Промпт-инжиниринг
Zero/few-shot, chain-of-thought, structured output, system prompts.
Prompt Engineering — инженерия управления LLM
«Просто напиши ChatGPT, что тебе нужно» — так думают люди, которые не работали с LLM в продакшене. На практике разница между хорошим и плохим промптом — это разница между системой, которая стабильно решает задачу, и системой, которая галлюцинирует, игнорирует инструкции и выдаёт разный результат на одинаковый вход.
Prompt engineering — это набор техник управления поведением LLM через текст. Без изменения весов модели, без fine-tuning, без обучения. Только текст — но правильный текст. Это полноценная инженерная дисциплина с паттернами, anti-паттернами и измеримыми метриками качества.
Почему это важно: • Скорость итерации. Fine-tuning занимает часы-дни, изменение промпта — секунды. • Стоимость. Хороший промпт может заменить fine-tuning для 80% задач. • Контроль. Промпт — единственный интерфейс к closed-source моделям (GPT-4, Claude). Нельзя залезть внутрь — можно только правильно попросить. • На собеседованиях. Prompt engineering — обязательный навык для любой позиции, связанной с LLM.
Большая картина: анатомия промпта
Современные LLM работают через Chat API: ты отправляешь массив сообщений с ролями, модель возвращает ответ. Три роли образуют три «слоя управления»:
System prompt — «конституция» диалога. Задаёт роль модели, ограничения, формат вывода. Действует на протяжении всей сессии. Пользователь обычно не видит system prompt. User prompt — конкретный запрос или задача. Может содержать примеры (few-shot), инструкции, входные данные. Assistant messages — предыдущие ответы модели. Формируют контекст диалога, влияют на следующие ответы.
Ключевая идея: LLM — это автокомплит. Модель не «думает» — она предсказывает наиболее вероятное продолжение. Prompt engineering — это искусство создать такой контекст, чтобы наиболее вероятное продолжение совпало с тем, что тебе нужно.
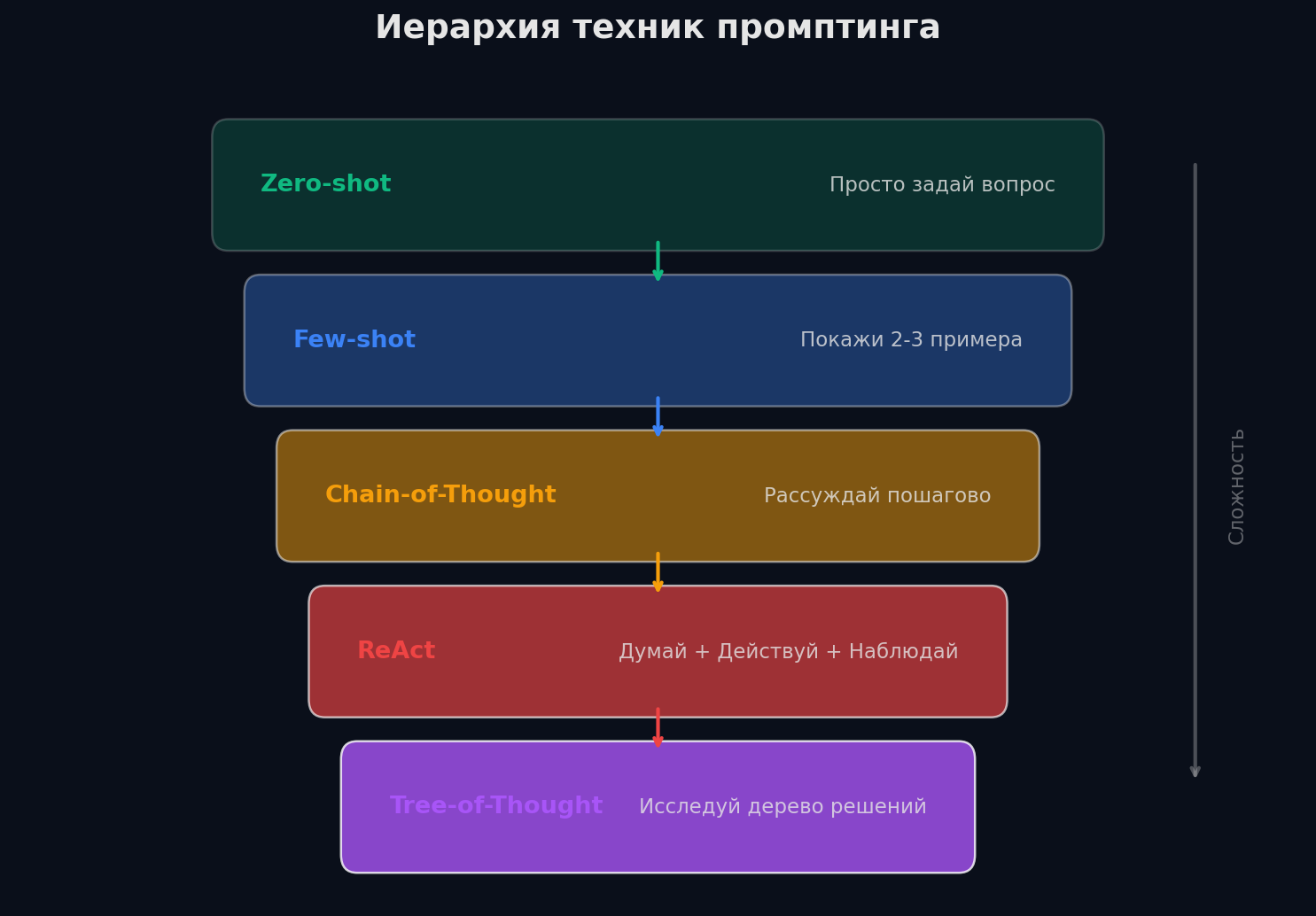
Три базовые техники: zero-shot, few-shot, chain-of-thought
Аналогия: ты даёшь задачу стажёру. • Zero-shot — «Классифицируй этот отзыв как позитивный или негативный». Просто задача, без примеров. Работает, если задача простая и модель достаточно мощная. • Few-shot — «Вот 3 примера. „Отличный товар!" → позитивный. „Ужасно, не работает" → негативный. „Нормально, ничего особенного" → нейтральный. Теперь классифицируй этот отзыв». Показываешь паттерн — модель продолжает. • Chain-of-thought (CoT) — «Рассуждай пошагово. Сначала определи ключевые слова, потом оцени тональность, затем дай классификацию». Просишь «думать вслух» — модель ошибается реже.
# Zero-shot — просто задача
zero_shot = "Classify the sentiment: 'The battery life is terrible' → "
# Few-shot — задача + примеры
few_shot = ""Classify the sentiment.
'Great quality!' positive
'Broke after a week' negative
'It's okay neutral
'The battery life is terrible' ""
# Chain-of-thought — задача + рассуждение
cot = ""Classify the sentiment. Think step by step.
Review: 'The battery life is terrible'
Step 1: Key phrase 'terrible' (strongly negative word)
Step 2: Subject battery life (product feature)
Step 3: No positive qualifiers
Sentiment: negative""Когда что использовать: • Zero-shot — для простых задач (перевод, суммаризация) на мощных моделях (GPT-4, Claude 3.5+). Экономит токены. • Few-shot (3-5 примеров) — когда нужен конкретный формат вывода или задача нестандартная. Выбирай разнообразные, репрезентативные примеры — они критичнее, чем их количество. • CoT — для задач с рассуждением: математика, логика, multi-step reasoning. Бонус: +10-40% accuracy на reasoning-задачах.
System prompt: роль, ограничения, формат
System prompt — самый мощный инструмент управления LLM. Он задаёт контекст, в котором модель генерирует ответы. Хороший system prompt содержит три вещи:
1. Роль — кто модель в этом диалоге. «Ты — senior ML-инженер, который объясняет концепции junior-разработчикам» работает лучше, чем «Ты полезный помощник». Роль активирует нужный «регистр» модели — технический жаргон, уровень детализации, стиль. 2. Ограничения (constraints) — чего модель не должна делать. «Не используй markdown», «Отвечай только на русском», «Если не знаешь — скажи „не знаю"». Без ограничений модель будет делать то, что считает «полезным» — а это не всегда совпадает с тем, что нужно тебе. 3. Формат вывода — как должен выглядеть ответ. JSON schema, markdown таблица, конкретные поля. Чем точнее опишешь формат, тем стабильнее результат.
# ❌ Плохой system prompt — слишком общий
bad_system = "Ты полезный ассистент."
# ✅ Хороший system prompt — конкретный, с ограничениями
good_system = "" ML-, .
: Python- ML-.
:
-
- : , ,
- "Ошибок не найдено"
- ,
:
## Ошибки
1. ** X**: [ ] []. : []
""Промпт-кеширование (Prompt Caching)
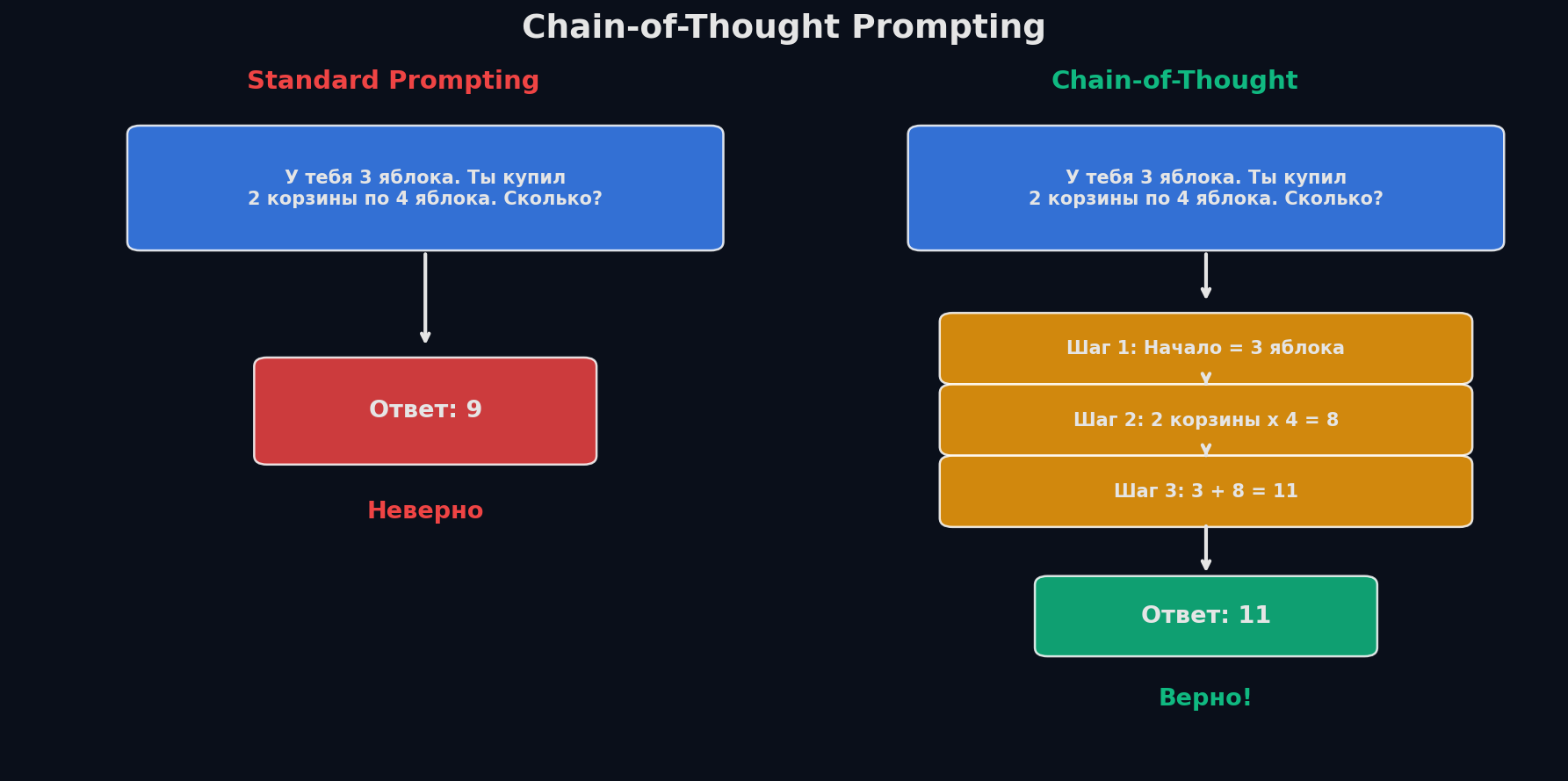
Chain of Thought: «Давай подумаем пошагово»
CoT — одна из самых исследованных техник промптинга. Суть проста: попроси модель показать рассуждение перед финальным ответом. Это работает, потому что LLM генерирует токен за токеном — если сразу просить ответ, модель «угадывает» за один шаг. Если сначала описать рассуждение, каждый промежуточный токен корректирует направление генерации.
Три варианта CoT: Zero-shot CoT — просто добавь «Let's think step by step» к запросу. Бесплатный буст для reasoning-задач. Wei et al. (2022) показали +10-15% accuracy на GSM8K (математика). Few-shot CoT — покажи примеры с цепочкой рассуждений. Модель копирует формат: не просто ответ, а «сначала… потом… значит…». Самый надёжный вариант для продакшена. Self-Consistency — запусти CoT N раз (temperature > 0), собери N ответов, возьми самый частый (majority vote). Wang et al. (2022) показали: 40 прогонов → ещё +5-15% accuracy сверх обычного CoT. Дорого, но эффективно для критичных задач.
# Self-Consistency: запускаем CoT N раз, берём majority vote
from collections import Counter
def self_consistency(client, prompt: str, n: int = 5) -> str:
answers = []
for _ in range(n):
resp = client.chat.completions.create(
model="gpt-4o",
temperature=0.7, # нужна вариативность!
messages=[
{"role": "system", "content": "Solve step by step. "
"End with 'ANSWER: <value>'"},
{"role": "user", "content": prompt},
],
)
# Извлекаем финальный ответ после "ANSWER:"
text = resp.choices[0].message.content
if "ANSWER:" in text:
answers.append(text.split("ANSWER:")[-1].strip())
# Majority vote
return Counter(answers).most_common(1)[0][0]Продвинутые техники: ReAct, Tree of Thoughts, Self-Reflection
CoT — это линейная цепочка рассуждений. Но реальные задачи часто требуют действий (вызов API, поиск), ветвления (попробовать несколько путей) или самопроверки (убедиться, что ответ верный). Для этого есть продвинутые техники.
ReAct (Reasoning + Acting)
ReAct (Yao et al., 2022) чередует рассуждение и действия. Модель думает → делает → наблюдает результат → думает снова. Это фундамент AI-агентов.
: ,
Thought 1: , .
Action 1: search("место рождения Альберт Эйнштейн")
Observation 1: , .
Thought 2: . .
Action 2: search("столица Германия")
Observation 2: .
Thought 3: .
Answer: ReAct превращает LLM из «генератора текста» в агента, способного работать с внешними инструментами. На практике ReAct — основа фреймворков вроде LangChain, CrewAI и агентов Claude/GPT.
Tree of Thoughts (ToT)
Если CoT — это одна цепочка рассуждений, то Tree of Thoughts (Yao et al., 2023) — это дерево. Модель генерирует несколько возможных следующих шагов, оценивает каждый, выбирает лучший и продолжает. Можно даже откатываться (backtrack), если ветка оказалась тупиковой.
ToT работает там, где нужен поиск: головоломки, планирование, креативное письмо. Цена — многократный вызов LLM (оценка каждого узла). На практике ToT используется редко из-за стоимости, но идея ветвления и оценки легла в основу «thinking»-моделей (o1, Claude 3.5 Sonnet с extended thinking).
Self-Reflection
Проверка собственного ответа. После генерации ответа модель получает второй промпт: «Проверь ответ выше. Если нашёл ошибки — исправь». Shinn et al. (2023) в работе Reflexion показали, что итеративная самопроверка с сохранением «памяти об ошибках» значительно улучшает качество на coding и reasoning бенчмарках.
# Паттерн Self-Reflection: генерация → проверка → исправление
def generate_with_reflection(client, task: str, max_rounds: int = 3) -> str:
answer = None
for round in range(max_rounds):
if answer is None:
# Первая генерация
resp = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": task}],
)
answer = resp.choices[0].message.content
else:
# Self-reflection: проверка + исправление
resp = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": task},
{"role": "assistant", "content": answer},
{"role": "user", "content":
"Проверь ответ. Найди ошибки. "
"Если всё верно — повтори ответ. "
"Если нет — исправь."},
],
)
new_answer = resp.choices[0].message.content
if new_answer == answer:
break # Ответ стабилизировался
answer = new_answer
return answerStructured Output — JSON без сюрпризов
В продакшене тебе не нужен «свободный текст» — нужен валидный JSON с конкретными полями. Проблема: LLM может добавить комментарий перед JSON, забыть закрыть скобку, выдумать поле. Решения — от простых к надёжным:
JSON mode (OpenAI, Anthropic) — модель гарантированно вернёт валидный JSON. Но не гарантирует, что JSON соответствует твоей схеме. Может вернуть {"result": 42} вместо {"sentiment": "positive", "confidence": 0.95}.
Structured Outputs / Function Calling — задаёшь JSON Schema, модель заполняет поля. Самый надёжный способ через API. Поддерживается в OpenAI, Anthropic (tool use), Google (function declarations).
Constrained Decoding (Outlines, llama.cpp grammar) — на уровне генерации запрещает невалидные токены. Если по грамматике следующий символ — {, модель не сможет начать с Sure,. Работает только с локальными моделями.
Retry + Validation — парсишь ответ Pydantic-валидатором, если не прошёл — отправляешь ошибку обратно в промпт. Простой fallback, добавляет латенси.
from openai import OpenAI
from pydantic import BaseModel
client = OpenAI()
# Structured Output через response_format (OpenAI)
class SentimentResult(BaseModel):
sentiment: str # "positive" | "negative" | "neutral"
confidence: float
key_phrases: list[str]
resp = client.beta.chat.completions.parse(
model="gpt-4o",
response_format=SentimentResult,
messages=[
{"role": "system", "content": "Analyze sentiment. Return structured JSON."},
{"role": "user", "content": "The battery lasts forever, amazing!"},
],
)
result = resp.choices[0].message.parsed
print(result.sentiment) # "positive"
print(result.confidence) # 0.95
print(result.key_phrases) # ["battery lasts forever", "amazing"]Типичные ошибки промпт-инженеров
Промпт-инжиниринг кажется простым, но ошибки стоят дорого — и в токенах, и в качестве.
- Слишком длинный промпт. Больше текста ≠ лучше результат. Модель «теряет» важные инструкции в середине длинного промпта (lost-in-the-middle effect). Правило: если инструкцию можно убрать без потери качества — убери.
- Противоречивые инструкции. «Отвечай кратко» + «Объясни подробно каждый шаг» → модель выберет случайно. Перечитывай промпт на внутренние конфликты.
- Нет примеров формата. «Верни JSON» — не описание формата. Покажи конкретный пример JSON с нужными полями.
- Нет негативных инструкций. Модель не знает, чего ты НЕ хочешь. «НЕ добавляй вступление», «НЕ используй markdown» — часто важнее позитивных инструкций.
- Отсутствие eval. Изменил промпт → прогони eval set (30-50 примеров с ожидаемыми ответами). Без eval ты не знаешь, улучшил промпт или сломал.
- Промпт зависит от модели. Промпт, идеальный для GPT-4, может не работать с Claude или LLaMA. Версионируй промпты, тестируй на целевой модели.
- Injection без защиты. Если пользовательский ввод попадает в промпт без санитизации — атакующий может перезаписать инструкции. Разделяй system/user/data через XML-теги, валидируй выход.
Temperature и Top-p — тонкая настройка
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Prompt engineering — это не «подобрать магические слова». Это инженерная дисциплина с чёткой иерархией техник: zero-shot (просто инструкция) → few-shot (инструкция + примеры) → CoT (инструкция + рассуждение) → ReAct (рассуждение + действия) → Tree of Thoughts (ветвление + оценка). Каждый следующий уровень мощнее, но дороже.
Если запомнить одну вещь из этой ноды: хороший промпт = конкретная роль + чёткие constraints + явный формат + примеры + eval. Всё остальное — оптимизации.
Связанные темы: RAG расширяет контекст модели внешними данными, Fine-tuning LLM меняет сами веса, когда промптинга недостаточно, а LLM Evaluation измеряет качество — без eval промпт-инжиниринг превращается в гадание.
Материалы
Самый полный гайд по техникам промптинга: от zero-shot до Tree of Thoughts с примерами.
Официальный гайд OpenAI: 6 стратегий с примерами для Chat API.
Гайд от Anthropic: XML-теги, chain-of-thought, structured output, prompt caching.
Бесплатный курс от Andrew Ng: практический prompt engineering с Jupyter ноутбуками.
Оригинальная статья ReAct — фундамент AI-агентов. Reasoning + Acting loop.
Tree of Thoughts — ветвление и оценка рассуждений. Для задач с поиском.