничения GPT
Галлюцинации (hallucinations). GPT генерирует текст, который *звучит* убедительно, но фактически неверен. Модель не «знает» факты — она моделирует распределение текста. Если наиболее вероятное продолжение — ложное утверждение, модель его выдаст с полной уверенностью. Частичные решения: RAG (добавление фактов из внешних источников), grounding, цитирование.
Контекстное окно (context window). GPT-2 — 1024 токена. GPT-3 — 4096. GPT-4 — 8K/32K/128K. Всё что не влезает в окно — модель не видит. Для длинных документов это ограничение: модель не может «прочитать» книгу целиком (хотя 128K ≈ 300 страниц). Решения: увеличение контекста (RoPE scaling), retrieval (RAG), chunking.
Стоимость. Инференс GPT-4 — ~$0.03/1K input tokens (API). Для миллионов запросов в день это десятки тысяч долларов. Обучение GPT-4 — по оценкам $50-100M. Решения: дистилляция, квантизация, inference-aware scaling (маленькие модели на больших данных), батчинг.
Reasoning. Базовый GPT плохо справляется с многошаговым логическим рассуждением и точной арифметикой. Chain-of-thought prompting и специальное обучение (o1, DeepSeek-R1) частично решают проблему, но настоящее «рассуждение» vs «паттерн-матчинг» — открытый вопрос.
BERT vs GPT — когда что использовать
Часто спрашивают
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
GPT — это decoder-only трансформер, обученный предсказывать следующий токен. Одна простая задача, но при достаточном масштабе из неё вырастают удивительные способности: in-context learning, reasoning, кодогенерация. Scaling laws дают предсказуемый рецепт: больше параметров × больше данных × больше compute = лучше. RLHF/DPO превращают «генератор текста» в полезного ассистента. KV-cache и стратегии сэмплирования делают инференс эффективным.
Если запомнить одну вещь из этой ноды: GPT — это не новая архитектура, а демонстрация силы масштабирования. Decoder-only трансформер 2018 года, масштабированный до 175B+ параметров и выровненный с помощью RLHF, стал основой для всей индустрии LLM.
Подробнее про scaling laws и токенизацию — в ноде «Scaling Laws & Tokenization». Про современные архитектуры (MoE, GQA, RoPE) — в ноде «Современные архитектуры LLM». Про fine-tuning и LoRA — в ноде «LLM Fine-tuning».
Материалы
Визуальное объяснение GPT-2: как decoder генерирует текст шаг за шагом.
Статья про GPT-3: in-context learning, scaling laws, few-shot примеры.
Фундаментальная статья про scaling laws: как loss зависит от параметров, данных и compute.
Chinchilla scaling laws: оптимальное соотношение параметров и данных.
DPO — альтернатива RLHF. Implicit reward model, проще и стабильнее.
Построение GPT с нуля на PyTorch. Лучшее видео для глубокого понимания.
Как использовать GPT-2 для генерации: параметры, примеры, стратегии декодирования.