BERT
Masked LM, NSP, файнтюнинг, варианты: RoBERTa, ALBERT, DistilBERT.
BERT — модель, которая научила NLP переиспользовать знания
До 2018 года для каждой NLP-задачи строили отдельную модель с нуля: свою архитектуру для классификации, свою для NER, свою для QA. Предобученные Word2Vec/GloVe давали хорошие эмбеддинги слов, ELMo — контекстные представления, но саму модель каждый раз нужно было проектировать заново.
BERT (Bidirectional Encoder Representations from Transformers, Google 2018) изменил парадигму радикально: вместо «новая модель под каждую задачу» — одна предобученная модель + лёгкая адаптация. Идея простая: сначала модель читает гигабайты текста и выучивает «понимание языка» (pre-training), потом за несколько эпох на маленьком датасете адаптируется к конкретной задаче (fine-tuning). Как человек: сначала ты учишь язык годами, а потом быстро осваиваешь новую тему.
Результат — SOTA на 11 бенчмарках одновременно. Парадигма pretrain → fine-tune стала стандартом и привела к появлению GPT, T5, LLaMA и всего современного NLP.
Большая картина: что такое BERT за 60 секунд
BERT — это encoder-only трансформер. В отличие от GPT (decoder-only), у BERT нет генерации текста. Его суперсила — понимание: каждый токен видит контекст и слева, и справа одновременно (двунаправленность / bidirectional).
Жизненный цикл BERT в 3 шага: Шаг 1. Pre-training. Берём неразмеченный текст (Wikipedia + BookCorpus, ~16 ГБ). Обучаем на двух задачах: MLM (угадай замаскированные слова) и NSP (идут ли предложения подряд). Модель выучивает грамматику, семантику, факты о мире — общее «понимание языка». Шаг 2. Fine-tuning. Берём предобученную модель, добавляем сверху один линейный слой под свою задачу (классификация, NER, QA). Дообучаем всю модель на маленьком датасете (тысячи примеров, 2-4 эпохи). Готово. Шаг 3. Inference. Используем fine-tuned модель в продакшене.
![BERT pre-training: MLM маскирует токены [MASK], модель предсказывает замаскированные слова используя контекст с обеих сторон](/images/roadmap/bert-pretraining.png)


Encoder-only vs Decoder-only
Архитектура: что внутри BERT
BERT — это стек Transformer encoder блоков (подробнее в ноде Transformer). Две основные конфигурации:
- BERT-base: 12 слоёв, hidden size 768, 12 голов attention, 110M параметров
- BERT-large: 24 слоя, hidden size 1024, 16 голов attention, 340M параметров
Входной формат. BERT принимает одно или два предложения: [CLS] sent_A [SEP] sent_B [SEP]. • [CLS] — специальный токен в начале. Его выходной вектор используется как представление всего текста (для классификации). • [SEP] — разделитель предложений. • Токенизация: WordPiece со словарём ~30K токенов. Незнакомые слова разбиваются на подслова: «играющий» → «играющ» + «##ий».
Каждый токен получает три эмбеддинга, которые складываются поэлементно: 1. Token embedding — вектор токена из словаря 2. Segment embedding — E_A для первого предложения, E_B для второго (нужно для задач с парами) 3. Position embedding — обучаемый вектор позиции (0..511). В отличие от оригинального трансформера, здесь позиции learnable, а не синусоидальные
# Входной формат BERT
# input_ids: [CLS]=101, "кот"=2345, "спит"=6789, [SEP]=102, "тепло"=4321, [SEP]=102
# token_type_ids: [ 0, 0, 0, 0, 1, 1 ]
# position_ids: [ 0, 1, 2, 3, 4, 5 ]
embedding = token_emb(input_ids) + segment_emb(token_type_ids) + position_emb(position_ids)
# Результат: [batch, seq_len, 768] → вход в 12 слоёв трансформераMasked Language Model (MLM) — главная задача pre-training
Как научить модель понимать текст двунаправленно? Нельзя просто предсказывать следующее слово (как GPT) — модель «подсмотрит» ответ через правый контекст. Решение BERT — маскирование: спрячь часть слов и попроси модель восстановить их.
Аналогия: тест на знание языка, где в тексте пропущены слова. «Кот ___ на диване» — тебе нужно понять из контекста с обеих сторон, что пропущено «спит». Именно так учится BERT.
Алгоритм: случайно выбираем 15% токенов для предсказания. Но не все 15% становятся [MASK]:
- 80% → [MASK]: стандартная маскировка — «Кот [MASK] на диване»
- 10% → случайный токен: замена на рандомное слово — «Кот *банан* на диване»
- 10% → оставляем как есть: ничего не меняем — «Кот спит на диване»
Зачем такая сложная схема 80/10/10? Проблема: токен [MASK] никогда не встречается при fine-tuning — в реальных данных его нет. Если бы модель видела [MASK] только при pre-training, она бы научилась отдельному поведению для [MASK] и для реальных токенов.
- 10% random заставляет модель не полагаться на присутствие [MASK] — иногда на маскированной позиции стоит реальное (но неправильное) слово, и модель всё равно должна восстановить оригинал
- 10% same заставляет модель строить хорошие представления для всех токенов — она не знает, какие позиции маскированы, значит должна хорошо кодировать каждый токен на всякий случай
Loss считается только на маскированных 15% позициях. Остальные токены — контекст. Это стандартная cross-entropy между предсказанным распределением по словарю и реальным токеном.
# MLM masking — реальная логика
import torch
def mask_tokens(input_ids, tokenizer, mlm_prob=0.15):
labels = input_ids.clone()
# Выбираем 15% позиций
mask = torch.bernoulli(torch.full(labels.shape, mlm_prob)).bool()
labels[~mask] = -100 # loss только на маскированных позициях
# 80% → [MASK]
replace_mask = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & mask
input_ids[replace_mask] = tokenizer.mask_token_id
# 10% → случайный токен
random_mask = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & mask & ~replace_mask
input_ids[random_mask] = torch.randint(len(tokenizer), labels.shape)[random_mask]
# 10% → оставляем как есть (ничего не делаем)
return input_ids, labelsNext Sentence Prediction (NSP) — вторая задача, которая оказалась лишней
Вторая задача pre-training — Next Sentence Prediction. Модель получает два предложения и бинарно классифицирует: идёт ли sent_B сразу после sent_A в тексте (IsNext, 50%) или это случайная пара (NotNext, 50%). Классификация — через вектор [CLS] → линейный слой → softmax.
Суммарный loss pre-training: L = L_MLM + L_NSP.
Почему NSP убрали в RoBERTa? Задача оказалась слишком простой. Случайное предложение обычно про совсем другую тему — модель учится различать топики, а не логическую связь между предложениями. RoBERTa (2019) показала: без NSP результаты даже лучше — модель тратит capacity на полезный MLM вместо тривиальной классификации.
Fine-tuning — одна модель, любая задача
В этом красота BERT: один и тот же предобученный backbone адаптируется к десяткам задач добавлением простой «головы» (classification head) сверху. Вся модель дообучается end-to-end: и head, и BERT. Обычно хватает 2-4 эпохи на датасете из пары тысяч примеров.

- Классификация текста — вектор [CLS] → линейный слой → softmax по классам. Sentiment, spam, topic classification
- NER (Named Entity Recognition) — выход каждого токена → линейный слой → метка (B-PER, I-PER, O, …). Модель размечает сущности потокенно
- Question Answering (extractive) — вход: [CLS] вопрос [SEP] контекст [SEP]. Модель предсказывает позиции начала и конца ответа в контексте
- Sentence Pair tasks — NLI (entailment/contradiction/neutral), парафразы, semantic similarity: два предложения через [SEP], классификация по [CLS]
from transformers import BertForSequenceClassification, BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=3)
inputs = tokenizer("BERT revolutionized NLP", return_tensors="pt")
outputs = model(**inputs)
# outputs.logits: [1, 3] — по одному логиту на классSentence-BERT — от токенов к эмбеддингам предложений
BERT отлично работает с задачами на уровне токенов и пар предложений. Но что если нужен один вектор для всего текста — для поиска, кластеризации, дедупликации?
Наивный подход: взять вектор [CLS] или усреднить все токены. Проблема — эти представления не обучены для сравнения предложений. BERT оптимизирован на MLM, а не на то, чтобы похожие тексты были близко в пространстве. Ещё хуже: чтобы сравнить 10,000 документов попарно, нужно прогнать BERT 50 миллионов раз (все пары). При ~65ms на инференс — это ~65 часов.
Sentence-BERT (SBERT, 2019) решает обе проблемы. Архитектура — Siamese network: два BERT с общими весами. Каждое предложение независимо проходит через свою ветку:
- Текст → BERT → mean pooling по всем токенам → один вектор (768d)
- Mean pooling > [CLS] > max pooling — проверено экспериментально
- Обучение: contrastive / triplet / multiple negatives ranking loss на парах предложений
- Сравнение: cosine_similarity(emb_A, emb_B) — мгновенно, O(1)
- 10K документов: 10K прогонов BERT (~10 сек) + попарные cosine (~5 мс). Вместо 65 часов
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer('all-MiniLM-L6-v2') # лёгкая модель, 384d
sentences = ["Кот сидит на заборе", "Кошка забралась на ограду", "Сегодня хорошая погода"]
embeddings = model.encode(sentences) # shape: (3, 384)
sims = cos_sim(embeddings, embeddings)
# sims[0][1] ≈ 0.85 — кот/кошка похожи
# sims[0][2] ≈ 0.12 — кот/погода — нетГде используют: semantic search (поиск по смыслу), RAG retrieval (первый этап — найти релевантные чанки), кластеризация текстов, дедупликация (cosine > 0.95 → дубликат), STS (semantic textual similarity).
Семейство BERT — эволюция идеи
После BERT вышла серия моделей, каждая из которых улучшала один аспект. Архитектура оставалась encoder-only, но менялись training recipe, способ кодирования позиций и размер модели.
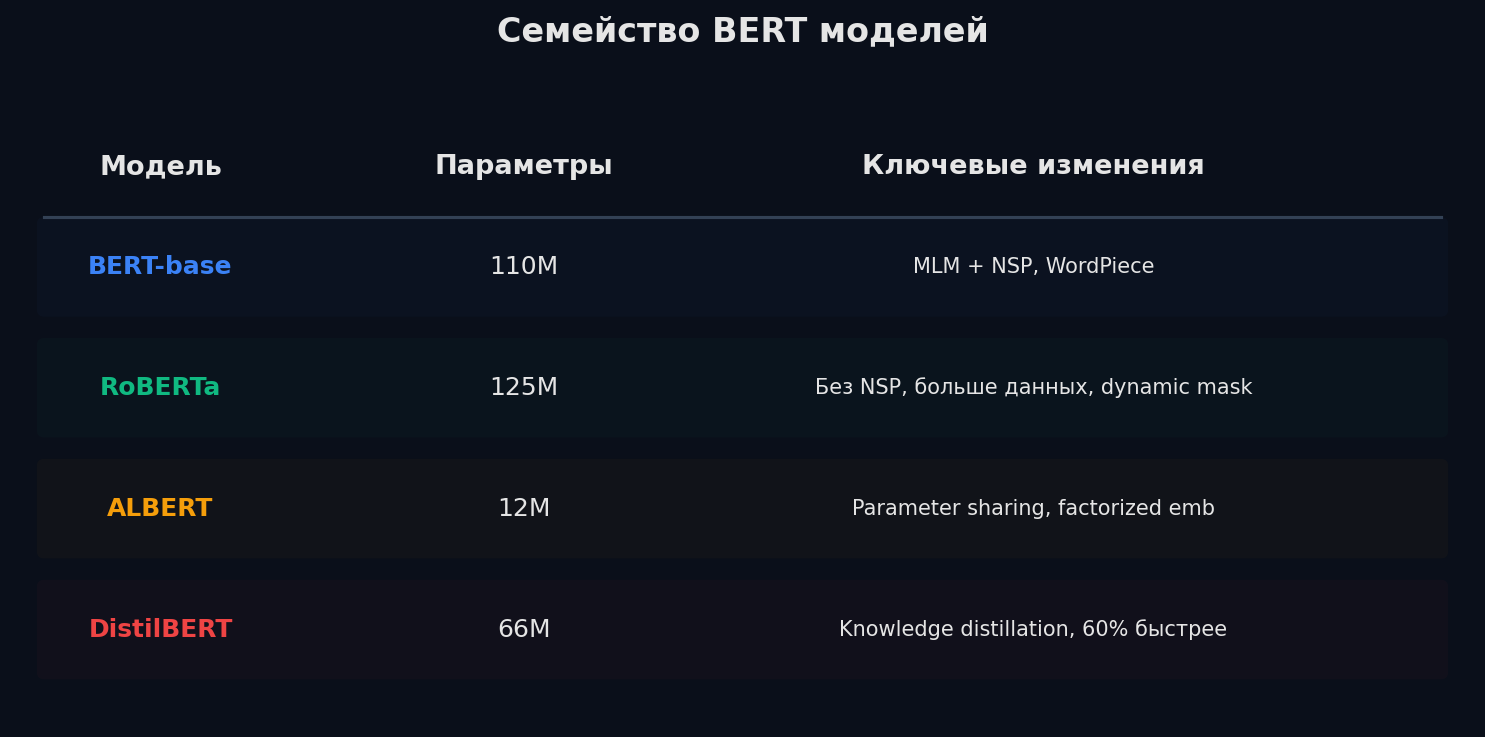
RoBERTa (2019) — «BERT был недотренирован»
Meta показала: никаких архитектурных изменений не нужно — достаточно правильного training recipe. Три ключевых отличия:
- Убрали NSP — бесполезная задача, тратит capacity модели
- Dynamic masking — маска генерируется заново каждую эпоху (в BERT — статическая, одна на весь датасет)
- 10× данных, 32× batch size, 5× дольше — 160 ГБ текста, batch 8K, 500K шагов. BERT просто остановили слишком рано
Результат: +2-4% на всех бенчмарках при том же размере модели. Мораль: данные и тренировка часто важнее архитектуры.
DeBERTa (2020) — disentangled attention
В BERT token embedding и position embedding складываются в один вектор — attention работает с суммой. DeBERTa (Microsoft) разделяет их: content и position — два отдельных вектора. Attention score считается как сумма трёх компонент: content↔content, content↔position, position↔content. Это позволяет модели явно моделировать, как содержание токена зависит от позиции другого.
DeBERTa v3 заменила MLM на RTD (Replaced Token Detection, как в ELECTRA) — генератор предлагает замены, дискриминатор определяет, какие токены ненастоящие. Эффективнее MLM, потому что loss считается на всех токенах, а не только на 15%.
microsoft/deberta-v3-base — state-of-the-art среди encoder-only моделей для NLU задач.
ALBERT и DistilBERT — компактные варианты
- ALBERT — параметры между слоями общие (cross-layer sharing) + factorized embedding. В 18× меньше параметров, качество почти то же. Идея: 12 слоёв выучивают похожие паттерны — зачем хранить 12 копий?
- DistilBERT — knowledge distillation: маленькая модель (student) учится имитировать soft outputs большой (teacher). 97% качества BERT при 60% размера и 2× скорости. Идеален для production
Современные эмбеддинги: E5, BGE — зачем, если есть SBERT
SBERT открыл дорогу, но у ранних моделей были ограничения: обучение на относительно маленьких NLI-датасетах, нет instruction-following. В 2023-2024 появились модели нового поколения:
- E5 (Microsoft) — обучен на сотнях миллионов пар «запрос-документ». Ключевая идея: instruction prefix — перед текстом добавляется инструкция:
"query: ..."или"passage: ...". Модель адаптирует эмбеддинг к типу задачи - BGE (BAAI) — аналогичный подход, сильные мультиязычные модели.
bge-m3поддерживает dense, sparse и multi-vector retrieval одновременно - GTE, Jina, Nomic — другие сильные embedding-модели, каждая со своими фишками (длинный контекст до 8K токенов, Matryoshka embeddings с гибкой размерностью)
Зачем новые модели, если есть SBERT? Три причины: (1) обучение на порядки больших данных, (2) instruction-aware эмбеддинги — модель «понимает», для чего нужен вектор (поиск? кластеризация?), (3) лучшая мультиязычность. На бенчмарке MTEB (Massive Text Embedding Benchmark) E5 и BGE уверенно обходят классический SBERT.
Ограничения BERT
- 512 токенов — максимальная длина входа. Для длинных документов нужно: разбивать на чанки, использовать Longformer/BigBird, или переходить на модели с длинным контекстом
- Нет генерации — BERT не умеет генерировать текст. Для этого нужен decoder (GPT) или encoder-decoder (T5)
- [MASK] train-test mismatch — при pre-training модель видит [MASK], при fine-tuning — нет. Схема 80/10/10 смягчает, но не устраняет проблему полностью
- Статический MLM — каждый [MASK] предсказывается независимо. Модель не учитывает зависимости между маскированными токенами (в отличие от XLNet)
- Дата обучения — знания BERT заморожены на момент pre-training. Нет доступа к свежей информации (в отличие от RAG-систем)
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
BERT ввёл парадигму, которая определила современный NLP: pretrain на огромном корпусе → fine-tune на маленьком датасете. Encoder-only архитектура + MLM позволяют каждому токену «видеть» весь контекст, что делает BERT идеальным для задач понимания текста.
Если запомнить одну вещь из этой ноды: BERT = двунаправленный encoder, который сначала учится понимать язык (MLM), а потом адаптируется к любой задаче (fine-tuning). RoBERTa показала, что тренировка важнее архитектуры. DeBERTa улучшила архитектуру. SBERT научил получать эмбеддинги предложений. E5/BGE довели эмбеддинги до production-уровня.
Дальше на роадмапе: GPT — decoder-only модель для генерации, и LLM Fundamentals — как масштабировать трансформеры до сотен миллиардов параметров.
Материалы
Контекст pretrain → fine-tune: от ELMo до BERT с интерактивными объяснениями.
Визуальное объяснение BERT: MLM, NSP, fine-tuning с картинками.
Оригинальная статья Google. 15 страниц, читается за час.
SBERT: siamese BERT + pooling + contrastive/triplet loss для sentence embeddings.
Meta показывает, что BERT был недотренирован. Убрали NSP, добавили данные и тренировку.
Microsoft DeBERTa: disentangled attention + Enhanced Mask Decoder.
Документация sentence-transformers: модели, тренировка, примеры кода.
Сравнение всех embedding-моделей: E5, BGE, SBERT и других на 56 датасетах.
Разбор статьи BERT с объяснением ключевых решений.