Дообучение LLM
LoRA, QLoRA, PEFT, инструкционное обучение, RLHF/DPO.
Fine-tuning LLM — как превратить общую модель в специалиста
Pre-trained LLM — это эрудит, который знает обо всём понемногу. Он может написать стихотворение, объяснить квантовую механику и сгенерировать код. Но попроси его отвечать на вопросы клиентов банка в строгом формате, со ссылками на внутренние документы — и начнутся проблемы. Промпт-инжиниринг помогает до определённого предела: few-shot примеры, system prompt, chain-of-thought. Но когда нужна стабильная работа в узком домене, точный формат ответов, следование корпоративным политикам — промпта недостаточно.
Fine-tuning — это дообучение модели на твоих данных. После него модель «из коробки» отвечает в нужном стиле, знает доменную терминологию и следует инструкциям без километровых промптов. Проблема в том, что полное дообучение 7B-модели требует 60+ ГБ видеопамяти и кластер GPU. Но за последние два года появились методы, которые позволяют делать fine-tuning на одной потребительской видеокарте — и это изменило всё.
Большая картина: от pretrained LLM до продакшена
Весь процесс адаптации LLM можно разбить на четыре этапа — каждый решает свою задачу: Этап 1. Pre-training. Модель обучается на триллионах токенов из интернета. Результат: «сырая» модель, которая умеет продолжать текст, но не умеет отвечать на вопросы. Этот этап стоит миллионы долларов и делается один раз (Meta, Google, Mistral). Этап 2. Supervised Fine-Tuning (SFT). Модель учится следовать инструкциям — отвечать на вопросы, писать код, вести диалог. Данные: тысячи пар (инструкция, ответ). Это первый этап, который можно делать самому. Этап 3. Alignment (опционально). Модель учится отвечать так, как предпочитают люди: полезно, безопасно, честно. Методы: RLHF, DPO, GRPO. Именно alignment превращает «умную, но неуправляемую» модель в ChatGPT. Этап 4. Evaluation → Deploy. Оцениваем на бенчмарках и вручную, затем деплоим. Если качество не устраивает — возвращаемся к этапу 2 или 3 с лучшими данными.
Когда fine-tuning НЕ нужен
Full fine-tuning: максимум качества, максимум затрат
Full fine-tuning — это обновление всех параметров модели. Для 7B-модели это 7 миллиардов весов, и для каждого нужно хранить: сам вес (fp16 = 2 байта), градиент (2 байта), optimizer states для Adam (2 момента × 4 байта = 8 байт). Итого: ~12 байт на параметр, или 84 ГБ только для обучения 7B модели. Плюс активации, плюс данные — реально нужно 4-8 A100 по 80 ГБ.
Главный риск — catastrophic forgetting: модель «забывает» знания из pre-training, пока учится на новых данных. Представь, что ты учишь эрудита отвечать на вопросы о банковских продуктах, а он в процессе забывает математику и английский. На практике это проявляется так: модель отлично решает целевую задачу, но деградирует на общих бенчмарках.
Когда full fine-tuning оправдан? Когда задача сильно отличается от pre-training данных (например, модель для медицинской диагностики), когда нужно максимальное качество и есть бюджет на GPU, или когда data mix большой и разнообразный (тысячи задач, как при обучении instruction-following моделей).
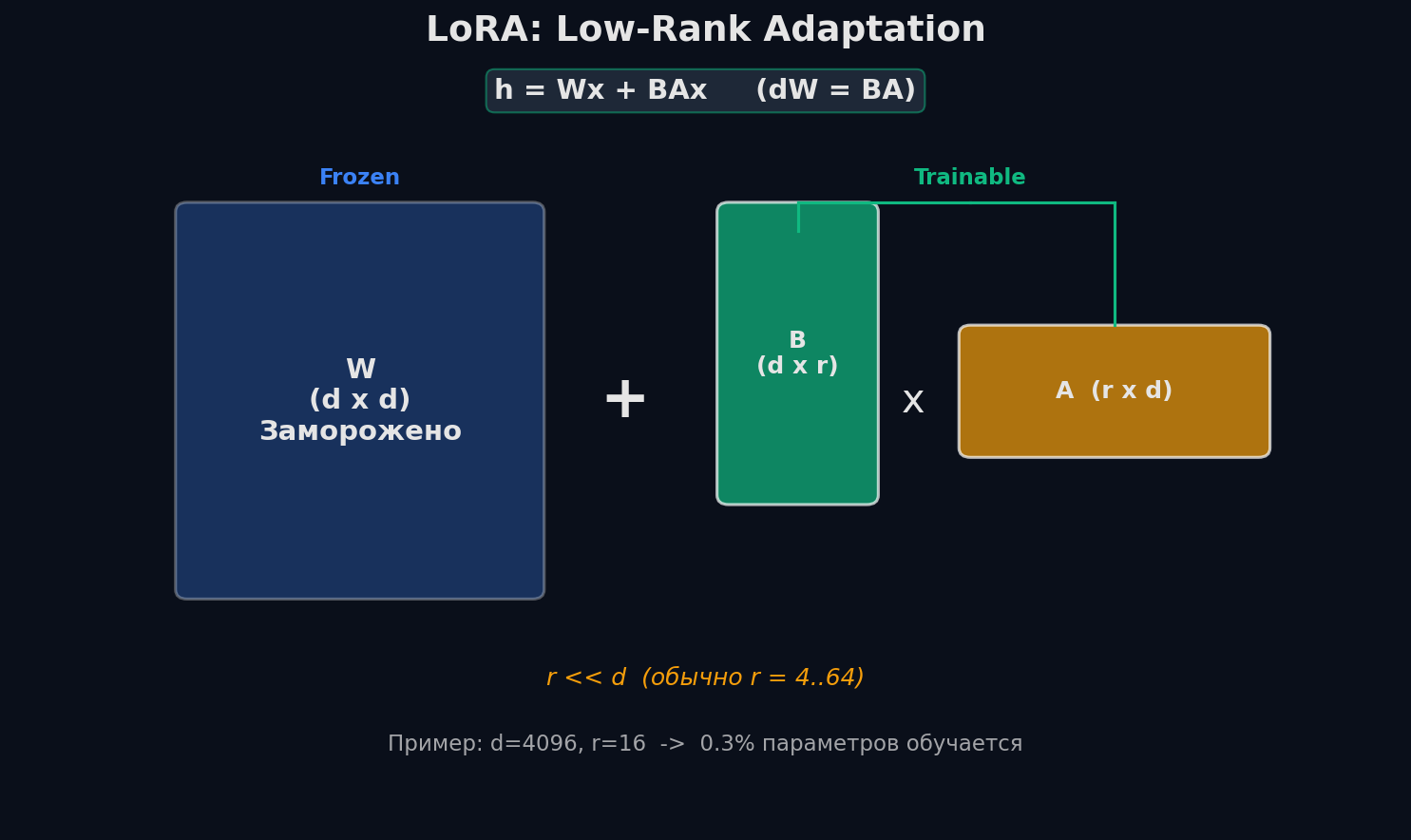
LoRA — Low-Rank Adaptation: главная идея
LoRA (2021) — метод, который сделал fine-tuning доступным. Ключевое наблюдение: при fine-tuning обновление весов ΔW имеет низкий ранг. Модель не переучивается кардинально — она лишь «подкручивает» определённые направления в пространстве весов. LoRA формализует это: вместо полной матрицы обновлений ΔW размера d×d обучаем две маленькие матрицы B (d×r) и A (r×d), где r — ранг, обычно 8-64.
Аналогия: представь, что ты настраиваешь эквалайзер на колонках. Ты не переписываешь прошивку колонки (full fine-tuning), а крутишь несколько ручек — bass, treble, mid. Ручек мало (ранг r = несколько), но они позволяют кардинально изменить звучание. LoRA — это те самые «ручки» для нейросети.
W — оригинальные веса (заморожены), B и A — обучаемые матрицы. Произведение BA имеет ранг ≤ r, что и даёт экономию
Посчитаем экономию на конкретных числах. Матрица Q-проекции в LLaMA-7B: d = 4096. Полная матрица ΔW — это 4096 × 4096 = 16.7 млн параметров. С LoRA при r = 16: B — 4096 × 16 = 65K, A — 16 × 4096 = 65K, итого 131K параметров — в 128 раз меньше. А таких матриц в модели десятки. Суммарно LoRA обучает 0.1-1% от всех параметров.
Гиперпараметры LoRA
Rank (r) — главный гиперпараметр. Определяет «выразительность» адаптации. r = 8 — минимум, хватает для простых задач (классификация, форматирование). r = 32-64 — для сложных задач (генерация кода, математика). r = 128+ — почти не уступает full fine-tuning, но теряется смысл LoRA. Alpha (α) — scaling factor. Адаптация масштабируется как (α/r) · BA. Обычно α = 2 × r. Контролирует «силу» адаптации: слишком маленький α — модель почти не меняется, слишком большой — нестабильность. Target modules — к каким слоям применять LoRA. Минимум: q_proj и v_proj (attention). Практика показывает, что добавление k_proj, o_proj, gate_proj, up_proj, down_proj даёт +2-5% качества при незначительном росте параметров.
Killer feature: merge при инференсе
QLoRA — fine-tuning на одной потребительской GPU
LoRA уже экономит память на обучаемых параметрах, но базовая модель всё ещё занимает много места: 7B в fp16 = 14 ГБ. QLoRA (2023) идёт дальше: квантизует базовую модель в 4-bit (NF4, нормализованный 4-bit формат), а LoRA-адаптеры обучает в fp16/bf16.
Результат: базовая 7B модель = ~3.5 ГБ (вместо 14). Плюс LoRA-адаптеры — несколько десятков МБ. Плюс optimizer states и активации. Итого: fine-tuning 7B модели на одной GPU с 24 ГБ (RTX 4090, A5000). Fine-tuning 70B — на одной A100 80 ГБ. Статья QLoRA показала, что потеря качества от 4-bit квантизации минимальна — модели не уступают full fine-tuning на большинстве бенчмарков.
Три ключевые техники QLoRA: • NF4 (4-bit NormalFloat) — специальный формат квантизации, оптимальный для нормально распределённых весов нейросетей. Каждый вес хранится в 4 битах вместо 16. • Double Quantization — квантизует не только веса, но и сами квантизационные константы. Экономит ещё ~3 ГБ для 65B модели. • Paged Optimizers — использует CPU RAM для хранения optimizer states, когда GPU памяти не хватает (аналог подкачки).
PEFT: другие методы parameter-efficient fine-tuning
LoRA — самый популярный, но не единственный PEFT-метод. Вот основные альтернативы и когда они полезны:
Prefix Tuning (2021) — добавляет обучаемые «виртуальные токены» в начало каждого слоя. Модель видит их как часть контекста, но эти токены не соответствуют реальным словам — они обучаются напрямую. Количество параметров ещё меньше, чем у LoRA, но и качество обычно ниже. Prompt Tuning (2021) — упрощённая версия Prefix Tuning: обучаемые эмбеддинги добавляются только на входе (а не на каждом слое). Очень мало параметров (тысячи), работает для крупных моделей (10B+), но для моделей меньше 10B существенно уступает LoRA. Adapters (2019) — маленькие обучаемые сети (bottleneck: down-project → nonlinearity → up-project), вставленные между замороженными слоями. Исторически первый PEFT-метод. Добавляет latency при инференсе (в отличие от LoRA, которую можно слить).
Данные для fine-tuning: качество важнее количества
Данные — главный фактор успеха fine-tuning. Можно взять лучшую архитектуру с идеальными гиперпараметрами, но мусорные данные дадут мусорную модель. Ключевое правило: 1 000 отличных примеров > 100 000 шумных. Статья LIMA (2023) показала, что SFT на всего 1 000 тщательно подобранных примеров может конкурировать с моделями, обученными на десятках тысяч.
Формат данных
Стандартный формат для SFT — instruction tuning: каждый пример содержит инструкцию (что делать), опциональный input (контекст/данные) и output (желаемый ответ). Для диалогов — массив сообщений с ролями (system, user, assistant).
// instruction tuning (Alpaca-style)
{
"instruction": "Классифицируй отзыв клиента по тональности",
"input": "Доставка задержалась на 3 дня, но менеджер помог решить проблему быстро",
"output": "Смешанная (негативная: задержка доставки, позитивная: качественная поддержка)"
}
// multi-turn dialogue (ShareGPT-style)
{
"conversations": [
{"role": "system", "content": "Ты ассистент банка..."},
{"role": "user", "content": "Какой процент по вкладу?"},
{"role": "assistant", "content": "Актуальные ставки по вкладам..."}
]
}Критично: используй chat template конкретной модели. У LLaMA, Mistral, Qwen — разные спецтокены и форматы. Перепутаешь — модель будет генерировать мусор. Библиотека transformers поддерживает apply_chat_template(), которая делает это автоматически.
Чеклист качества данных
- Разнообразие — покрой все сценарии и edge cases. Не дублируй типовые примеры
- Консистентность — единый стиль ответов, формат, уровень детализации
- Валидация — 5-10% на eval-сет. Следи за training loss + ручная проверка ответов
- Decontamination — убери из трейна примеры, похожие на бенчмарки. Иначе метрики врут
- Loss masking — loss считается только по ответам assistant, не по промптам user
Synthetic data — когда своих данных мало
Нет 10 000 размеченных примеров? Можно попросить более сильную модель (GPT-4, Claude) сгенерировать данные. Это synthetic data — и это работает. Alpaca, Vicuna, WizardLM — все обучены на синтетических данных от GPT-4. Подход: напиши несколько seed-примеров → сгенерируй тысячи вариаций → отфильтруй низкокачественные → обучи на остатке. Ключевой риск: модель может выучить артефакты генератора (стилистические привычки GPT-4), а не решение задачи.
RLHF: обучение с подкреплением на предпочтениях людей
SFT учит модель формату ответов — «как выглядит хороший ответ». Но что значит «хороший»? Для одного запроса может быть десять правильных ответов разного качества. SFT не различает их: loss одинаковый, если формат правильный. RLHF (Reinforcement Learning from Human Feedback) решает эту проблему: модель учится не просто генерировать корректные ответы, а генерировать предпочитаемые ответы.
Аналогия: SFT — это как учить повара рецептам. Он научится готовить по книге. RLHF — это как дать повару дегустатора, который пробует каждое блюдо и говорит: «это лучше, это хуже». Повар постепенно учится готовить не просто «по рецепту», а вкусно.
RLHF-pipeline состоит из трёх этапов: Этап 1. Сбор предпочтений. Для каждого промпта модель генерирует два (или больше) ответа. Человек-асессор выбирает, какой лучше: (prompt, chosen, rejected). Нужно 10K-100K пар. Этап 2. Reward Model. Обучается отдельная модель (обычно SFT-модель с линейной головой), которая по паре (prompt, response) выдаёт скалярный скор — «насколько ответ хорош». Обучается на парах предпочтений: reward(chosen) > reward(rejected). Этап 3. RL-оптимизация (PPO). LLM генерирует ответы, reward model их оценивает, и PPO (Proximal Policy Optimization) обновляет веса LLM в сторону более высокого reward. Добавляется KL-штраф — чтобы модель не уходила слишком далеко от SFT-чекпоинта.
π_θ — текущая политика (LLM), π_ref — референсная (SFT-модель), R_φ — reward model, β — коэффициент KL-штрафа. Максимизируем reward, но не уходим далеко от SFT
Проблемы RLHF: сложность (три модели одновременно: LLM + reward model + reference model), нестабильность PPO (чувствителен к гиперпараметрам, reward hacking — модель находит «лазейки» в reward model), дороговизна (асессоры стоят денег). Именно эти проблемы мотивировали поиск более простых альтернатив.
DPO: alignment без reward model
DPO (Direct Preference Optimization, 2023) — элегантная альтернатива RLHF. Ключевая идея: авторы показали, что оптимальное решение RLHF-задачи можно выразить аналитически через логарифм отношения вероятностей. Это значит, что reward model и PPO не нужны — можно обучать LLM напрямую на парах предпочтений.
Аналогия: вместо того чтобы нанимать дегустатора (reward model), который оценивает каждое блюдо, а потом методом проб и ошибок (PPO) подбирать рецепт — ты просто показываешь повару два блюда и говоришь: «вот это лучше вот этого». Повар напрямую учится из сравнений.
y_w — preferred (winning) ответ, y_l — rejected (losing), σ — сигмоида, β — температура. Loss уменьшается, когда модель присваивает больше вероятности preferred ответу
Что формула говорит на пальцах: берём пару ответов (хороший y_w и плохой y_l). Считаем, насколько текущая модель «отклонилась» от референсной в сторону каждого ответа. Если модель стала больше «любить» хороший ответ (относительно плохого) — loss снижается. Сигмоида превращает разницу в вероятность, и мы максимизируем эту вероятность.
Преимущества DPO: не нужна reward model (экономия GPU и сложности), стабильнее PPO (обычный supervised loss, нет RL-нестабильности), проще имплементация (десятки строк кода вместо тысяч). Ограничения: нет явного reward signal (сложнее дебажить), чувствителен к качеству preference data, может быть хуже RLHF на очень сложных задачах alignment.
GRPO — новый подход (DeepSeek-R1)
Практика: fine-tuning с HuggingFace TRL
Вот минимальный, но рабочий pipeline SFT + LoRA с библиотекой TRL (Transformer Reinforcement Learning). Всё, что нужно — одна GPU с 24 ГБ и датасет в правильном формате.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig
from trl import SFTTrainer, SFTConfig
from datasets import load_dataset
# 1. Загружаем модель в 4-bit (QLoRA)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # NormalFloat4
bnb_4bit_compute_dtype="bfloat16", # вычисления в bf16
)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B-Instruct",
quantization_config=bnb_config,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B-Instruct")
# 2. LoRA-конфиг
lora_config = LoraConfig(
r=16, # ранг
lora_alpha=32, # scaling = alpha/r = 2
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_dropout=0.05,
task_type="CAUSAL_LM",
)
# 3. Датасет (instruction format)
dataset = load_dataset("json", data_files="train.jsonl", split="train")
# 4. Обучение
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=lora_config,
args=SFTConfig(
output_dir="./checkpoints",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4, # effective batch = 16
learning_rate=2e-4,
warmup_ratio=0.03,
logging_steps=10,
bf16=True,
),
)
trainer.train()
trainer.save_model("./final-adapter") # сохраняем только LoRA-веса (~50MB)Типичные ошибки
- Неправильный chat template — модель генерирует мусор. Решение:
tokenizer.apply_chat_template(), не форматируй промпты вручную - Слишком высокий learning rate — loss скачет, модель деградирует. Для LoRA: 1e-4 — 3e-4. Для full FT: 1e-5 — 5e-5
- Мало данных + много эпох — переобучение. Мониторь eval loss, остановись когда он перестаёт падать
- Забыл loss masking — считаешь loss и по промпту, и по ответу. Модель учится повторять инструкции вместо решения задач
- Rank слишком маленький — r=4 на сложной задаче. Начни с r=16, увеличивай если качество не устраивает
- Нет eval set — не видишь переобучение. Всегда выделяй 5-10% данных на валидацию
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Fine-tuning LLM — это спектр подходов от «дорого, но максимум контроля» (full fine-tuning) до «дёшево и почти так же хорошо» (QLoRA). LoRA — главный метод: замораживаем базу, учим маленькие матрицы BA. QLoRA добавляет 4-bit квантизацию и делает fine-tuning доступным на одной GPU. Данные решают: 1000 качественных примеров > 100K шумных. SFT учит формату, alignment (RLHF/DPO) учит предпочтениям.
Если запомнить одну вещь из этой ноды: LoRA позволяет адаптировать любую LLM под свою задачу на одной GPU за несколько часов, обучая менее 1% параметров. Это демократизировало fine-tuning и превратило его из привилегии больших лабораторий в инструмент каждого ML-инженера.
Дальше на роадмапе: подробности SFT с chat templates и loss masking — в «SFT и дообучение». Формулы и pipeline alignment — в «RLHF и DPO». Продвинутые техники (GRPO, iterative DPO) — в «Advanced Post-Training».
Материалы
Оригинальная статья LoRA (Hu et al., 2021). Обязательна к прочтению — формулы простые, идея красивая.
QLoRA — fine-tuning 65B модели на одной 48GB GPU. NF4, double quantization, paged optimizers.
DPO — alignment без reward model. Одна из самых цитируемых статей 2023 года.
Библиотека для SFT, DPO, RLHF, GRPO. Всё в одном месте с примерами кода.
Наглядное объяснение RLHF pipeline с визуализациями и примерами.
Документация по всем PEFT-методам: LoRA, QLoRA, Prefix Tuning, Adapters. Примеры и рецепты.