Оценка LLM
Бенчмарки, human eval, MMLU/HumanEval, оценка галлюцинаций, red-teaming.
Оценка LLM — от «вроде норм» к системному eval
Ты попробовал три модели, задал каждой пять вопросов и выбрал ту, которая «больше понравилась». Поздравляю — это vibes-based evaluation, и это главная ошибка при выборе LLM. Модель, которая красиво отвечает на твои пять вопросов, может стабильно галлюцинировать на шестом, путать даты, игнорировать инструкции и обходиться в 10× дороже.
Оценка LLM — это инженерная дисциплина, а не вкусовщина. У неё есть свои метрики, бенчмарки, пайплайны и подводные камни. Проблема в том, что LLM — не классификатор с одним числом accuracy. Ответ модели — свободный текст, и «правильность» зависит от задачи: для перевода важна точность, для чат-бота — полезность, для суммаризации — полнота без галлюцинаций.
В этой ноде — системный подход: от публичных бенчмарков до построения своего eval pipeline.
Большая картина: пирамида оценки LLM
Оценка LLM — это не одна метрика, а пирамида из четырёх уровней, каждый из которых отвечает на свой вопрос:
Уровень 1. Публичные бенчмарки — «Модель вообще умная?» MMLU, HumanEval, MT-Bench. Входной фильтр: отсекаем явно слабые модели. Дёшево, быстро, но ничего не говорит о твоей задаче. Уровень 2. Domain-specific eval — «Модель решает мою задачу?» Свой eval set из 50-200 примеров с ожидаемыми ответами. Автоматические метрики: exact match, BLEU, ROUGE, BERTScore. Главный инструмент для итерации. Уровень 3. LLM-as-a-Judge + Human eval — «Ответ действительно хороший?» Для open-ended задач (суммаризация, диалог) автоматические метрики не работают. GPT-4 как судья или человек-разметчик оценивают качество. Уровень 4. A/B тест в продакшене — «Пользователям лучше?» Онлайн-метрики: retention, satisfaction, task completion rate. Финальная проверка на реальных пользователях.
Ключевой принцип: каждый следующий уровень дороже, но точнее. Бенчмарки стоят 0 — но они общие. A/B тест стоит недели — но даёт реальный ответ. Хороший eval pipeline использует все четыре уровня как фильтры: бенчмарки → domain eval → judge → A/B.
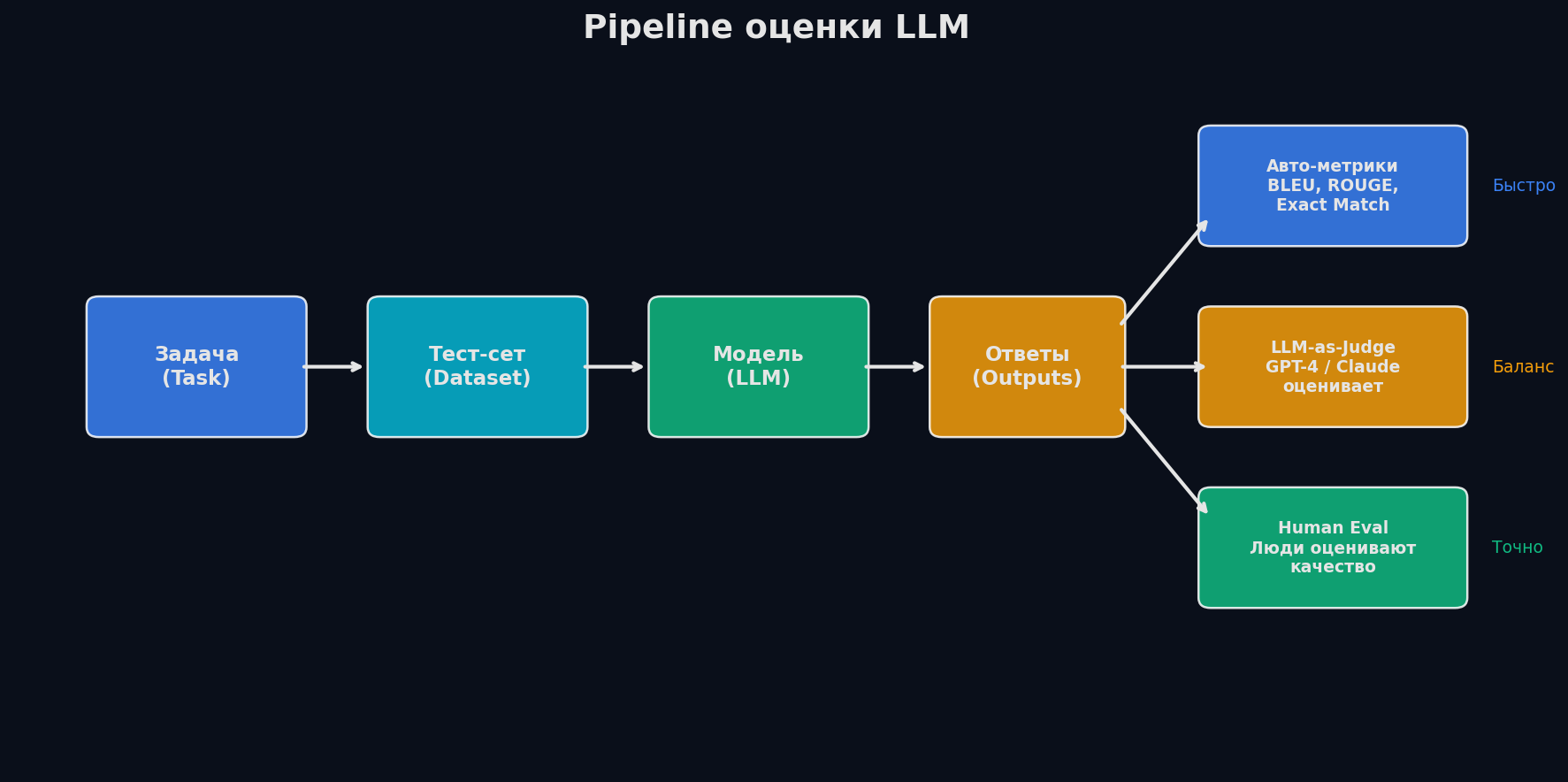
Публичные бенчмарки: входной фильтр, не финальная оценка
Бенчмарк — стандартизированный тест с фиксированными вопросами и ответами. Их десятки, и каждый проверяет одну грань: знание фактов, код, математику, следование инструкциям. Ни один не проверяет, решит ли модель твою задачу. Но бенчмарки полезны для первичного скрининга — если модель набирает 40% на MMLU, она не справится с суммаризацией юридических документов.
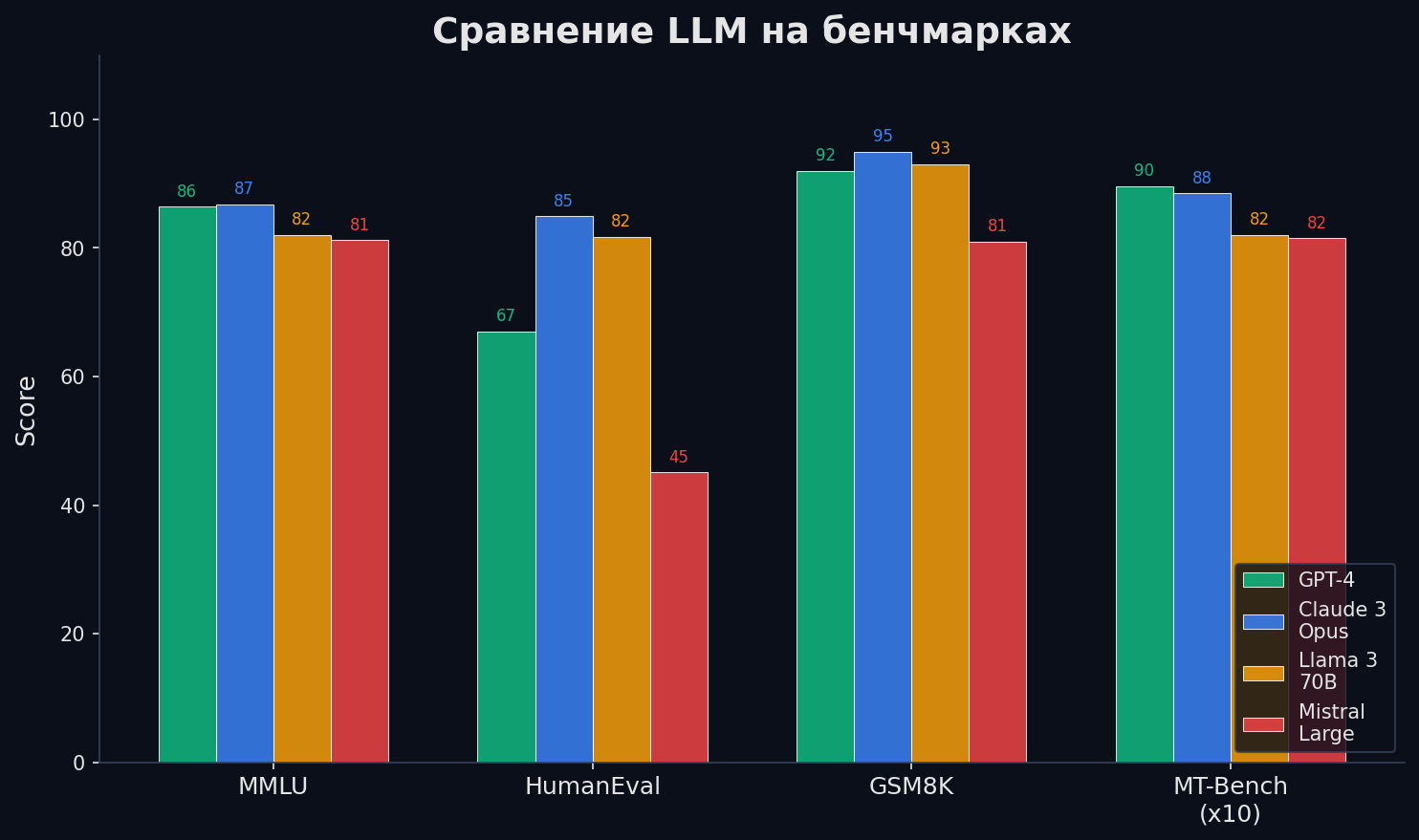
Знания и рассуждения: • MMLU / MMLU-Pro — 57 предметов (от истории до квантовой физики). Pro-версия сложнее: 10 вариантов вместо 4, меньше угадывания. Frontier-модели: ~90%, ceiling effect. • GPQA Diamond — вопросы уровня PhD по физике, химии, биологии. Даже эксперты из смежных областей ошибаются в 30%. Главный бенчмарк «глубокого рассуждения» с 2024 года. • ARC-Challenge — вопросы по науке для школьников, но требующие multi-step reasoning.
Код и математика: • HumanEval / LiveCodeBench — генерация кода по описанию. LiveCodeBench обновляется ежемесячно новыми задачами — борется с data contamination. • SWE-bench Verified — реальные GitHub issues: модель должна починить баг в реальном репозитории. Самый хардкорный coding-бенчмарк. • GSM8K / MATH / AIME — школьная математика → олимпиадная. GSM8K устаревает (frontier: 95%+), AIME — действительно сложные задачи.
Диалог и инструкции: • MT-Bench — 80 двухходовых диалогов, GPT-4 оценивает. Стандарт для chat-моделей. • Arena-Hard — 500 задач, отобранных из самых «разделяющих» промптов Chatbot Arena. Коррелирует с живыми ELO-рейтингами. • Chatbot Arena (LMSYS) — не бенчмарк, а платформа. Реальные пользователи сравнивают анонимные ответы двух моделей и голосуют. ELO-рейтинг из ~1M голосов — самый надёжный индикатор «общего качества» chat-модели. • IFEval — точное следование инструкциям (формат, длина, язык, ограничения). Проверяет не ум, а послушность.
LLM-as-a-Judge: когда модель оценивает модель
Для open-ended задач (суммаризация, диалог, creative writing) автоматические метрики вроде BLEU работают плохо — хороший ответ может сильно отличаться от эталонного и всё равно быть правильным. Человеческая оценка точна, но дорогая и медленная: $2-5 за пример, дни на разметку.
LLM-as-a-Judge — компромисс: сильная модель (GPT-4, Claude) оценивает ответы слабой. Работает на удивление хорошо: корреляция с человеческими оценками 80-90% (статья MT-Bench, 2023). Это стало стандартным подходом для eval в 2024-2025.
Два режима: Pointwise scoring — модель ставит оценку по шкале (1-5, 1-10). Просто, но шумно: модель может ставить всем 4 из 5. Pairwise comparison — модель сравнивает два ответа и выбирает лучший. Надёжнее: относительные суждения проще абсолютных. Именно так работает Chatbot Arena.
# Pointwise: LLM-as-judge оценивает ответ по rubric
judge_prompt = f""Rate this answer on a scale 1-5.
Criteria: accuracy, completeness, clarity.
Question: {question}
Answer: {answer}
Reference: {reference}
Score (number only):""
score = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": judge_prompt}],
temperature=0,
)
# Pairwise: какой ответ лучше?
pairwise_prompt = f""Which answer is better Reply A or B only.
Question: {question}
Answer A: {answer_a}
Answer B: {answer_b}""Bias LLM-судьи — что может пойти не так
У LLM-as-a-Judge есть систематические смещения. Знать их — значит уметь компенсировать:
- Position bias — судья предпочитает первый (или последний) ответ. Fix: рандомизируй порядок, прогоняй дважды (A-B и B-A)
- Verbosity bias — длинный ответ ≠ хороший, но LLM думает иначе. Fix: добавь в промпт «brevity is a plus»
- Self-bias — GPT-4 предпочитает ответы GPT-4 перед Claude, и наоборот. Fix: используй другую модель-судью или несколько судей
- Sycophancy — судья соглашается с уверенно написанным ответом, даже если он неправильный. Fix: добавь reference answer
- Style over substance — markdown, списки, эмодзи повышают оценку. Fix: инструкция «оценивай содержание, не оформление»
Автоматические метрики NLG: BLEU, ROUGE, BERTScore
Для задач с эталонным ответом (перевод, суммаризация, QA) есть классические метрики. Все они сравнивают сгенерированный текст с reference — но по-разному:
BLEU (Bilingual Evaluation Understudy) — считает долю n-грамм из кандидата, совпадающих с reference. Precision-ориентирован: «сколько из того, что модель написала, есть в эталоне?». Стандарт для машинного перевода, но плохо работает для длинных текстов и парафразов.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) — считает долю n-грамм из reference, покрытых кандидатом. Recall-ориентирован: «сколько из эталона модель покрыла?». Стандарт для суммаризации. • ROUGE-1: совпадение по отдельным словам (униграммы) • ROUGE-2: совпадение по биграммам • ROUGE-L: longest common subsequence — не требует точного порядка
BERTScore — вместо точного совпадения слов считает косинусную близость эмбеддингов (из BERT). «Машина» и «автомобиль» — разные слова (BLEU/ROUGE: 0), но близкие эмбеддинги (BERTScore: высокий). Лучше ловит парафразы, но медленнее.
from rouge_score import rouge_scorer
from bert_score import score as bert_score
import evaluate
# BLEU (sacrebleu — стандарт для MT)
bleu = evaluate.load("sacrebleu")
result = bleu.compute(
predictions=["The cat is on the mat"],
references=[["The cat sits on the mat"]]
)
print(f"BLEU: {result['score']:.1f}") # ~46.7
# ROUGE
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'])
scores = scorer.score(
"The cat is on the mat", # reference
"A cat is sitting on the mat" # prediction
)
print(f"ROUGE-1 F1: {scores['rouge1'].fmeasure:.2f}") # ~0.77
# BERTScore (ловит семантическое сходство)
P, R, F1 = bert_score(
["A car is parked outside"], # prediction
["The automobile stands outside"], # reference
lang="en"
)
print(f"BERTScore F1: {F1.mean():.2f}") # ~0.92 (BLEU был бы ~0)Когда какую метрику использовать
Domain-specific eval: строим свой eval set
Модель набрала 85% на MMLU — это хорошо? Для твоей задачи суммаризации юридических документов — никак не связано. Публичные бенчмарки ≠ качество на твоём домене. Единственная правда — свой eval set.
Как его построить: 1. Собери 50-200 примеров. Покрой основные сценарии: типичные запросы (70%), edge cases (20%), adversarial примеры (10%). Для каждого примера — ожидаемый ответ или rubric (критерии «правильности»). 2. Определи метрику. Для closed-ended (QA, классификация) — exact match, F1. Для open-ended — rubric + LLM-judge. Для extraction — precision/recall по полям. 3. Автоматизируй. Скрипт, который прогоняет модель по eval set и возвращает число. Изменил промпт — прогнал eval. Поменял модель — прогнал eval. Без этого ты работаешь вслепую. 4. Версионируй eval set вместе с промптами — они эволюционируют вместе. Периодически добавляй реальные ошибки из продакшена (regression testing).
# Минимальный eval pipeline
import json
from openai import OpenAI
client = OpenAI()
eval_set = json.load(open("eval_set.json"))
# [{"input": "...", "expected": "...", "rubric": "..."}, ...]
results = []
for example in eval_set:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": example["input"]}],
temperature=0,
)
answer = response.choices[0].message.content
# LLM-as-judge оценивает по rubric
judge_resp = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f""Rate 1-5.
Rubric: {example['rubric']}
Expected: {example['expected']}
Actual: {answer}
Score:""}],
temperature=0,
)
score = int(judge_resp.choices[0].message.content.strip())
results.append(score)
print(f"Mean score: {sum(results)/len(results):.2f}")
print(f"Pass rate (>=4): {sum(1 for s in results if s >= 4)/len(results):.0%}")Галлюцинации: как измерить и обнаружить
LLM уверенно пишет неправду — выдумывает факты, ссылки, цитаты, даты. Это не баг, а фундаментальное свойство: модель оптимизирована на «правдоподобность» текста (next token prediction), а не на «правдивость» фактов. Для продакшена галлюцинации — главный риск.
Два типа галлюцинаций: Intrinsic — противоречие с собственным контекстом. Модель в начале ответа пишет «компания основана в 2010», а через абзац — «за 20 лет с момента основания в 2005». Extrinsic — утверждения, которые нельзя подтвердить из источников. Модель выдумывает несуществующую статью или приписывает слова реальному человеку.
Подходы к детекции: 1. NLI-based (Natural Language Inference) — берём модель NLI (например, DeBERTa, обученную на MNLI) и проверяем: «следует ли утверждение модели из источника?» Три класса: entailment (подтверждается), contradiction (противоречит), neutral (не упоминается). Работает для RAG — проверяем каждое утверждение ответа против retrieved documents. 2. Self-consistency — задаём один вопрос модели несколько раз (temperature > 0). Если ответы сильно расходятся — модель не уверена, вероятность галлюцинации высокая. 3. Citation verification — модель генерирует ответ со ссылками на источники. Проверяем: действительно ли источник содержит указанную информацию? 4. Factual consistency scoring — специализированные модели (SummaC, AlignScore, HHEM) обучены оценивать factual consistency между текстом и источником.
Data contamination: когда бенчмарки врут
Если метрика становится целью, она перестаёт быть хорошей метрикой (закон Гудхарта). Для LLM-бенчмарков это буквально: модели обучают на триллионах токенов из интернета, и тестовые данные бенчмарков утекают в pretraining корпус. Модель не «решает» задачу — она её «вспоминает».
Масштаб проблемы: исследования показывают, что значительная часть примеров MMLU, GSM8K и HumanEval встречается в training data популярных моделей. Результат — завышенные метрики, которые не отражают реальные способности.
Как обнаруживают contamination: 1. N-gram overlap — ищем точные совпадения n-грамм (8-13 слов) между тестовыми примерами и training data. Простой, но требует доступа к training data. 2. Canary strings — вставляем в eval set уникальные строки. Если модель их «знает» — значит, видела в training. 3. Perplexity analysis — если модель показывает аномально низкий perplexity на тестовых примерах (по сравнению с похожими, но новыми) — вероятно видела их. 4. Temporal splits — используем данные, созданные после cutoff-даты модели. LiveCodeBench обновляется ежемесячно, Chatbot Arena — в реальном времени.
Как защититься от contamination
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Оценка LLM — это пирамида: публичные бенчмарки → domain eval set → LLM-as-Judge → A/B тест. Каждый уровень дороже, но точнее. Не пропускай нижние — они экономят недели на верхних.
Если запомнить одну вещь: никакой бенчмарк не заменит eval на твоих данных. 50 хорошо подобранных примеров с rubric + автоматический прогон + LLM-judge — это минимальный stack, который отделяет инженерный подход от vibes-based evaluation.
Галлюцинации — не баг, а свойство. Contamination — не edge case, а системная проблема. Оба нужно учитывать при интерпретации любых результатов, будь то публичный лидерборд или собственный eval.
Дальше на роадмапе: RAG покажет, как строить системы с retrieval (и как оценивать их faithfulness), а промпт-инжиниринг — как итерировать промпты с помощью eval pipeline.
Материалы
Главный лидерборд open-source LLM. Полезен для первичного скрининга моделей.
Пользователи голосуют за лучший ответ. Самый надёжный индикатор общего качества chat-моделей.
Оригинальная статья MT-Bench и LLM-as-a-Judge. Показывает корреляцию с человеческими оценками.
Стандартный фреймворк для запуска бенчмарков LLM. Используется в Open LLM Leaderboard.
Практический гайд: бенчмарки, LLM-as-judge, human eval, eval pipelines.
Обзор типов галлюцинаций, методов детекции и mitigation strategies.