Основы LLM
Как устроены LLM изнутри: decoder-only архитектура, KV-cache для быстрого инференса, квантизация (GGUF, GPTQ, AWQ) для запуска на consumer GPU. Фокус на практике: запустить, оценить, выбрать модель.
LLM Fundamentals — от трансформера к продакшену
GPT-2 (1.5B параметров, 2019) умел дописывать текст. GPT-3 (175B, 2020) внезапно научился решать задачи, которым его никто не учил: арифметику, перевод по примерам, рассуждения по цепочке. Этот скачок — emergent abilities — появляется, когда модель переходит некий порог масштаба. Маленькая модель не умеет ничего из этого, большая — вдруг умеет.
LLM (Large Language Model) — это decoder-only трансформер с миллиардами параметров, обученный на триллионах токенов текста. «Large» — не маркетинг, а суть: именно масштаб делает модель универсальной. GPT-4, LLaMA, Mistral, Qwen — архитектурно они почти идентичны. Различия — в данных, размере, и инженерных хаках для инференса. Эта нода — про то, как LLM устроены внутри и как их запускать эффективно.
Большая картина: путь от текстов интернета до ChatGPT
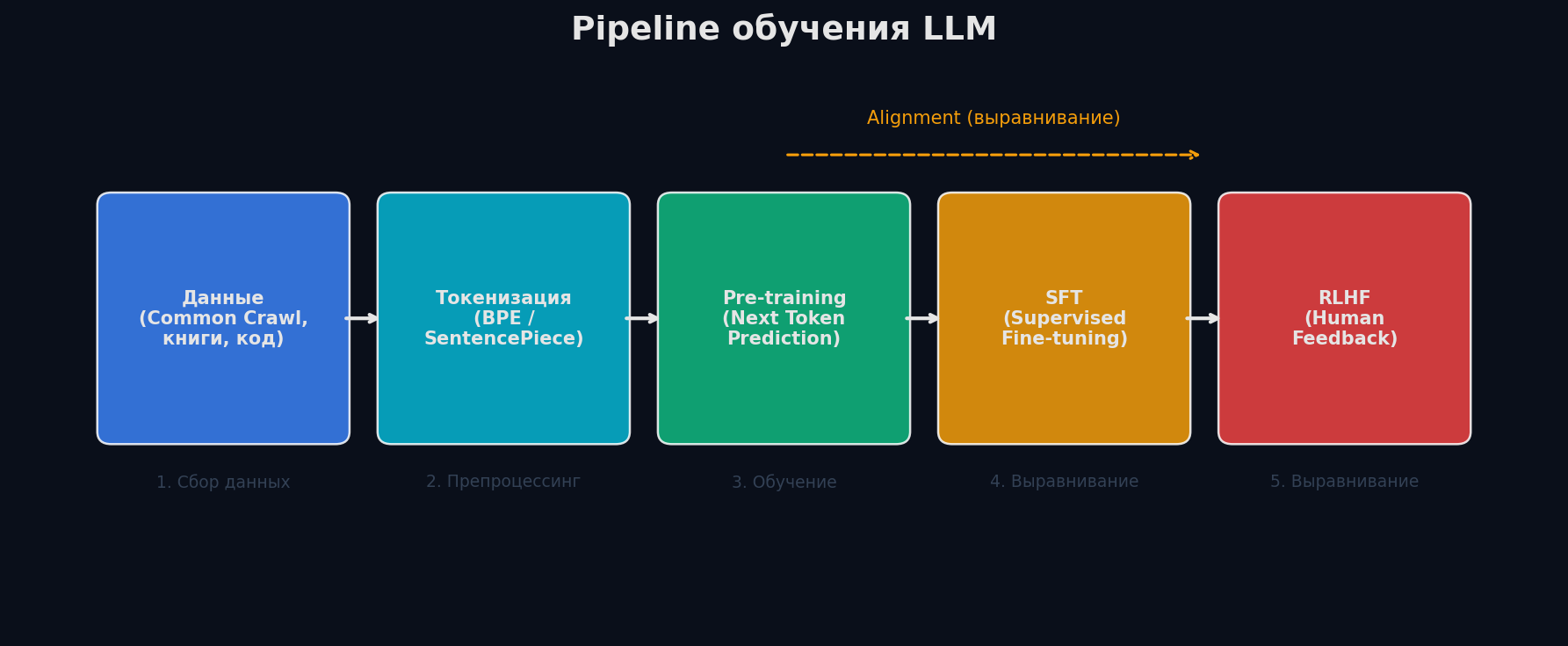
Жизненный цикл LLM — три фазы, каждая со своей задачей:
Фаза 1. Pre-training. Модель читает триллионы токенов (CommonCrawl, книги, код, Wikipedia) и учится предсказывать следующий токен. Задача: P(token_n | token_1, ..., token_{n-1}). На выходе — «база знаний», которая умеет продолжать текст, но не умеет вести диалог. Это самый дорогой этап: месяцы на тысячах GPU, миллионы долларов.
Фаза 2. Alignment (SFT + RLHF/DPO). Сначала Supervised Fine-Tuning на десятках тысяч пар «инструкция → ответ» — модель учится формату диалога. Затем RLHF или DPO — модель учится отвечать полезно и безопасно, ранжируя ответы по человеческим предпочтениям.
Фаза 3. Inference. Модель развёрнута и генерирует ответы пользователям. Здесь критичны скорость (tokens/sec), стоимость ($/1M tokens) и latency (time-to-first-token). Вся инженерная оптимизация — квантизация, KV-cache, batching — живёт здесь.
Архитектура: decoder-only трансформер изнутри
Все современные LLM — decoder-only трансформеры. Почему не encoder-decoder (как T5) и не encoder-only (как BERT)? Decoder-only оказался универсальным: одна архитектура и для генерации, и для «понимания» — через формулировку задач как продолжение промпта. Encoder не нужен, если всё можно свести к «продолжи текст».
Структура одного слоя LLaMA-подобной модели:
1. RMSNorm → Pre-Norm нормализация (стабильнее, чем Post-Norm из оригинального трансформера)
2. Grouped Query Attention (GQA) → causal self-attention с маской. Каждый токен видит только предыдущие
3. Residual connection → выход attention + вход
4. RMSNorm → нормализация перед FFN
5. SwiGLU FFN → нелинейная обработка: SwiGLU(x) = (xW₁ ⊙ Swish(xW_gate)) · W₂. Эмпирически лучше ReLU
6. Residual connection → выход FFN + вход
Таких слоёв — 32 (LLaMA-7B), 80 (LLaMA-70B), или 126 (LLaMA-405B).
Где живут параметры? В модели 7B примерный расклад: • Embedding-таблица: vocab_size × d_model = 32K × 4096 ≈ 0.13B параметров • Attention (Q, K, V, O проекции): 4 × d_model² × n_layers = 4 × 4096² × 32 ≈ 2.1B • FFN (W₁, W_gate, W₂): 3 × d_model × d_ff × n_layers = 3 × 4096 × 11008 × 32 ≈ 4.3B • Нормализация (RMSNorm): пренебрежимо мало • LM head: обычно tied с embedding-таблицей Итого: ~70% параметров в FFN, ~30% в attention. Это важно для понимания MoE и квантизации.

Токенизация: как текст становится числами
LLM не видит буквы или слова — она работает с токенами. Токен — это кусочек текста: целое слово («the»), часть слова («un» + «break» + «able»), или даже один символ. Токенизатор обучается отдельно от модели на большом корпусе текстов и создаёт словарь — фиксированный набор 32K-128K токенов.
BPE (Byte Pair Encoding) — самый популярный алгоритм. Идея проста: 1. Начинаем с алфавита символов (каждая буква = токен) 2. Считаем все пары соседних токенов в корпусе 3. Самую частую пару объединяем в новый токен 4. Повторяем пока не наберём нужный размер словаря Пример: «low» «lower» «lowest» → BPE выучит токен «low», потому что он встречается часто. Редкие слова разобьются на подтокены — модель никогда не встретит «unknown word».
SentencePiece (LLaMA, Mistral) работает на уровне байтов, не символов — ему не нужна предварительная токенизация по пробелам. Это критично для языков без пробелов (китайский, японский) и для работы с кодом.
Специальные токены: <BOS> (начало), <EOS> (конец), <PAD> (выравнивание), <|im_start|> / <|im_end|> (границы сообщений в chat-формате). Модель учит отдельный эмбеддинг для каждого.
from transformers import AutoTokenizer
tok = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
tokens = tok.encode("Квантизация ускоряет инференс")
print(tokens) # [1, 29945, 1386, ...] — числовые ID
print(tok.tokenize("Квантизация ускоряет инференс"))
# ['▁К', 'вант', 'из', 'ация', '▁уск', 'ор', 'яет', '▁ин', 'ференс']
print(f"Словарь: {tok.vocab_size} токенов") # 32000Почему размер словаря важен
Квантизация: как уместить модель на бюджетном железе
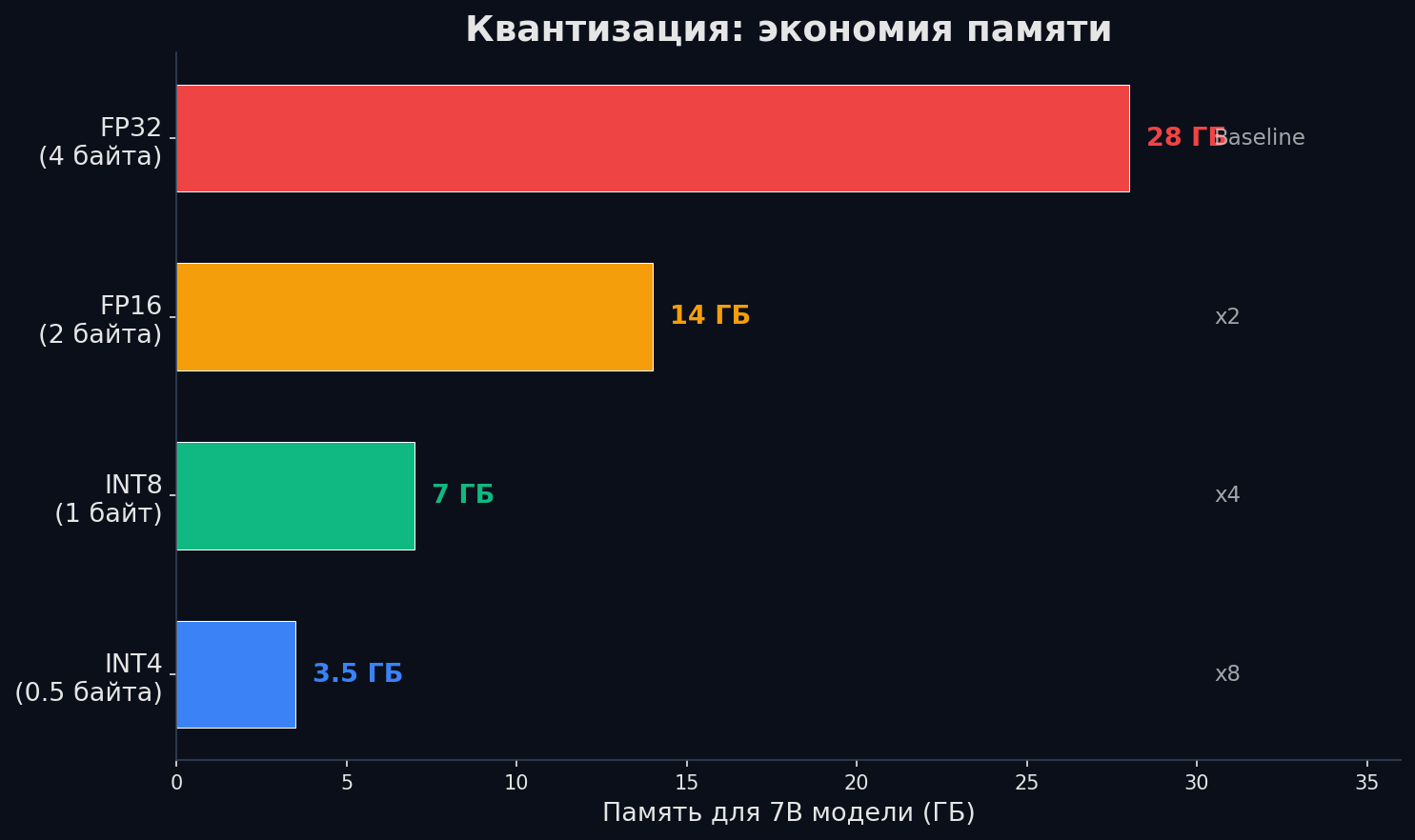
Модель 7B в FP16 — это 7 × 10⁹ × 2 байта = 14 ГБ только весов. RTX 4090 с 24 ГБ VRAM — еле тянет. А 70B модель? 140 ГБ — не влезет ни в одну потребительскую карту. Квантизация решает это: уменьшаем точность представления весов с 16 бит до 8 или 4.
Аналогия: фотография в RAW — 30 МБ, в JPEG — 3 МБ. Глаз почти не видит разницу, но файл в 10 раз меньше. Квантизация делает то же с весами модели: округляет float-числа до нескольких дискретных уровней.
Иерархия форматов: | Формат | Бит | Размер 7B | Качество | Когда использовать | |--------|-----|-----------|----------|-------------------| | FP32 | 32 | 28 ГБ | Эталон | Обучение (master weights) | | FP16/BF16 | 16 | 14 ГБ | ≈FP32 | Стандартный инференс | | INT8 | 8 | 7 ГБ | −0.5% | Инференс, когда GPU мало | | INT4 | 4 | 3.5 ГБ | −2-5% | Инференс на consumer GPU | BF16 (bfloat16) — как FP16, но с бо́льшим диапазоном за счёт точности. Предпочтителен для обучения на A100/H100.
Методы post-training квантизации:
• GPTQ — квантизует по одному слою, минимизируя ошибку реконструкции. Быстрый инференс на GPU. Требует калибровочный датасет (~128 примеров).
• AWQ (Activation-Aware) — сохраняет «важные» каналы (те, где активации имеют большие значения) в более высокой точности. Лучше GPTQ по качеству при том же размере.
• GGUF — формат для llama.cpp. Квантизация на CPU, можно гонять 7B-модели вообще без GPU. Идеален для локального инференса на ноутбуке.
• bitsandbytes — INT8 (LLM.int8()) и NF4 квантизация прямо в HuggingFace. Самый простой способ: model = AutoModelForCausalLM.from_pretrained(..., load_in_4bit=True).
KV-cache: почему генерация без кеша — катастрофа
LLM генерирует текст по одному токену: сгенерировал токен №5, добавил к контексту, генерирует №6. На каждом шаге модель считает self-attention ко всем предыдущим токенам. Без кеша на шаге N нужно заново вычислить K и V для всех N−1 прошлых токенов — это O(N²) суммарно на генерацию N токенов.
Аналогия: ты пишешь конспект лекции. Без KV-cache — каждый раз, когда нужно записать новое предложение, ты переслушиваешь всю лекцию с начала. С KV-cache — у тебя есть заметки (Key и Value) по каждой прошлой минуте, и ты просто обращаешься к ним.
Как работает KV-cache: 1. Prefill (первый проход): модель обрабатывает весь промпт целиком. Для каждого слоя сохраняем Key и Value всех токенов промпта. 2. Decode (генерация): на каждом шаге вычисляем Q, K, V только для нового токена. K и V — дописываем в кеш. Q нового токена перемножается с полным кешем K — получаем attention scores. Умножаем на кеш V — готово. 3. Результат: вместо O(N²) получаем O(N) на шаг — вычислений в N раз меньше.
Проблема: память. KV-cache растёт линейно с длиной контекста. Для LLaMA-7B (32 слоя, d_model=4096, FP16): KV-cache на 1 токен = 2 (K+V) × 32 (слоя) × 4096 (d_model) × 2 (байта) = 0.5 МБ Для контекста 4K токенов: 0.5 × 4096 ≈ 2 ГБ. Для 128K: 64 ГБ — больше, чем сама модель! Вот почему GQA (Grouped Query Attention) экономит K/V головы, а PagedAttention (vLLM) борется с фрагментацией памяти.
FlashAttention: тот же результат, в 2-4× быстрее
Стандартный self-attention вычисляет матрицу N×N (scores = QK^T), записывает её в HBM (основная память GPU), применяет softmax, снова записывает, умножает на V. Проблема не в вычислениях — GPU хватает FLOPS. Проблема в IO: чтение и запись N×N матрицы в медленную память.
Аналогия: ты считаешь на калькуляторе (быстро), но промежуточные результаты записываешь на бумажку (медленно). FlashAttention — это когда ты держишь промежуточные результаты в голове (SRAM — быстрая on-chip память GPU) и записываешь только финальный ответ.
Как работает FlashAttention: 1. Разбивает Q, K, V на блоки, помещающиеся в SRAM (on-chip memory, ~20 МБ) 2. Для каждого блока Q: загружает блоки K и V поочерёдно в SRAM 3. Считает attention внутри SRAM — без записи N×N матрицы в HBM 4. Аккумулирует результат с помощью online softmax (трюк: softmax можно считать инкрементально, блок за блоком) 5. Записывает в HBM только финальный output — O(N) вместо O(N²) по памяти Математически результат идентичен стандартному attention — это не аппроксимация. Ускорение чисто за счёт сокращения IO.
FlashAttention-2 улучшил параллелизм: итерирует по Q во внешнем цикле (Q можно распараллелить по GPU-потокам), K и V — во внутреннем. Результат: ~2× быстрее FlashAttention-1, до 4× быстрее стандартного attention. Включён по умолчанию в PyTorch 2.0+ (torch.nn.functional.scaled_dot_product_attention).
Serving: как обслуживать тысячи запросов
Запустить модель на одном GPU — несложно. Обслуживать 100 пользователей одновременно с latency < 1 секунды — инженерная задача. Три ключевые технологии:
1. Continuous Batching. Наивный подход: собрать батч из 8 запросов, дождаться пока все закончат генерацию, отправить ответы. Проблема: один запрос генерирует 10 токенов, другой — 500. Первый ждёт второго. Continuous batching (vLLM, TGI) решает это: как только запрос закончил генерацию, его сразу выкидывают из батча и на его место подставляют новый. GPU никогда не простаивает.
2. PagedAttention (vLLM). KV-cache для разных запросов в батче имеет разную длину — это создаёт фрагментацию памяти (как при динамическом выделении в C++). PagedAttention хранит KV-cache как виртуальные страницы (по аналогии с виртуальной памятью ОС): блоки фиксированного размера, разбросанные по GPU-памяти. Результат: до 24× больше throughput, на 60% меньше потерь памяти.
3. Tensor Parallelism. Модель 70B не помещается на одну GPU (140 ГБ FP16). Tensor parallelism разбивает каждый слой по нескольким GPU: например, матрицу W (d_model × d_ff) делят на 8 частей по столбцам — каждая GPU считает свою часть, затем результаты собираются через all-reduce. Альтернатива — Pipeline Parallelism: разные слои на разных GPU (но хуже для инференса из-за bubble time).
# vLLM: production-ready serving в 5 строк
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-chat-hf",
quantization="awq", # INT4 квантизация
tensor_parallel_size=1) # число GPU
params = SamplingParams(temperature=0.7, max_tokens=256)
outputs = llm.generate(["Объясни KV-cache простыми словами:"], params)
print(outputs[0].outputs[0].text)Стоимость инференса: считаем на салфетке
Расчёт памяти (VRAM):
Формула: VRAM ≈ параметры × байт/параметр + KV-cache
• 7B FP16: 7B × 2 = 14 ГБ (веса) + ~2 ГБ (KV-cache на 4K контекст) ≈ 16 ГБ
• 7B INT4: 7B × 0.5 = 3.5 ГБ + ~2 ГБ ≈ 5.5 ГБ → влезает в RTX 3060 12GB
• 70B FP16: 140 ГБ → нужно 2× A100 80GB или 8× RTX 4090
• 70B INT4: 35 ГБ + ~20 ГБ (KV, batch) → одна A100 80GB
Расчёт FLOPs на генерацию: Грубая оценка: на каждый токен нужно ~2 × P операций (P — число параметров). Для 7B модели: ~14 GFLOPs на токен. A100 выдаёт ~312 TFLOPS (FP16) → теоретический потолок: 312T / 14G ≈ 22K tokens/sec. На практике из-за memory bandwidth — 2-5K tokens/sec для одного запроса, больше с batching.
Стоимость API: GPT-4o: ~$2.50 / 1M input tokens, ~$10 / 1M output tokens. Для задачи RAG (5K input + 500 output tokens на запрос): ~$0.017 за запрос. 100K запросов в месяц: ~$1,700. Self-hosted LLaMA-70B на A100: ~$2/час × 730 часов ≈ $1,460/мес — сравнимо, но с полным контролем и без лимитов.
Практический пример: локальный инференс с квантизацией
# Вариант 1: llama.cpp через Python (CPU или GPU)
from llama_cpp import Llama
llm = Llama(
model_path="mistral-7b-instruct-v0.2.Q4_K_M.gguf",
n_ctx=4096, # длина контекста
n_gpu_layers=35, # сколько слоёв на GPU (-1 = все)
)
output = llm("Объясни KV-cache за 30 секунд:", max_tokens=256)
print(output["choices"][0]["text"])
# Вариант 2: HuggingFace + bitsandbytes (GPU)
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
load_in_4bit=True, # NF4 квантизация
device_map="auto", # автоматическое размещение на GPU
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
inputs = tokenizer("Что такое FlashAttention?", return_tensors="pt").to("cuda")
output = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(output[0], skip_special_tokens=True))🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
LLM — это decoder-only трансформер + масштаб (миллиарды параметров, триллионы токенов) + alignment (SFT, RLHF). Архитектура удивительно стабильна: LLaMA, Mistral, Qwen — RMSNorm, GQA, SwiGLU, RoPE. Различия — в данных и размере.
Инженерия инференса — это борьба с памятью и скоростью. Квантизация (INT4/INT8) уменьшает размер в 2-4×. KV-cache экономит вычисления, но съедает память — GQA и PagedAttention борются с этим. FlashAttention ускоряет attention в 2-4× за счёт IO-оптимизации. vLLM с continuous batching и PagedAttention — стандарт продакшен-серvinга.
Если запомнить одну вещь: inference LLM — это memory-bound задача, не compute-bound. Всё упирается в пропускную способность памяти: перенос весов и KV-cache из HBM в вычислительные ядра. Поэтому квантизация, KV-cache и FlashAttention — не оптимизации «для красоты», а необходимость.
Дальше на роадмапе: Fine-tuning LLM — как адаптировать модель под свою задачу (LoRA, QLoRA). RAG — как дать модели доступ к внешним знаниям. Modern LLM Architectures — GQA, MoE, длинный контекст.
Материалы
Лучшее вводное видео про LLM от Карпати. Архитектура, обучение, инференс — за 1 час.
Гайд по всем методам квантизации: bitsandbytes, GPTQ, AWQ, GGUF. С примерами кода.
Статья об emergent abilities — способностях, появляющихся при масштабировании.
Оригинальная статья FlashAttention. IO-complexity анализ, online softmax, бенчмарки.
Документация vLLM: PagedAttention, continuous batching, tensor parallelism. Production-ready serving.
Глубокое объяснение LLM от первых принципов: токены, эмбеддинги, attention, обучение.