NLP System Design
Проектирование production NLP-систем: чат-бот, поиск, модерация.
NLP System Design — проектирование NLP-систем для прода
«Спроектируй чат-бот для поддержки» или «Спроектируй поисковую систему» — такие задачи дают на собеседовании, и они не про код. Это про умение превратить бизнес-задачу в архитектуру: разложить на компоненты, выбрать модели, продумать serving и мониторинг. Правильного ответа нет — есть набор trade-offs, и от тебя ждут умения их обсуждать.
Если обычное ML-собеседование проверяет «понимаешь ли ты, как работает BERT?», то system design проверяет «можешь ли ты построить продукт, в котором BERT — лишь один кубик?». Это уровень senior-инженера: не только обучить модель, но и доставить её пользователю с нужным latency, стоимостью и отказоустойчивостью.
Большая картина: от бизнес-задачи до production
Любая NLP-система проходит один и тот же путь. Не важно, что ты проектируешь — чат-бот, поиск, модерацию или суммаризатор — шаги одни и те же, меняется только начинка.
Шаг 1. Requirements. Уточни масштаб: сколько запросов в секунду (QPS)? Какой допустимый latency? Какие языки? Сколько данных? Какая бизнес-метрика (retention, CSAT, revenue)? Без этого архитектуру рисовать бессмысленно — решение для 100 запросов/день и 100K запросов/минуту будет принципиально разным. Шаг 2. Data. Откуда данные? Как размечать? Сколько стоит разметка? Есть ли cold start (нет данных вообще)? Данные — это 80% успеха ML-системы, и именно тут большинство проектов буксует. Шаг 3. Model. Какую модель выбрать? Классический pipeline (NER + classifier + rules) vs end-to-end LLM? Своя модель или API? Fine-tune или zero-shot? Выбор зависит от требований из шага 1. Шаг 4. Serving. Как доставить модель пользователю? Latency budget, batching, caching, streaming. Инфраструктура: GPU vs CPU, контейнеры, автоскейлинг. Шаг 5. Monitoring. Модель в проде деградирует: меняется язык пользователей, появляются новые темы, дрейфует распределение. Нужен мониторинг, алерты и feedback loop для непрерывного улучшения.
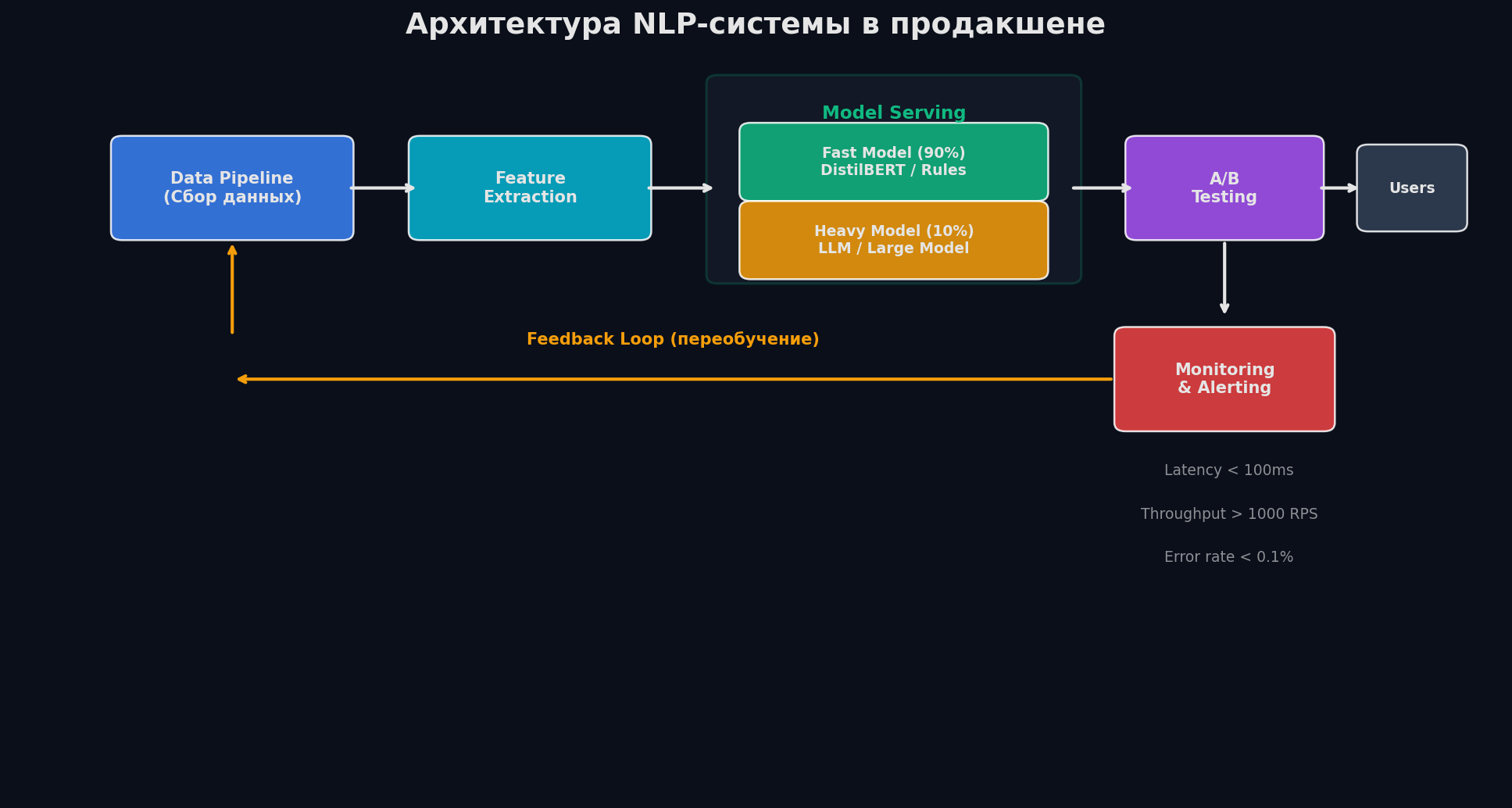
Фреймворк ответа: как говорить на system design собесе
У тебя 30-45 минут. Молча рисовать архитектуру — плохо. Сразу кодить — ещё хуже. Вот структура, которая работает:
- [2-3 мин] Уточни требования. QPS, latency, языки, объём данных, бизнес-цель. Интервьюер ждёт этих вопросов — они показывают, что ты думаешь как инженер, а не как кагглер. «Это для внутреннего инструмента на 50 запросов/день или для фичи в продукте с 1M DAU?»
- [3-5 мин] Определи метрики. Офлайн (F1, BLEU, accuracy) + онлайн (latency p50/p99, error rate, user satisfaction). Guardrails: что точно не должно случиться (выдать чужие персональные данные, сгенерировать offensive контент). Метрики — это договор между тобой и бизнесом.
- [10-15 мин] Нарисуй архитектуру. Пайплайн обработки запроса от пользователя до ответа. Каждый компонент: конкретная модель, latency, стоимость. Trade-offs на каждом шаге.
- [5-7 мин] Обсуди данные. Как собирать, как размечать, cold start, quality control, data pipeline.
- [5-7 мин] Serving + стоимость. Latency budget по компонентам, GPU/CPU, batching, caching, autoscaling. Посчитай: сколько стоит запрос? Сколько стоит день?
- [3-5 мин] Мониторинг + итерации. Drift, degradation, feedback loop. Что мониторишь, как откатываешь, как улучшаешь. MVP → V1 → V2 — покажи путь эволюции.
Главная ошибка
Пример 1: Чат-бот клиентской поддержки
Задача: спроектировать чат-бот для поддержки. 50K обращений в день, 80% типовых вопросов (баланс, статус заказа, возврат), 20% нестандартных. Требования: latency < 2 секунды, доля автоматически решённых обращений > 70%.
Архитектура: каскадный pipeline
Ключевая идея: не гонять тяжёлую модель на каждый запрос. 80% типовых вопросов решаются дешёвыми компонентами, а дорогой LLM работает только со сложными кейсами. Это cascading pipeline — каскад от быстрого и дешёвого к медленному и дорогому.
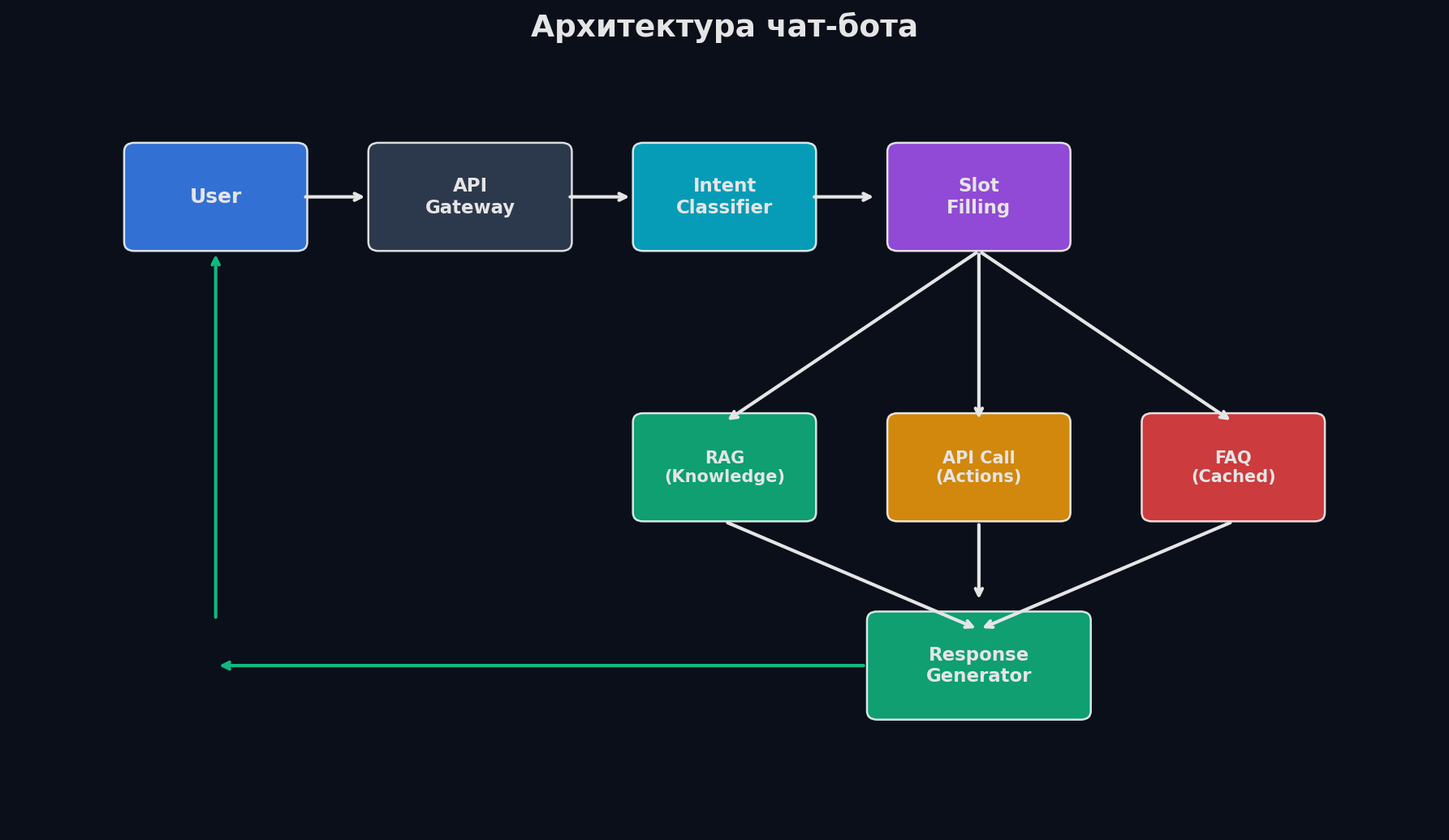
Уровень 1: Intent Detection (~15мс). Быстрый классификатор (fine-tuned DistilBERT или даже TF-IDF + LogReg) определяет намерение пользователя: «проверить баланс», «заблокировать карту», «оформить возврат» и т.д. 50-100 интентов. Если confidence > 0.85 — переходим к шагу 2. Если ниже — сразу к LLM. Уровень 2: Slot Filling (~10мс). Извлекаем сущности из запроса: номер заказа, дата, сумма. NER-модель или regex для структурированных данных. Для запроса «Где мой заказ 123456?» извлекаем: intent=order_status, order_id=123456. Уровень 3: Response Generation. — Для типовых интентов: шаблонный ответ + вызов API (получить статус заказа из базы). Latency: 50-100мс. Стоимость: ~$0. — Для сложных кейсов: RAG по базе знаний + LLM-генерация. Latency: 1-3 секунды. Стоимость: ~$0.005 за запрос. Уровень 4: Fallback. Если confidence модели < 0.7, пользователь явно просит оператора, или 2 неудачные попытки — передаём живому оператору. Это не ошибка системы, а архитектурное решение: лучше передать оператору, чем дать неправильный ответ.
# Cascading pipeline чат-бота
class ChatbotPipeline:
"""Каскадная архитектура: дешёвое → дорогое → fallback."""
def __init__(self):
self.intent_model = load_model("distilbert-finetuned") # ~15ms
self.ner_model = load_model("spacy-ner") # ~10ms
self.llm = LLMClient("gpt-4o-mini") # ~1500ms
def handle(self, user_message: str) -> Response:
# Уровень 1: Intent Detection
intent, confidence = self.intent_model.predict(user_message)
if confidence < 0.7:
return self.escalate_to_human(user_message)
if confidence > 0.85 and intent in TEMPLATE_INTENTS:
# Уровень 2: Slot Filling + Template Response
slots = self.ner_model.extract(user_message, intent)
api_result = call_backend_api(intent, slots)
return fill_template(intent, api_result)
# Уровень 3: RAG + LLM для сложных кейсов
context = self.retrieve_knowledge(user_message, top_k=5)
return self.llm.generate(
system="Ты помощник поддержки. Отвечай на основе контекста.",
context=context,
user_message=user_message,
)
# Стоимость: 80% template ($0) + 20% LLM ($0.005) = ~$50/день при 50K запросовTrade-off: LLM vs классический NLU
Пример 2: Поисковая система по документам
Задача: поисковая система по внутренней базе знаний компании. 500K документов, 10K поисковых запросов в день. Требования: latency < 500мс, top-5 документов должны содержать ответ в 90% случаев.
Архитектура: Query Understanding → Retrieval → Ranking
Поиск — это тоже каскад, но с другой структурой. Сначала понимаем запрос, потом быстро находим кандидатов, потом точно ранжируем top-N.
Stage 1: Query Understanding (~20мс). Что имел в виду пользователь? Исправление опечаток, расширение запроса синонимами, определение intent (ищет документ? хочет ответ на вопрос? навигационный запрос?). Для внутреннего поиска: маппинг аббревиатур и сленга на нормальные термины. Stage 2: Retrieval (~50мс). Быстрый отсев: из 500K документов выбираем top-100-500 кандидатов. Два подхода параллельно: — Sparse retrieval (BM25/Elasticsearch): быстрый, основан на точном совпадении терминов, хорош для конкретных запросов ("error code 502"). — Dense retrieval (bi-encoder, e5/bge): семантический поиск по эмбеддингам, ловит парафразы ("как перезагрузить сервер" найдёт "рестарт машины"). Оба результата объединяются (reciprocal rank fusion или просто union). Stage 3: Ranking (~100-200мс). Cross-encoder (например, bge-reranker) берёт top-100 кандидатов и переранжирует, оценивая пару (query, document) целиком. Это самый дорогой, но самый точный шаг — cross-encoder не разделяет query и document, а обрабатывает конкатенацию через BERT-подобную модель. Stage 4: Answer Generation (опционально, ~1-2с). Если пользователь задал вопрос, а не ищет документ — RAG: берём top-3 документа, подаём в LLM, генерируем прямой ответ с цитатами.
# Поисковый pipeline: hybrid retrieval + reranking
class SearchPipeline:
def search(self, query: str, top_k: int = 5) -> list[Document]:
# Stage 1: Query Understanding
query = self.spell_correct(query)
expanded = self.expand_query(query) # синонимы, аббревиатуры
# Stage 2: Hybrid Retrieval (параллельно)
sparse_hits = self.bm25.search(expanded, top_n=200) # ~10ms
dense_hits = self.bi_encoder.search(query, top_n=200) # ~30ms
candidates = reciprocal_rank_fusion(sparse_hits, dense_hits, k=100)
# Stage 3: Reranking (cross-encoder, самый дорогой шаг)
scores = self.cross_encoder.score(
[(query, doc.text) for doc in candidates] # ~2ms/пара
)
ranked = sorted(zip(candidates, scores), key=lambda x: -x[1])
return [doc for doc, _ in ranked[:top_k]]
# Latency budget: query understanding 20ms + retrieval 50ms
# + reranking 200ms + overhead 30ms = ~300ms totalBi-encoder vs Cross-encoder
Serving: как доставить модель пользователю
Обученная модель бесполезна, если не обслуживает запросы с нужным latency и стоимостью. Serving — это та часть, где ML-инженер должен думать как backend-инженер.
Latency budget — бюджет по задержке
Для каждого компонента в pipeline считаем latency и складываем. Если бюджет 500мс, а pipeline из 3 моделей по 300мс — у тебя проблема. Решения: • Параллелизм — если компоненты независимы, запускай параллельно (sparse + dense retrieval одновременно) • Distillation — замена тяжёлой модели на лёгкую с минимальной потерей качества • Quantization — INT8/INT4 вместо FP16, до 2-4× ускорение • Ранний выход — если classifier уверен на 99%, не гоняй тяжёлую модель
Batching, caching, streaming
Batching. GPU эффективен на больших батчах. Один запрос на GPU — расточительство, 32 запроса — полная утилизация. Dynamic batching (Triton, vLLM): копим запросы N мс, объединяем в батч, обрабатываем. Trade-off: latency одного запроса растёт (ждём батч), но throughput системы кратно растёт. Caching. Одинаковые вопросы — одинаковые ответы. Для FAQ 30-50% запросов попадают в кэш. Semantic cache: ищем не точное совпадение запроса, а близкий по эмбеддингу. Если cosine similarity > 0.95 — отдаём кэшированный ответ. Redis + FAISS = быстро. Streaming. Для LLM-ответов: не ждём полную генерацию, отдаём токен за токеном. Perceived latency (время до первого токена) в 5-10× меньше реальной. Пользователь видит «бот печатает» вместо пустого экрана 3 секунды.
Оптимизация стоимости
LLM API дорогие. 100K запросов/день × $0.01/запрос = $30K/месяц. Способы снизить:
- Routing — простые запросы → дешёвая модель (DistilBERT, $0), сложные → LLM ($0.01). Classifier-router или confidence threshold
- Fine-tuning маленькой модели — дистилляция GPT-4 в Mistral-7B или DistilBERT для конкретной задачи. Дешевле в 50-100× на inference
- Prompt optimization — короче промпт = меньше токенов = дешевле. Убери лишние примеры, сжимай system prompt
- Batch API — для offline-задач (разметка, суммаризация) используй batch endpoint (у OpenAI на 50% дешевле)
- Self-hosted — при >100K запросов/день своя модель (vLLM + A100) часто дешевле API
Мониторинг: как ловить деградацию до того, как пожалуются пользователи
NLP-модели деградируют тихо. Пользователи меняют язык, появляются новые темы, меняются продукты. Accuracy на тесте от прошлого года ничего не значит для запросов сегодня. Без мониторинга узнаешь о проблеме от разгневанных пользователей — когда уже поздно.
Что мониторить
Data drift — распределение входных данных изменилось. Как заметить: считаем средний эмбеддинг запросов за день/неделю и сравниваем с baseline. Если cosine distance вырос — что-то изменилось. Пример: выходит новый продукт → появляются запросы, которых модель никогда не видела → confidence падает, ошибки растут. Model quality — прямые метрики качества. Для classifier: доля low-confidence предсказаний (confidence < 0.7). Для LLM: доля ответов с hallucination flags. Для search: click-through rate на top-3 результатах. Latency и throughput — p50, p95, p99 latency по каждому компоненту. Если cross-encoder вместо 200мс стал отвечать за 500мс — проблема (модель подросла? данные изменились? GPU throttling?). User feedback — самый честный сигнал. Thumbs up/down, escalation rate (сколько пользователей ушло к оператору), repeat contact rate (вернулся с тем же вопросом = не помогли). Feedback можно использовать как метки для дообучения.
Feedback loop — замкнутый цикл улучшения
Модель в проде — это не «задеплоил и забыл». Это цикл: deploy → мониторинг → сбор feedback → дообучение → deploy. Конкретный процесс: 1. Логируй всё: запрос, ответ модели, confidence, user feedback, latency 2. Еженедельная выборка: 100-200 случайных запросов → ручная оценка качества 3. Алерты: если confidence < 0.7 вырос на 20% за неделю — alarm 4. Retraining trigger: если quality metric упал ниже порога → автоматический retrain на свежих данных + human-in-the-loop разметка ошибок 5. A/B тест: новая модель vs текущая на 5-10% трафика → если метрики лучше → раскатка
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
NLP System Design — это не про выбор «правильной» модели. Это про построение системы, где модель — лишь один компонент среди требований, данных, serving-инфраструктуры и мониторинга. Фреймворк один для любой задачи: requirements → data → model → serving → monitoring. Начинка меняется, скелет — нет.
Если запомнить одну вещь из этой ноды: на system design собесе оценивают не ответ, а мышление. Уточни требования, покажи альтернативы, посчитай latency и стоимость, обсуди trade-offs, не забудь про мониторинг. Это отличает senior-инженера от того, кто просто натренировал модель.
Дальше на роадмапе: MLOps расскажет про infrastructure as code и CI/CD для моделей, Model Serving углубится в batch vs online serving, а Мониторинг — в детали data drift и alerting.
Материалы
Фреймворк для ML system design: требования, метрики, архитектура, trade-offs.
Бесплатная книга по проектированию ML-систем. От требований до мониторинга.
Лекция Chip Huyen о проектировании ML-систем для production.
Гайд по мониторингу ML-моделей в проде: drift, quality, performance.
Паттерны для production LLM-систем: RAG, caching, guardrails, fine-tuning.