LLM-агенты
ReAct, function calling, LangChain/LlamaIndex/CrewAI, оркестрация, memory.
LLM-агенты — когда модель сама решает, что делать
Загрузка интерактивного виджета...
Обычный LLM — это советник: ты задаёшь вопрос, он отвечает на основе того, что знает. Но у него нет рук. Он не может зайти в интернет, посчитать выражение, проверить базу данных или отправить письмо. Всё, что LLM умеет — генерировать текст.
LLM-агент — это LLM, у которого появились «руки». Формально: агент = LLM (мозг) + инструменты (tools) + память (memory) + планирование (planning). Агент получает задачу от пользователя и сам решает, какие инструменты вызвать, в каком порядке, как интерпретировать результат — и делает это итеративно, пока не решит задачу.
Аналогия: LLM — это эксперт, прикованный к телефону. Ты звонишь, спрашиваешь — он отвечает. Агент — это стажёр с доступом к компьютеру: он сам гуглит, открывает документы, считает в Excel, проверяет результат и приносит тебе готовый ответ. Иногда спрашивает уточнения, но основную работу делает сам.
Большая картина: как агент решает задачу
Вот что происходит, когда ты просишь агента «Найди 5 лучших отелей в Барселоне до 150€ за ночь и сравни рейтинги»:
Шаг 1. Планирование. Агент разбивает задачу на подзадачи: (а) найти отели с фильтром по цене, (б) получить рейтинги, (в) сравнить и отсортировать, (г) сформировать ответ. Шаг 2. Выбор инструмента. Для подзадачи (а) агент решает вызвать search_hotels(city="Barcelona", max_price=150). Он генерирует вызов функции в структурированном формате. Шаг 3. Исполнение. Система (не LLM!) выполняет вызов и возвращает результат — список отелей. Шаг 4. Наблюдение. Агент анализирует результат: нашлось 12 отелей, нужно выбрать топ-5. Нужны рейтинги — вызывает get_ratings(hotel_ids=[...]). Шаг 5. Итерация. Шаги 2-4 повторяются, пока агент не соберёт всю информацию. Шаг 6. Финальный ответ. Агент формирует таблицу сравнения и возвращает пользователю.
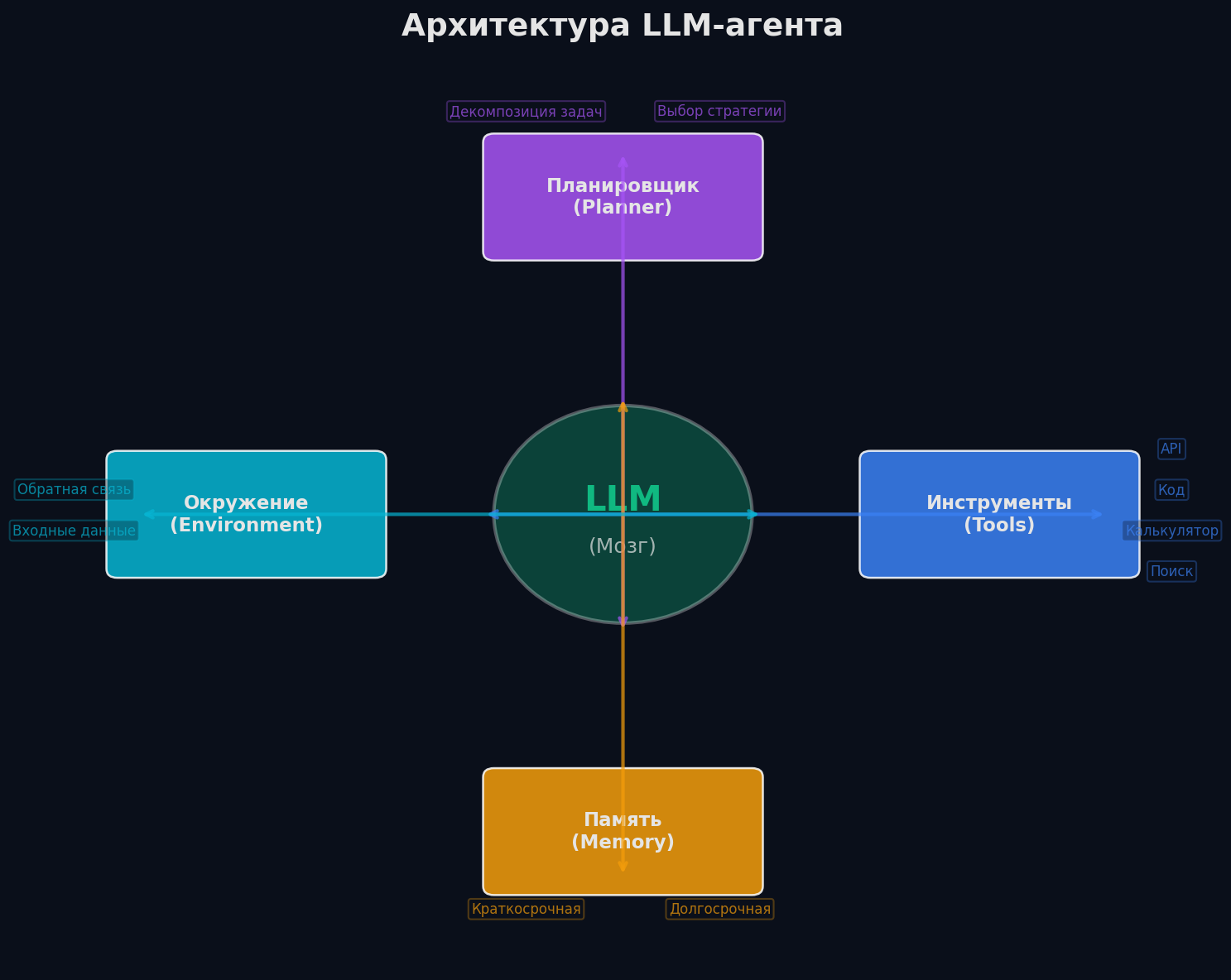
Ключевое отличие от pipeline
ReAct — Reasoning + Acting
ReAct (Yao et al., 2022) — базовый паттерн, на котором построено большинство агентов. Идея проста: модель чередует рассуждение (Thought) и действие (Action). После каждого действия она получает наблюдение (Observation) от внешней среды и решает, что делать дальше.
Почему это работает? До ReAct были два подхода: (1) chain-of-thought — модель рассуждает, но не действует (не может проверить факты); (2) act-only — модель вызывает инструменты, но не рассуждает (не понимает, зачем). ReAct комбинирует оба: рассуждение помогает планировать действия, а действия дают новую информацию для рассуждений.
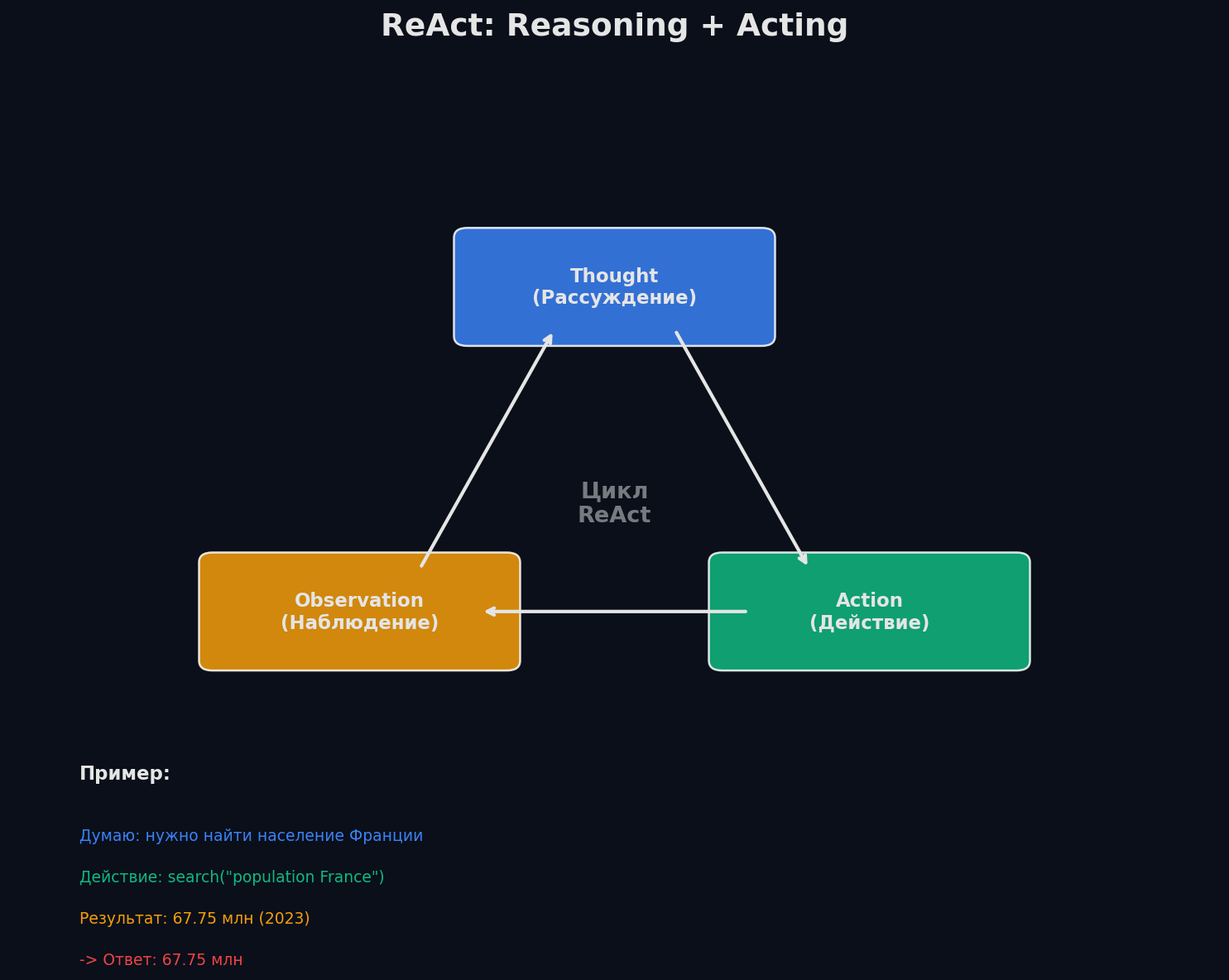
Конкретный пример — вопрос «В каком году родился автор Harry Potter?»:
Thought: Harry Potter, .
Action: search("автор Harry Potter")
Observation: (J.K. Rowling)
Thought: .
Action: search("J.K. Rowling дата рождения")
Observation: 31 1965 .
Thought: .
Answer: Harry Potter .. , 1965 .Каждый Thought — это явное рассуждение, записанное в промпт. Это делает агента интерпретируемым: ты видишь, почему он принял каждое решение. В отличие от чистого action-модели, где tool calls идут без объяснений.
Tool Use: как LLM вызывает инструменты
Инструменты (tools) — это функции, которые агент может вызвать. Поиск в интернете, калькулятор, SQL-запрос, API бронирования — всё это tools. Но LLM не выполняет код — он генерирует описание вызова (имя функции + аргументы), а исполняет его внешняя система.
Раньше инструменты вызывались через текст: модель генерировала строку типа Action: search("query"), и парсер извлекал из неё вызов. Это ненадёжно — модель могла написать Action: serch("query") или вставить лишнюю скобку.
Function calling (нативный tool use) решает эту проблему. Ты описываешь доступные функции в формате JSON-схемы, модель возвращает структурированный JSON с именем функции и аргументами. Не свободный текст, а формат, который можно валидировать программно.
# Описываем инструменты для модели
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Текущая погода в городе",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Название города"},
"units": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}]
# Модель решает вызвать инструмент
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Какая погода в Москве?"}],
tools=tools
)
# response.choices[0].message.tool_calls:
# [{"function": {"name": "get_weather", "arguments": '{"city": "Москва", "units": "celsius"}'}}]
# Выполняем вызов, возвращаем результат модели
weather = get_weather(city="Москва", units="celsius") # {"temp": 22, "condition": "sunny"}
# Добавляем результат в контекст → модель формирует финальный ответКлючевой момент: LLM не исполняет функцию — он только решает, какую вызвать и с какими аргументами. Исполнение — ответственность твоей системы. Это разделение критично для безопасности: ты контролируешь, что агент реально может сделать.
Parallel tool calls
Память агента: short-term, long-term, working memory
У человека есть рабочая память (что держишь в голове прямо сейчас), кратковременная (события за последний час) и долговременная (знания и опыт за всю жизнь). У LLM-агента — аналогичная структура, но с другими ограничениями.
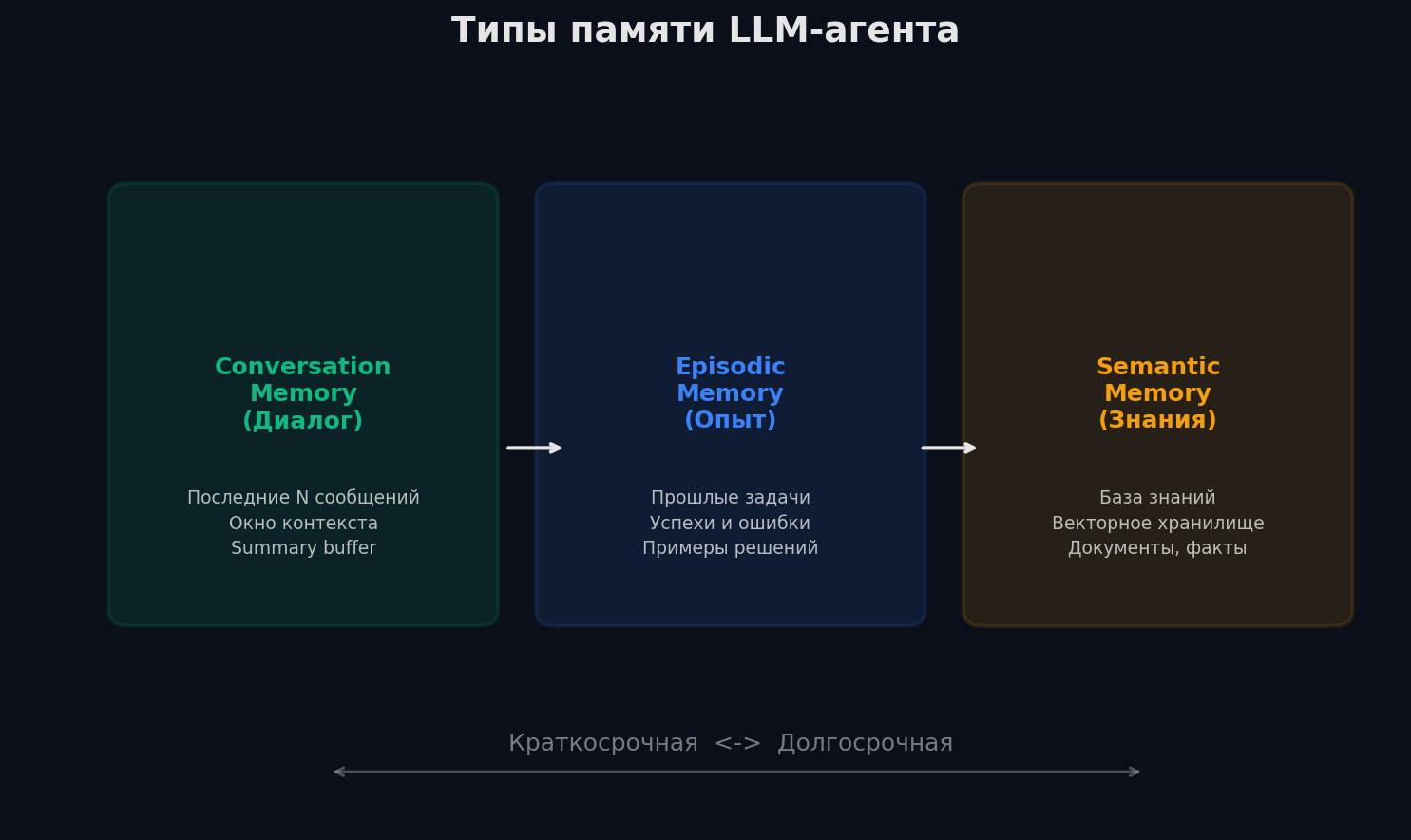
Short-term memory (контекстное окно). Всё, что помещается в промпт: системный промпт + история сообщений + результаты tool calls. Это «рабочий стол» агента. Ограничение жёсткое: 128K токенов (GPT-4o), 200K (Claude). Когда контекст переполняется, старые сообщения нужно удалять или суммаризировать.
Long-term memory (долговременная). Информация, которая переживает отдельную сессию. Типичные реализации: • Vector store (Pinecone, Chroma, FAISS) — агент сохраняет факты как эмбеддинги и ищет по семантической близости. Это по сути RAG для памяти агента. • Key-value store — простой словарь: user_preferences, past_decisions. Быстрый поиск по ключу. • Граф знаний — связи между сущностями: «пользователь → работает в → компания X → использует → Python».
Working memory (рабочая память). Промежуточные результаты текущей задачи: «я уже нашёл 3 отеля из 5», «текущий лучший результат — Hotel X с рейтингом 9.2». Часто реализуется как scratchpad — отдельное поле в промпте, которое агент может обновлять.
Проблема потери контекста
Planning: как агент планирует действия
Для простых задач (одного tool call достаточно) планирование не нужно. Но для сложных — «проанализируй продажи за Q3, найди аномалии, построй отчёт» — агенту нужно декомпозировать задачу на подзадачи и определить порядок выполнения.
Два основных подхода:
ReAct (step-by-step). Агент не строит план заранее. Он делает один шаг, смотрит на результат, решает следующий шаг. Плюс: адаптивность — если первый поиск не дал результатов, агент перестроится. Минус: для сложных задач может петлять и тратить шаги на тупиковые ветки.
Plan-and-Execute. Сначала отдельный LLM-вызов создаёт план — список подзадач с зависимостями. Потом «executor» выполняет каждую подзадачу. После выполнения — опционально «replanner» пересматривает оставшиеся шаги. Плюс: структурированность, меньше петель. Минус: начальный план может быть неточным, дополнительные LLM-вызовы на планирование.
# Plan-and-Execute: концептуальный пример
plan = planner.invoke("Проанализируй продажи за Q3, найди аномалии, построй отчёт")
# plan = [
# "1. Загрузить данные продаж за Q3 из БД",
# "2. Рассчитать метрики: выручка, средний чек, конверсия по неделям",
# "3. Найти аномалии: отклонения >2σ от среднего",
# "4. Сформировать отчёт с графиками"
# ]
for step in plan:
result = executor.invoke(step, tools=tools)
# Опционально: replanner корректирует план
plan = replanner.invoke(plan, completed=step, result=result)На практике ReAct побеждает для большинства задач: он проще, не требует отдельного планировщика, и для задач с 3-5 шагами работает отлично. Plan-and-Execute нужен для сложных задач с 10+ шагами, где важно не потерять общую картину.
LangChain и LangGraph: оркестрация агентов
LangChain — самый популярный фреймворк для LLM-приложений. Ядро: chains (цепочки вызовов) и agents (агенты с инструментами). LangChain предоставляет абстракции для промптов, моделей, инструментов, ретриверов и объединяет их в pipeline.
LangGraph — надстройка над LangChain для сложных агентов. Если LangChain chains — это линейный конвейер (A → B → C), то LangGraph — это граф с циклами и условными переходами. Узлы графа — функции (LLM-вызовы, tool calls, логика). Рёбра — условные переходы (если результат X → идём в узел Y, иначе в Z).
Когда что использовать: • Простая цепочка (extract → transform → validate) — достаточно LangChain chain или даже простого Python. • Агент с инструментами (ReAct loop) — LangChain create_react_agent или LangGraph с циклом. • Сложная логика (ветвления, параллельные вызовы, human-in-the-loop, checkpoints) — LangGraph. • Multi-agent (несколько агентов координируют работу) — LangGraph (supervisor pattern).
# LangGraph: агент с ReAct-циклом
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
@tool
def search_web(query: str) -> str:
"""Поиск информации в интернете."""
return web_search(query)
@tool
def calculator(expression: str) -> str:
"""Вычисление математического выражения."""
return str(eval(expression))
agent = create_react_agent(
model=ChatOpenAI(model="gpt-4o"),
tools=[search_web, calculator],
)
# Агент сам решает, какие инструменты вызвать и в каком порядке
result = agent.invoke({
"messages": [{"role": "user", "content": "Население Москвы делённое на площадь"}]
})LangChain — не единственный вариант
Проблемы агентов: что ломается в продакшене
Агенты — мощный инструмент, но с серьёзными проблемами. Понимание этих проблем — ключ к разработке надёжных систем.
Галлюцинации tool calls. Модель может вызвать инструмент, который не существует, передать невалидные аргументы или выдумать результат вместо реального вызова. Пример: агент «вызывает» query_database(sql="SELECT * FROM sales"), но вместо ожидания результата сам генерирует правдоподобные, но фейковые данные.
Бесконечные циклы. Агент застревает: вызывает один и тот же инструмент с одними и теми же аргументами, каждый раз получая тот же результат, но не может выбраться из цикла. Или переключается между двумя инструментами бесконечно.
Стоимость. Каждый шаг агента — это LLM-вызов. В ReAct loop из 5 шагов: 5 вызовов модели + весь контекст растёт с каждым шагом. Сложная задача на GPT-4o может стоить $0.50-2.00 за один запрос пользователя.
Непредсказуемость. Один и тот же вопрос может приводить к разным цепочкам действий. Детерминизм pipeline заменяется стохастичностью агента. Это усложняет тестирование, отладку и оценку качества.
Защиты: • max_iterations — жёсткий лимит на число шагов (5-15) • Budget limit — лимит на токены/деньги за один запрос • Output validation — проверка результата каждого tool call перед следующим шагом • Strict tool schemas — JSON-схемы с validation для каждого инструмента • Fallback — если агент не справился за N шагов, эскалация человеку или fallback-ответ • Guardrails — запрет опасных действий (DELETE, DROP TABLE) на уровне инструментов
Multi-agent системы: несколько агентов вместе
Один агент с 3-5 инструментами закрывает 80% задач. Но когда задача требует разных экспертиз — анализ данных + написание отчёта + ревью кода — можно разделить работу между несколькими специализированными агентами.
Supervisor pattern — самый распространённый подход. Один агент-«менеджер» (supervisor) получает задачу, декомпозирует её и раздаёт подзадачи worker-агентам. Каждый worker специализирован: researcher (поиск + анализ), coder (написание кода), reviewer (проверка качества). Supervisor собирает результаты, проверяет и формирует финальный ответ.
- Sequential — агенты работают по цепочке: researcher → writer → reviewer. Каждый передаёт результат следующему
- Parallel (fan-out / fan-in) — supervisor запускает нескольких workers одновременно, собирает результаты
- Hierarchical — supervisor → sub-supervisors → workers. Для масштабных задач с десятками подзадач
Практический совет
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
LLM-агент — это LLM с «руками»: tools (вызов внешних функций), memory (контекст + долговременное хранилище) и planning (декомпозиция задач). Базовый паттерн — ReAct: рассуждай → действуй → наблюдай → повторяй. Function calling сделал tool use надёжным: структурированный JSON вместо парсинга текста.
Если запомнить одну вещь: начинай с простого. Один агент + 3-5 хорошо описанных инструментов + строгие схемы + max_iterations — это уже рабочее решение для большинства задач. Multi-agent, Plan-and-Execute, сложные графы — добавляй только когда упрёшься в потолок простого подхода.
Дальше на роадмапе: RAG — как давать агенту доступ к базе знаний, Prompt Engineering — как правильно формулировать инструкции для LLM, LLM Evaluation — как оценивать качество LLM-приложений, включая агентов.
Материалы
Оригинальная статья ReAct — основа большинства LLM-агентов. Обязательна к прочтению.
Лучший обзор архитектур LLM-агентов: memory, planning, tool use. Глубоко и с картинками.
Паттерны построения агентов от создателя LangChain. Практично, с примерами.
Официальная документация LangGraph: графы, циклы, checkpoints, human-in-the-loop.
Как работает нативный function calling в OpenAI API. Практический гайд с примерами.