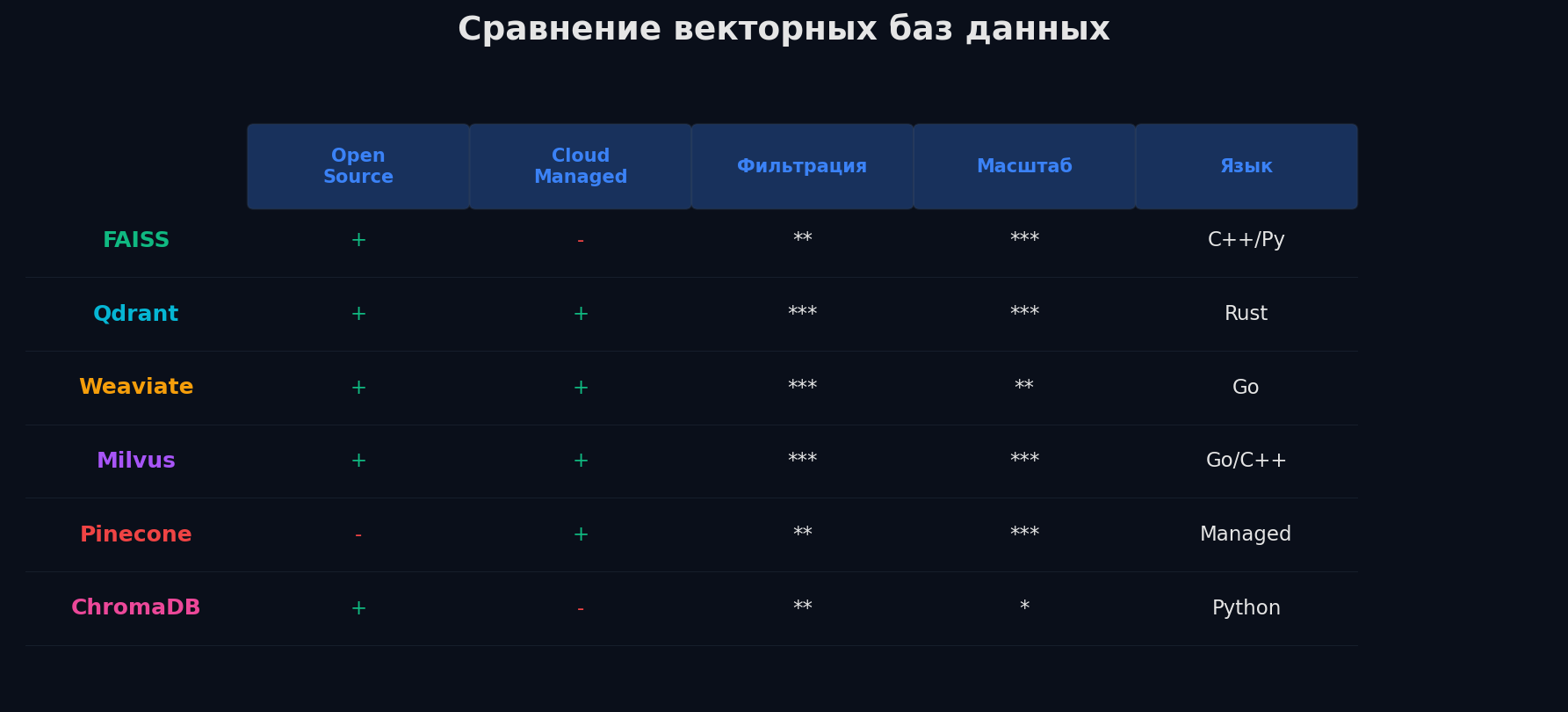
Векторные БД
FAISS, Qdrant, Weaviate, Milvus — индексы HNSW/IVF, выбор под задачу.
Векторные базы данных — поиск по смыслу, а не по ключевым словам
Обычный поиск (SQL LIKE, Elasticsearch) работает с ключевыми словами: запрос «как приготовить пасту» найдёт документы со словом «паста», но пропустит статью «рецепт итальянских спагетти карбонара» — потому что слова не совпадают, хотя смысл тот же.
Семантический поиск решает эту проблему: текст превращается в числовой вектор (эмбеддинг), который кодирует смысл. Похожие по смыслу тексты → близкие в пространстве векторы. Поиск = найти ближайших соседей к вектору запроса.
Проблема: у тебя 10 миллионов документов, каждый — вектор из 768 чисел. Нужно за 10 мс найти 10 ближайших к запросу. Перебирать все 10M — 5 секунд. Это непригодно для продакшена. Векторные базы данных строят специальные индексы для приближённого поиска ближайших соседей (ANN — Approximate Nearest Neighbors), сокращая время с секунд до миллисекунд.
Большая картина: от текста до ответа за 5 шагов
Прежде чем нырять в алгоритмы, посмотрим на весь pipeline целиком: Шаг 1. Текст → эмбеддинг. Модель (sentence-transformers, OpenAI Embeddings, E5) превращает текст в вектор фиксированной длины — 384, 768 или 1536 чисел. Шаг 2. Индексация. Векторы загружаются в векторную БД, которая строит индекс — специальную структуру для быстрого поиска (HNSW-граф, IVF-кластеры, и т.д.). Шаг 3. Запрос. Пользователь вводит запрос → модель превращает его в вектор тем же способом. Шаг 4. Поиск ближайших. Индекс находит k ближайших соседей за O(log n) вместо O(n). Шаг 5. Возврат результатов. Ближайшие векторы = самые похожие по смыслу документы. Можно вернуть пользователю или отправить в LLM как контекст (RAG).
ANN vs Exact Search
Алгоритмы ANN-поиска: как искать среди миллионов векторов
Все алгоритмы ANN решают одну задачу: не перебирать все векторы. Они отличаются тем, как организуют пространство для быстрого сужения области поиска.
Brute Force (Flat Index)
Самый простой подход — сравнить запрос с каждым вектором. O(n·d), где n — количество векторов, d — размерность. Для 100K векторов — работает нормально. Для 10M — уже нет. Это baseline, с которым сравниваем всё остальное. В FAISS — IndexFlatL2 или IndexFlatIP.
IVF (Inverted File Index)
Идея: разбить пространство на кластеры (Voronoi-разбиение через k-means). При поиске сначала находим nprobe ближайших кластеров, потом перебираем векторы только в них. Если кластеров 1000 и nprobe=10 — смотрим ~1% данных вместо 100%.
Аналогия: ты ищешь книгу в библиотеке. Вместо обхода всех полок идёшь в нужный зал (кластер), а там уже перебираешь. nprobe — сколько залов заглянуть. Больше nprobe — выше recall, медленнее поиск.
Минус: нужен train step (k-means на данных), и граничные случаи — вектор рядом с границей кластера может не попасть в результат, если его кластер не в nprobe ближайших.
HNSW: многослойный граф для быстрого поиска
HNSW (Hierarchical Navigable Small World) — самый популярный алгоритм ANN. Лучший баланс скорости и recall на большинстве бенчмарков. Используется по умолчанию в Qdrant, Weaviate, pgvector, и как опция в FAISS и Milvus.
Основная идея: построить многослойный граф, где каждая вершина — вектор, а рёбра соединяют близких соседей. Верхние слои — «грубые» (мало вершин, длинные рёбра), нижний слой — «точный» (все вершины, короткие рёбра).
Аналогия с навигацией: ты едешь в другой город. Сначала по автомагистрали (верхний слой — мало «узлов», далёкие прыжки), потом сворачиваешь на региональную дорогу (средний слой), потом на городскую улицу (нижний слой — много узлов, точная навигация). Каждый уровень приближает тебя к цели.
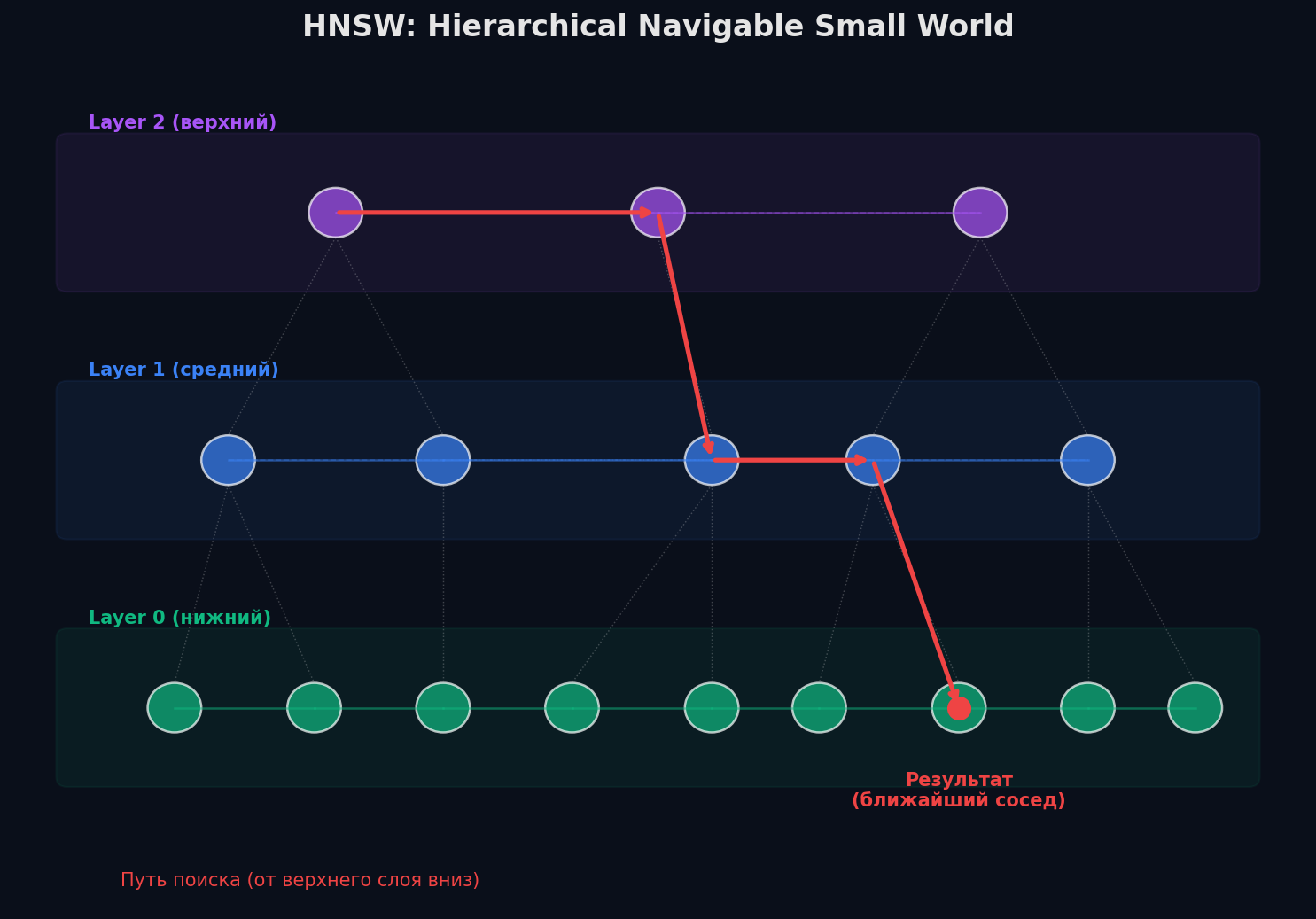
Как работает поиск в HNSW
1. Старт на верхнем слое. Начинаем с фиксированной entry point.
2. Жадный поиск. На текущем слое переходим к ближайшему соседу запроса. Повторяем, пока не найдём локальный минимум (нет соседей ближе текущего).
3. Спуск вниз. Переходим на следующий (более плотный) слой, сохраняя текущую вершину.
4. Повтор. Жадный поиск на новом слое → спуск → … → финальный поиск на нижнем слое.
5. Результат. На нижнем слое возвращаем ef ближайших найденных кандидатов, из них выбираем top-k.
Сложность поиска: O(log n) — на каждом слое количество вершин уменьшается экспоненциально. Сложность построения: O(n · log n).
Ключевые параметры HNSW
• M — максимальное количество рёбер (соседей) на вершину. Больше M → выше recall, но больше памяти и дольше построение. Типичные значения: 16-64. Default в большинстве библиотек: 16. • efConstruction — размер динамического списка кандидатов при построении индекса. Чем больше — тем качественнее рёбра, но дольше строится. Типично: 100-500. • ef (efSearch) — размер динамического списка кандидатов при поиске. Чем больше — тем выше recall, но медленнее поиск. Должно быть ≥ k (количество результатов). Типично: 50-200.
Trade-off HNSW
Product Quantization: сжатие в 4-64 раза
Когда данных так много, что даже IVF не помещается в память, нужно сжать сами векторы. Product Quantization (PQ) — главный способ это сделать.
Идея: 1. Разбиваем вектор на m подвекторов (например, 768-мерный → 96 подвекторов по 8 чисел). 2. Для каждой группы обучаем k-means на 256 центроидов (кластеров). 3. Кодируем каждый подвектор номером ближайшего центроида — 1 байт (0-255) вместо 8×4=32 байт. 4. Итого: 768 float32 (3072 байта) → 96 байт. Сжатие в 32 раза.
При поиске вместо точного расстояния используем приближённое — через таблицу расстояний от запроса до центроидов (ADC — Asymmetric Distance Computation). Это быстрее, чем считать расстояние до полного вектора.
Trade-off: PQ теряет точность. Чем сильнее сжатие (меньше подвекторов, меньше центроидов), тем ниже recall. На практике PQ + IVF (FAISS IndexIVFPQ) — рабочий вариант для миллиардов векторов: recall ~90-95% при сжатии в 30×.
Пример расчёта памяти
Метрики расстояния: cosine, L2, dot product
Выбор метрики зависит от того, как обучены эмбеддинги. Используешь не ту метрику — получишь мусор.
Cosine similarity — угол между векторами. Стандарт для текстовых эмбеддингов (sentence-transformers, OpenAI). Не зависит от длины вектора — важно только «направление».
L2 (Euclidean) — евклидово расстояние. Для нормализованных векторов эквивалентно cosine: L2² = 2 - 2·cos(θ). FAISS по умолчанию использует L2.
Dot product — скалярное произведение. Для моделей с contrastive loss (Two-Tower, DSSM). Учитывает и направление, и норму. Быстрее cosine, но если нормы различаются — результаты смещены.
Как выбрать метрику
Фильтрация по метаданным: pre-filter vs post-filter
В реальных приложениях поиск почти всегда сопровождается фильтрацией: «найди похожие документы, НО только на русском языке, НО только за последний год, НО только из категории X». Это metadata filtering — и это то, что отличает векторную БД от просто библиотеки типа FAISS.
Post-filter: сначала ищем top-N ближайших (без фильтра), потом отбрасываем не подходящие. Проблема: если большинство результатов не проходит фильтр, вернёшь меньше k результатов (или пустой ответ). Нужно запрашивать N >> k, что медленнее.
Pre-filter: сначала фильтруем по метаданным (оставляем только подходящие векторы), потом ищем среди них. Проблема: если фильтр очень селективный (оставляет 0.1% данных), ANN-индекс на маленьком подмножестве работает плохо — он построен для всего датасета.
Решение в современных БД: комбинированный подход. Qdrant, Weaviate, Milvus используют «фильтрацию во время поиска» — на каждом шаге HNSW проверяют, подходит ли кандидат по метаданным. Это не идеальный pre-filter и не чистый post-filter, а гибрид, который работает лучше обоих.
Решения: FAISS, Qdrant, Pinecone и другие — когда что
Ландшафт большой, но выбор обычно сводится к нескольким вопросам: managed или self-hosted? нужна ли фильтрация? какой масштаб? какой бюджет?
FAISS (Meta) — это библиотека, не БД. In-memory, нет API, нет persistence, нет фильтрации. Зато: GPU-ускорение, полный контроль, все алгоритмы (Flat, IVF, HNSW, PQ, и комбинации). Идеален для встраивания в свой сервис или для экспериментов. Python/C++.
Qdrant — Rust, быстрый, open-source. Полноценная БД: REST/gRPC API, persistence, payload-фильтрация (метаданные хранятся рядом с векторами), HNSW + scalar/PQ квантизация. Хороший баланс производительности и удобства. Cloud-версия тоже есть.
Weaviate — Go, GraphQL API, встроенная векторизация (можно передать текст, БД сама вызовет модель). Удобный DX, но медленнее Qdrant на чистом поиске. Хорош для прототипов с быстрым стартом.
Milvus — distributed, для 100M+ векторов. Шардирование, репликация, разделение storage/compute. Мощный, но сложный в деплое. Если не сотни миллионов — overkill.
Pinecone — fully managed, serverless. Нулевой ops. Минусы: дорого, vendor lock-in. pgvector — расширение PostgreSQL: < 1M векторов и уже есть Postgres → не нужна отдельная БД. Recall хороший, скорость уступает специализированным в 2-5×.
- Прототип / хакатон → ChromaDB (5 минут до первого запроса) или pgvector (если уже есть Postgres)
- Продакшен, < 10M векторов → Qdrant (баланс скорости, фильтрации и удобства)
- Продакшен, > 100M → Milvus (distributed) или FAISS на GPU-кластере
- Не хочешь ops → Pinecone (managed, но lock-in и $$$)
- ML-эксперименты / бенчмарки → FAISS (все алгоритмы, GPU, полный контроль)
- Уже есть PostgreSQL и немного данных → pgvector (zero new infra)
Практика: FAISS и Qdrant — код
FAISS: от brute force до IVF+PQ
import faiss
import numpy as np
d = 768 # размерность эмбеддингов
n = # количество документов
k = 10 # top-k результатов
# Генерируем данные (в реальности — эмбеддинги из модели)
vectors = np.random.rand(n, d).astype("float32")
query = np.random.rand(1, d).astype("float32")
# === Brute Force (точный поиск) ===
index_flat = faiss.IndexFlatL2(d)
index_flat.add(vectors)
D, I = index_flat.search(query, k) # D — расстояния, I — индексы
# === HNSW (быстрый, высокий recall) ===
index_hnsw = faiss.IndexHNSWFlat(d, 32) # M=32
index_hnsw.hnsw.efConstruction = 200 # качество построения
index_hnsw.hnsw.efSearch = 64 # качество поиска
index_hnsw.add(vectors)
D, I = index_hnsw.search(query, k)
# === IVF+PQ (для миллиардов, экономит память) ===
nlist = 1024 # количество кластеров
m = 96 # количество подвекторов для PQ
quantizer = faiss.IndexFlatL2(d)
index_ivfpq = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8) # 8 бит на код
index_ivfpq.train(vectors) # обучаем кластеры и PQ-кодбуки
index_ivfpq.add(vectors)
index_ivfpq.nprobe = 32 # сколько кластеров проверять при поиске
D, I = index_ivfpq.search(query, k)Qdrant: полноценная векторная БД
from qdrant_client import QdrantClient
from qdrant_client.models import (
Distance, VectorParams, PointStruct, Filter,
FieldCondition, MatchValue
)
client = QdrantClient(host="localhost", port=6333)
# Создаём коллекцию с HNSW-индексом (по умолчанию)
client.create_collection(
collection_name="documents",
vectors_config=VectorParams(size=768, distance=Distance.COSINE),
)
# Добавляем документы с метаданными (payload)
client.upsert(
collection_name="documents",
points=[
PointStruct(id=1, vector=[0.1]*768, payload={"lang": "ru", "year": 2024}),
PointStruct(id=2, vector=[0.2]*768, payload={"lang": "en", "year": 2023}),
],
)
# Поиск с фильтрацией по метаданным
results = client.search(
collection_name="documents",
query_vector=[0.15]*768,
query_filter=Filter(
must=[FieldCondition(key="lang", match=MatchValue(value="ru"))]
),
limit=10,
)🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Векторные БД — это инфраструктура для семантического поиска. Pipeline прост: текст → эмбеддинг → индексация → поиск ближайших. Но за «поиском ближайших» стоят алгоритмы с разными trade-offs:
• HNSW — лучший recall, но ест память (граф). Стандарт для большинства задач до 50M векторов. • IVF — экономнее по памяти, нужен train step. Хорош в комбинации с PQ. • PQ — сжимает векторы в десятки раз. Нужен для миллиардов векторов, когда данные не влезают в RAM. • Для выбора метрики: читай документацию модели эмбеддингов. По умолчанию — cosine.
Если запомнить одну вещь: HNSW — это многослойный граф, где поиск идёт сверху вниз: от грубой навигации к точной. O(log n), recall >95%. Главный trade-off — память.
Дальше на роадмапе: RAG покажет, как использовать векторный поиск для дополнения LLM контекстом из базы знаний — это главный use case векторных БД в 2024-2025.
Материалы
Обзор концепций: зачем нужны векторные БД, как они устроены.
Практический туториал по FAISS: от IndexFlat до IVF-PQ.
Бенчмарки разных ANN-алгоритмов: recall vs QPS на разных датасетах.
Документация Qdrant — хороший пример современной векторной БД.
Визуальное объяснение HNSW: как строится граф и как работает поиск.
Статья Малькова и Яшунина (2016). Оригинальное описание HNSW алгоритма.