Оценка RAG-систем (RAGAS)
Метрики качества RAG: faithfulness, context precision/recall, answer relevancy. Фреймворк RAGAS для автоматической оценки.
Оценка RAG — как понять, что система работает?
Загрузка интерактивного виджета...
RAG выглядит простым в демо, но ломается в продакшене тихо и незаметно. Проблема в том, что RAG ломается в двух местах: retrieval (нашли не те документы или не все нужные) и generation (модель проигнорировала контекст и нагаллюцинировала). Обычные метрики типа BLEU или ROUGE оценивают только финальный ответ, но не показывают, где именно система сломалась — в поиске документов или в генерации. Нужны специальные метрики для каждого слоя отдельно.
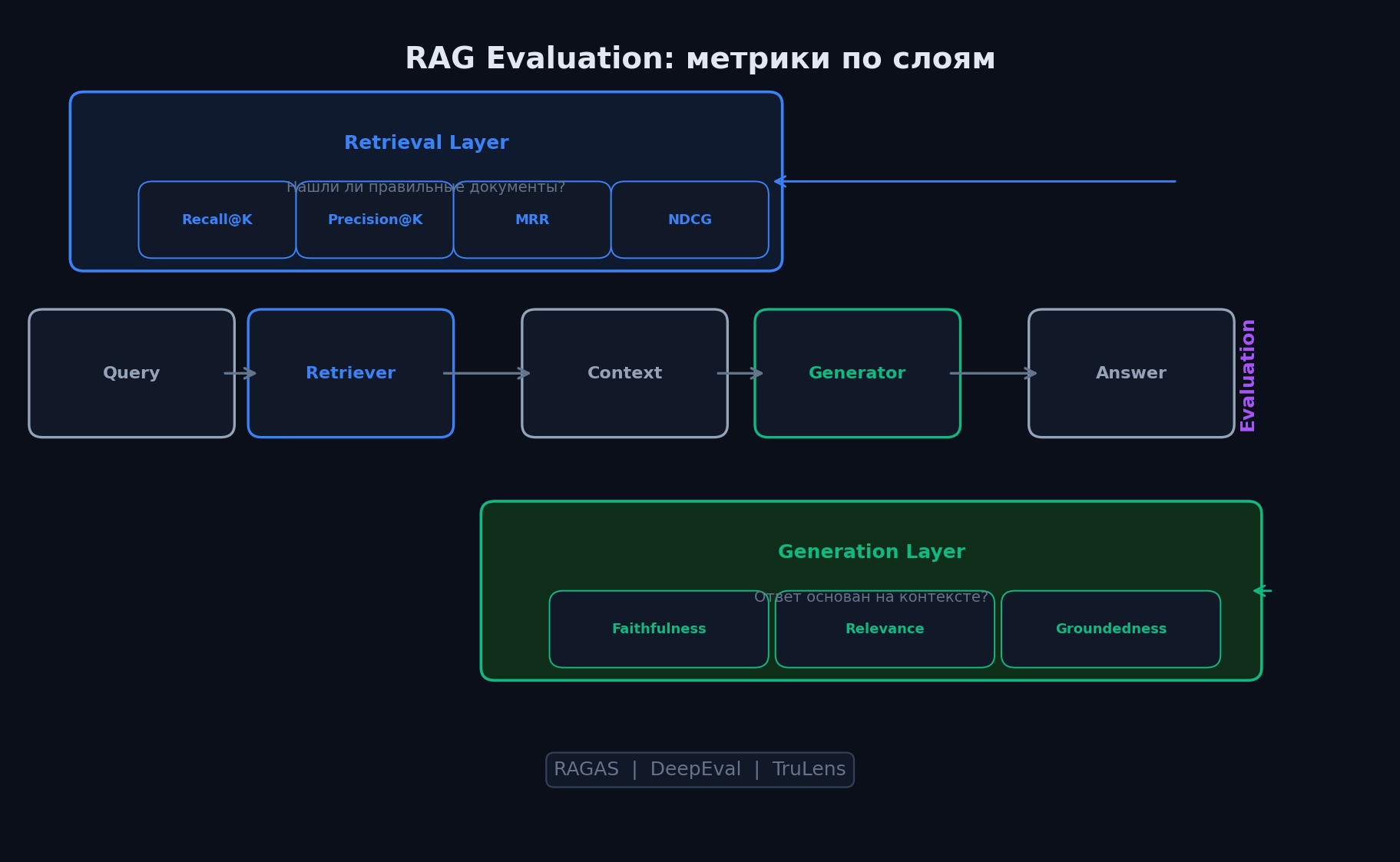
Две поверхности отказа RAG
- Retrieval: вернул нерелевантные чанки по теме, нашёл правильный документ но не тот фрагмент, нашёл 3 хороших чанка + 2 мусорных которые захламили контекст
- Generation: модель проигнорировала контекст и ответила из своих весов, смешала информацию из разных чанков в кашу, додумала факты которых не было в документах
RAGAS — фреймворк для оценки
RAGAS (Retrieval-Augmented Generation Assessment) — это open-source фреймворк, который стал индустриальным стандартом для оценки RAG-систем. Главная идея: использует LLM-as-a-judge — другая более сильная модель выступает судьёй и оценивает качество ответов твоей RAG-системы. Это дороже ручной разметки на небольшой выборке, но дешевле human evaluation на большой.
🎯 6 метрик RAGAS
Пороги для продакшена
- Faithfulness >= 0.80 (ниже = пользователи получают галлюцинации)
- Context Precision >= 0.70 (ниже = ранжирование сломано, retriever работает плохо)
- Context Recall >= 0.70 (ниже = теряем важные документы, ответы неполные)
- Answer Relevancy >= 0.70 (ниже = ответы вообще не по теме, система бесполезна)
Как запустить RAGAS
pip install ragas
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
# Ваши данные: вопросы, ответы, найденные чанки
from datasets import Dataset
dataset = Dataset.from_dict({
"question": ["Какая зарплата ML-инженера?"],
"answer": ["ML-инженер получает 250-400K ₽/мес по данным 2024"],
"contexts": [["Зарплата ML: 250-400K", "Data Scientist: 200-350K"]],
"ground_truth": ["250-400 тысяч рублей в месяц"]
})
# Оценка по 4 основным метрикам
result = evaluate(
dataset,
metrics=[faithfulness, context_precision, context_recall, answer_relevancy]
)
print(result)IR-метрики для быстрой проверки retrieval
RAGAS использует LLM-судью — это дорого на больших датасетах и долго. Для быстрых проверок качества retrieval отдельно от generation можно использовать классические IR-метрики без LLM: Precision@K (доля релевантных среди top-K найденных), Recall@K (доля найденных от всех релевантных), MRR (Mean Reciprocal Rank) — позиция первого релевантного документа.
Precision@K vs Recall@K
Генерация синтетических тестов
Размеченных данных нет, а вручную размечать лень? RAGAS умеет генерировать тестовые вопросы из твоих документов автоматически. Три типа эволюций: Simple — простые фактоидные вопросы ("Сколько стоит услуга?"), Reasoning — требуют рассуждений ("Почему услуга А лучше Б?"), Multi-context — ответ собирается из нескольких чанков.
from ragas.testset.generator import TestsetGenerator
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
generator = TestsetGenerator.from_langchain(
ChatOpenAI(model="gpt-4"),
ChatOpenAI(model="gpt-3.5-turbo"),
OpenAIEmbeddings()
)
testset = generator.generate_with_langchain_docs(documents, test_size=50)RAGAS в CI/CD
Обновил FAQ, добавил новые документы, переиндексировал базу знаний — запусти pipeline проверки, что retrieval quality не просела. GitHub Actions с триггером на paths: ['knowledge_base/**'] автоматически прогонит тесты и заблокирует merge если метрики упали ниже порогов.
🎯 На собеседовании
Junior
Middle
Senior
⚠️ Суть для собеса
Материалы
Практическое руководство по настройке RAGAS под свои задачи и данные.
Детальный разбор всех метрик RAGAS с примерами и кодом.
Практические советы по тестированию и отладке RAG-пайплайнов.
Официальная документация фреймворка RAGAS.