RAG
Retrieval-Augmented Generation: чанкинг, эмбеддинги, реранкинг, гибридный поиск.
RAG — Retrieval-Augmented Generation
Загрузка интерактивного виджета...
LLM уверенно отвечает на вопросы — даже когда не знает ответа. Это называется галлюцинация: модель генерирует правдоподобный, но ложный ответ, потому что обучена предсказывать следующий токен, а не проверять факты. Кроме того, знания модели заморожены на момент обучения — она не знает, что произошло вчера. И у неё точно нет твоих внутренних документов, регламентов или переписки в Slack.
RAG (Retrieval-Augmented Generation) решает эти проблемы элегантно: вместо того чтобы надеяться на память модели, мы ищем релевантные документы и подсовываем их в промпт. Модель генерирует ответ, опираясь на конкретный контекст — а не на свои «воспоминания» об обучающих данных.
Аналогия: экзамен с открытой книгой. Ты не зубрил весь учебник наизусть, но знаешь, как быстро найти нужную страницу и сформулировать ответ на её основе. RAG превращает LLM из студента, который угадывает ответы, в студента, который умеет пользоваться справочниками.
Три причины, почему RAG стал стандартом в продакшене: 1. Актуальность. Документы обновляются без переобучения модели — просто обнови индекс. 2. Приватность. Внутренние данные остаются на твоих серверах, не нужно отправлять их в OpenAI для fine-tuning. 3. Верифицируемость. Модель ссылается на конкретные документы — можно проверить ответ, перейдя к источнику.
Большая картина: от вопроса до ответа за 4 шага
RAG — это pipeline из четырёх шагов, и каждый шаг можно улучшать независимо: Шаг 1. Query — пользователь задаёт вопрос: «Какие сроки по договору №42?» Шаг 2. Retrieve — система ищет релевантные фрагменты (чанки) из базы знаний. Это может быть vector search, BM25 или их комбинация. Результат: top-K чанков, наиболее похожих на вопрос. Шаг 3. Augment — найденные чанки вставляются в промпт вместе с оригинальным вопросом. Промпт выглядит так: «Вот контекст: [чанки]. Ответь на вопрос: [вопрос]. Используй ТОЛЬКО информацию из контекста.» Шаг 4. Generate — LLM генерирует ответ, опираясь на подставленный контекст.

Но прежде чем поиск заработает, нужно проиндексировать документы. Это отдельный pipeline, который запускается заранее (offline).
Indexing pipeline: от документов до вектороного хранилища
Индексирование — это подготовительная фаза, которая превращает сырые документы в структуру, пригодную для быстрого поиска. Pipeline выглядит так:
1. Загрузка документов — PDF, HTML, Markdown, Notion, Confluence, Google Docs. На этом этапе используются парсеры (loaders): PyMuPDF для PDF, BeautifulSoup для HTML. Качество парсинга — критически важно: если таблица превратилась в кашу из текста, никакой retrieval не поможет.
2. Chunking — документ разбивается на фрагменты (чанки). Это ключевое архитектурное решение, от которого зависит всё. Подробнее — в следующей секции.
3. Embedding — каждый чанк превращается в числовой вектор фиксированной длины (обычно 384-1536 измерений). Для этого используется embedding-модель — sentence-transformer, OpenAI text-embedding-3, E5, BGE.
4. Vector Store — векторы записываются в хранилище, оптимизированное для быстрого поиска ближайших соседей. Варианты: FAISS (in-memory, быстрый), Chroma (простой, для прототипов), Pinecone/Weaviate/Qdrant (managed, для прода).
Важный момент: embedding-модель для документов и запросов должна быть одна и та же. Если индексировал документы через text-embedding-3-small, запросы тоже нужно эмбеддить через неё — иначе векторы живут в разных пространствах и cosine similarity бессмысленна.
Chunking — как правильно нарезать документы
Нельзя засунуть PDF на 200 страниц целиком в контекст — нужно разбить на чанки. Это самое важное архитектурное решение в RAG: плохой чанкинг убивает систему, независимо от модели и поиска.
Аналогия: ты готовишь шпаргалки к экзамену. Если выписал на каждую карточку по одному слову — не хватит контекста. Если скопировал целую главу — не найдёшь нужное. Идеал — карточка, которая содержит один законченный смысловой блок: определение, пример, формулу.

Fixed-size chunking — самый простой подход. Режем по N токенов (обычно 256-512) с перекрытием (overlap). Плюсы: предсказуемый размер, легко реализовать. Минус: может разрезать предложение или абзац пополам, уничтожив смысл.
Recursive chunking (LangChain RecursiveCharacterTextSplitter) — пытается резать «по границам»: сначала по двойному переносу строки (\n\n), потом по одинарному (\n), потом по предложениям, потом по словам. Уважает структуру текста. Это рабочая лошадка большинства RAG-систем.
Semantic chunking — группирует предложения по эмбеддинг-сходству. Чанк заканчивается, когда тема резко меняется (cosine distance между соседними предложениями превышает порог). Дороже, но умнее — каждый чанк содержит один смысловой блок.
По структуре документа — для документов с чёткой структурой (HTML, Markdown, юридические контракты). Разбиваем по заголовкам, таблицам, спискам. Требует знания формата, но даёт отличные результаты.
Overlap (перекрытие) — критически важный параметр. Без overlap контекст «обрезается» на границах: если ответ на вопрос находится на стыке двух чанков, оба чанка содержат только половину информации. Overlap 10-20% решает эту проблему — соседние чанки делят общий фрагмент текста.
Как выбрать размер чанка
Retrieval: как искать релевантные чанки
Retrieval — это этап, на котором система находит K наиболее релевантных чанков для данного запроса. Существует три подхода к поиску, каждый с разными сильными сторонами.
Dense retrieval (vector search). Запрос и документы превращаются в векторы, и поиск идёт по косинусному сходству или L2-расстоянию. Это семантический поиск: «как починить кран» найдёт «ремонт сантехники», даже если слова не совпадают. Для этого нужна embedding-модель.
• Плюс: ловит смысл, а не слова.
• Минус: может «промазать» на точных терминах (артикулы, имена, коды ошибок).
• Модели: text-embedding-3-small (OpenAI), multilingual-e5-large (open-source), all-MiniLM (быстрый).
Sparse retrieval (BM25). Классический алгоритм информационного поиска. Работает на уровне слов: подсчитывает TF-IDF-подобные веса и ранжирует документы по совпадению терминов.
• Плюс: отлично работает для точных совпадений (артикул A-12345, имя Иванов И.И.).
• Минус: не понимает семантику. «Ремонт водопровода» ≠ «починить кран».
• Реализации: Elasticsearch, Lucene, rank_bm25 (Python).
Hybrid search — комбинирует dense и sparse. Каждый метод возвращает свой ранжированный список, затем списки объединяются. Стандартный способ объединения — Reciprocal Rank Fusion (RRF):
Для каждого документа d: score(d) = Σ 1/(k + rank_i(d)), где rank_i — позиция d в i-м списке, k — константа (обычно 60). RRF не требует калибровки скоров — работает только с позициями, что делает его устойчивым к разным масштабам.
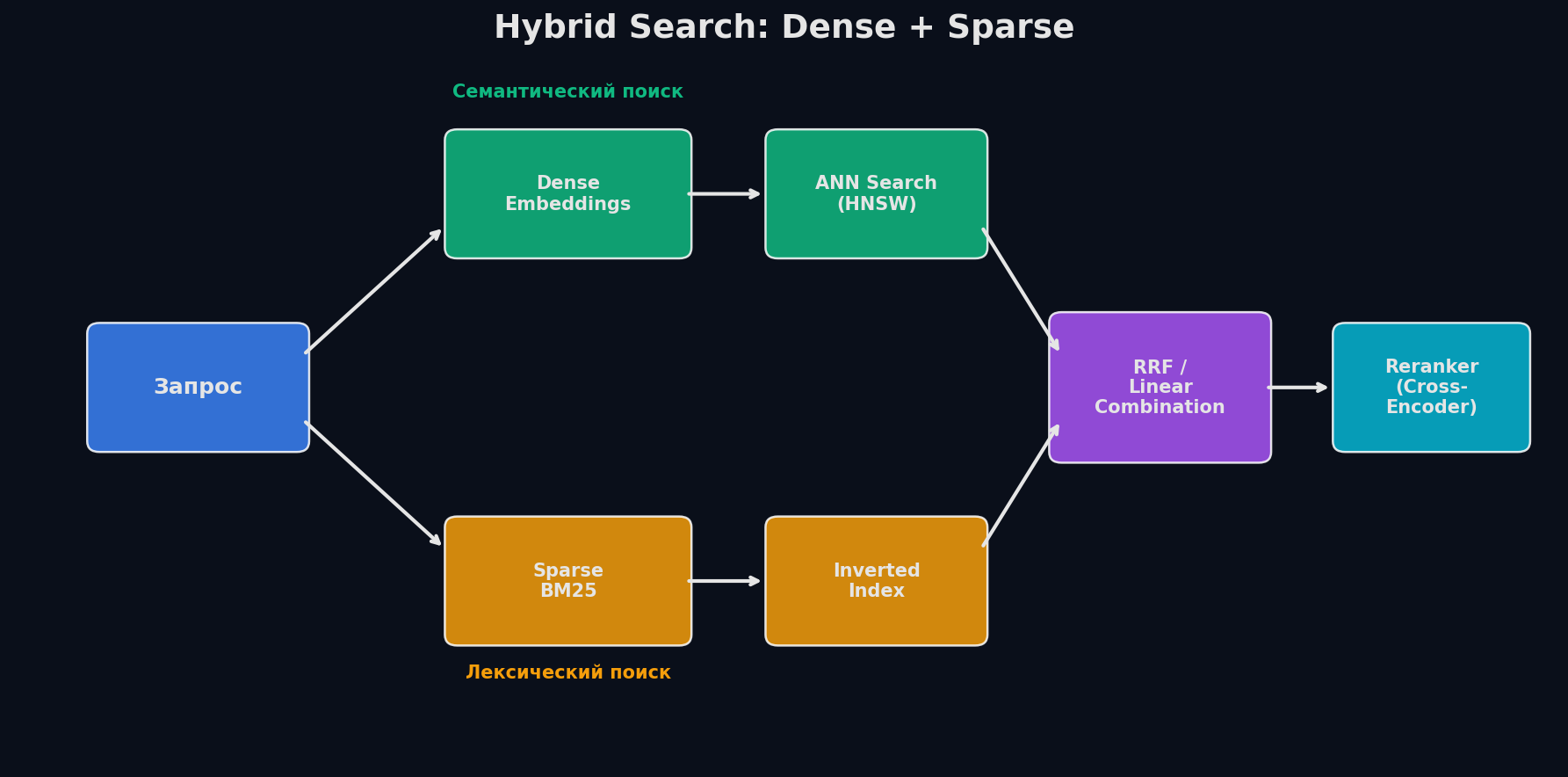
Reranking — второй этап поиска
Embedding-модель (bi-encoder) быстро ищет top-100 из миллионов документов, но грубо — она независимо эмбеддит запрос и документ, не видя их вместе. Cross-encoder (reranker) берёт пару (запрос, документ) и точно оценивает релевантность, видя их одновременно. Но он медленный — O(n) прямых проходов.
Решение — двухэтапный pipeline: bi-encoder для recall (быстро отобрать 50-100 кандидатов) → cross-encoder для precision (точно переранжировать top-K). Модели-реранкеры: cross-encoder/ms-marco-MiniLM-L-6-v2, Cohere Rerank, bge-reranker-v2.
Generation: как сформировать промпт с контекстом
Retrieval нашёл чанки, теперь нужно правильно передать их модели. Промпт для RAG обычно состоит из трёх частей:
system_prompt = "" , .
:
1. .
2. "Я не нашёл ответ в документации".
3. : [: ].
""
user_prompt = f"":
{chunk_1}
---
{chunk_2}
---
{chunk_3}
: {user_question}""Ключевые принципы формирования промпта: • Инструкция «отвечай только по контексту» — без неё модель будет дополнять ответы своими знаниями, а это именно то, от чего мы уходим. • Порядок чанков важен. LLM лучше используют информацию из начала и конца промпта, хуже — из середины (эффект «Lost in the Middle»). Размещай самые релевантные чанки первыми. • Не перегружай контекст. 3-5 чанков обычно достаточно. Чем больше контекста — тем выше вероятность, что модель «утонет» в нём и выдернет нерелевантный кусок. • Просить ссылки на источники — пользователь должен иметь возможность проверить ответ.
Оценка RAG: RAGAS-метрики
RAG — это система из двух частей (retrieval + generation), и ошибки могут быть в обеих. Нужны метрики, которые диагностируют, где именно проблема. Фреймворк RAGAS (RAG Assessment) предлагает четыре ключевых метрики:
Faithfulness — ответ модели основан на контексте, а не выдуман? LLM-судья разбивает ответ на утверждения (claims) и проверяет, поддерживается ли каждое утверждение контекстом. faithfulness = supported_claims / total_claims. Низкий faithfulness → модель галлюцинирует несмотря на контекст.
Answer Relevancy — ответ отвечает на заданный вопрос? LLM генерирует N вопросов по ответу и считает cosine similarity с оригинальным вопросом. Низкий → ответ ушёл в сторону (модель «зацепилась» за нерелевантный чанк).
Context Precision — среди найденных чанков нет мусора? Какая доля top-K чанков реально релевантна вопросу. Низкий precision → retrieval возвращает нерелевантные чанки, засоряющие контекст.
Context Recall — retrieval нашёл всё нужное? Какая доля утверждений из эталонного ответа подтверждается найденными чанками. Низкий recall → retrieval пропускает важные документы.
Как использовать метрики для диагностики: • Низкий context recall → проблема в retrieval: плохой чанкинг, слабая embedding-модель, нужен hybrid search. • Низкий context precision → retrieval находит мусор: нужен reranking или лучший чанкинг. • Низкий faithfulness при хорошем retrieval → проблема в generation: модель игнорирует контекст, нужна лучшая инструкция в промпте или более мощная модель. • Низкая answer relevancy → модель «отвлекается»: возможно, чанки нерелевантны или промпт сформулирован плохо.
Продвинутые техники RAG
Базовый RAG (naive RAG) — это «один запрос → один поиск → один ответ». Он работает для простых случаев, но ломается на сложных вопросах. Вот техники, которые выводят RAG на следующий уровень:
Multi-Query. Один вопрос пользователя переформулируется в несколько вариантов с помощью LLM. «Какие сроки по договору?» → [«дедлайн контракт», «срок действия соглашения», «дата окончания договора»]. По каждому варианту идёт поиск, результаты объединяются. Это повышает recall: разные формулировки цепляют разные чанки. HyDE (Hypothetical Document Embeddings). LLM генерирует гипотетический ответ на вопрос (без контекста), затем ищет чанки, похожие на этот гипотетический ответ, а не на оригинальный вопрос. Интуиция: ответ ближе к документу в embedding-пространстве, чем вопрос. Пример: вопрос «что такое LoRA?» → гипотетический ответ «LoRA — метод PEFT, добавляющий низкоранговые матрицы…» → поиск по этому тексту. Parent Document Retriever. Ищем по маленьким чанкам (256 токенов — высокая точность поиска), но в контекст отдаём большой родительский чанк (1024+ токенов — достаточно контекста). Best of both worlds: точный поиск + полный контекст. Self-RAG. Модель сама решает, нужен ли ей retrieval. Для фактического вопроса («какая площадь России?») — да, ищем. Для рассуждения («объясни, почему небо голубое») — нет, хватит собственных знаний. Модель обучается генерировать специальные токены: [Retrieve], [IsRelevant], [IsSupported].
Практический пример: RAG-pipeline с нуля
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
# 1. Загружаем и чанкуем документы
loader = PyMuPDFLoader("contract.pdf")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=512, chunk_overlap=64, separators=["\n\n", "\n", ". ", " "]
)
chunks = splitter.split_documents(docs)
# chunks → [Document(page_content="Срок действия договора...", metadata={page: 3}), ...]
# 2. Индексируем: embedding → vector store
db = FAISS.from_documents(chunks, OpenAIEmbeddings(model="text-embedding-3-small"))
retriever = db.as_retriever(search_kwargs={"k": 5})
# 3. Формируем RAG-chain
prompt = ChatPromptTemplate.from_template(
"Контекст:\n{context}\n\nВопрос: {question}\n"
"Ответь на основе контекста. Если ответа нет — скажи, что не нашёл."
)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| ChatOpenAI(model="gpt-4o-mini", temperature=0)
)
# 4. Задаём вопрос
answer = chain.invoke("Какие сроки действия договора?")
print(answer.content)Типичные проблемы RAG в продакшене
RAG в демо работает за вечер. RAG в проде — месяцы итераций. Вот проблемы, с которыми сталкивается каждая команда:
1. Retrieval не находит релевантное. Пользователь спрашивает «сроки оплаты», а в чанках это сформулировано «платёжные обязательства исполняются не позднее…». Embedding-модель не связывает эти формулировки. Решения: hybrid search (BM25 поймает «сроки» + «оплаты»), multi-query (переформулировать запрос), fine-tuning embedding-модели на доменных данных. 2. Слишком много контекста (noise). Retrieval вернул 10 чанков, из которых только 2 релевантны. Модель «тонет» в мусоре. Решения: уменьшить K (top-3 вместо top-10), добавить reranking, улучшить чанкинг. 3. Hallucination despite context. Модель видит правильный контекст, но всё равно выдумывает. Это происходит, когда контекст противоречит «убеждениям» модели (из pre-training) или когда инструкция в промпте недостаточно жёсткая. Решения: усилить system prompt («ТОЛЬКО на основе контекста»), использовать более мощную модель, добавить faithfulness check. 4. Garbage in, garbage out. Плохой парсинг PDF: таблицы превращаются в кашу, сноски вклиниваются в текст, заголовки теряются. Это ломает и чанкинг, и retrieval. Решения: специализированные парсеры (Unstructured, LlamaParse), ручная проверка качества. 5. Lost in the Middle. LLM хуже используют информацию из середины длинного промпта. Если ответ в третьем из пяти чанков — модель может его «не заметить». Решение: сортировать чанки по релевантности (самый важный — первый), ограничивать количество чанков.
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
RAG — это архитектурный паттерн, который компенсирует ключевые ограничения LLM: устаревшие знания, галлюцинации и отсутствие приватных данных. Pipeline: документы → chunking → embedding → vector store (офлайн индексирование) и query → retrieve → augment prompt → generate (онлайн inference).
Качество RAG определяется двумя осями: retrieval (находим ли мы нужные документы?) и generation (использует ли модель контекст правильно?). RAGAS-метрики помогают диагностировать, где именно проблема. Продвинутые техники (hybrid search, reranking, multi-query, HyDE) итеративно улучшают обе оси.
Если запомнить одну вещь: RAG — это не алгоритм, а pipeline. Каждый компонент (chunking, embedding, retrieval, prompt, model) можно улучшать независимо. Начни с простого (fixed chunks + OpenAI embeddings + top-5), измерь качество на 50 вопросах вручную, и усложняй только то, что ломается.
Связанные темы на роадмапе: Embedding-модели и BERT — backbone для dense retrieval, Prompt Engineering — как формировать промпт для generation, LLM Fine-tuning — альтернатива RAG, когда нужно изменить поведение модели.
Материалы
Пошаговое построение RAG-пайплайна с нуля. 14 коротких видео, каждое — отдельный компонент.
Фреймворк для оценки качества RAG: faithfulness, relevance, context precision/recall.
Обзорная статья по RAG: архитектуры, методы, evaluation. Хорошая таксономия advanced RAG.
Продвинутые техники: reranking, query decomposition, routing, agentic RAG.
Модель сама решает, когда нужен retrieval. Ключевая статья по adaptive RAG.
Интерактивный инструмент для визуализации разных стратегий чанкинга на реальных текстах.