SFT и дообучение
Supervised Fine-Tuning: chat templates, instruction datasets, sequence packing, distillation.
SFT: как autocomplete становится ассистентом
Base model после pre-training — это гениальный идиот. Ты пишешь "Как приготовить борщ?", а она продолжает: "Как приготовить борщ? Как приготовить плов? Как приготовить...". Она не понимает, что ты задал вопрос — для неё это просто начало списка. SFT (Supervised Fine-Tuning) ставит мозги на место: учит распознавать формат чата и, собственно, отвечать.

Chat template: формат, который всё решает
Каждая модель общается в своём chat template со спецтокенами. Llama хочет <|begin_of_text|>, ChatML — <|im_start|>, Mistral — [INST]. Перепутал формат? Поздравляю, модель несёт бред, потому что видит незнакомую структуру. Это одна из самых тупых и частых ошибок при работе с LLM. Не будь тем человеком.
# ChatML формат (Qwen, Yi)
<|im_start|>system
.<|im_end|>
<|im_start|>user
SFT<|im_end|>
<|im_start|>assistant
SFT Supervised Fine-Tuning...<|im_end|>- system: инструкция для модели (роль, стиль, ограничения)
- user: сообщение пользователя
- assistant: ответ модели — именно на этих токенах считается loss
- Каждая модель — свои спец-токены. HuggingFace tokenizer.apply_chat_template() делает это автоматически
Loss masking: считаем loss только на ответах
Ключевая идея SFT: модель должна учиться отвечать, а не попугайничать вопросы. Поэтому loss считается только на токенах assistant. Всё остальное — system prompt, вопрос юзера — маскируется (loss = 0). Это называется loss masking. Без него SFT превращается в тыкву: модель учится повторять вопросы вместо того, чтобы на них отвечать.
Loss считается только на assistant tokens. Токены system и user маскируются.
Instruction datasets: качество важнее количества
Для SFT не нужны миллионы примеров — хватит десятков тысяч, но хороших. SmolLM3 обучали на ~100K примеров (76M токенов). Каждый пример тщательно выбран: разнообразные задачи, правильные ответы, разные длины. Мусорные данные навредят больше, чем их отсутствие. Garbage in — garbage out, как всегда.
- Качество > количество: 100K хороших примеров лучше 1M плохих
- Diversity: задачи разных типов — QA, coding, math, creative writing, summarization
- Think/no_think: SmolLM3 паирит ответы с reasoning (<think>...) и без. Модель учится когда думать, а когда отвечать сразу
- Формат: единый chat template для всех примеров. Перемешивать форматы нельзя
Full fine-tuning vs LoRA
Full fine-tuning обновляет все веса модели — нужна куча GPU и памяти. LoRA (Low-Rank Adaptation) замораживает основные веса и добавляет маленькие адаптеры (~1-5% параметров). QLoRA ещё жаднее: модель в 4-bit, адаптеры в fp16 — можно файнтюнить 7B модель на одной видюхе. Для SFT часто хватает LoRA, но лабы вроде HuggingFace жарят full fine-tuning ради максимального качества.
💡 Подробнее про LoRA
Sequence packing: не тратим compute на пустоту
Примеры в SFT-датасете дико разной длины: один — 50 токенов, другой — 2000. Если паддить всё до максимальной длины, 95% вычислений уходит на бессмысленные padding-токены. GPU считает нули. Деньги горят. Sequence packing решает эту боль: несколько коротких примеров склеиваются в одну последовательность до max_length. Best-fit decreasing алгоритм упаковывает всё максимально плотно, как тетрис.
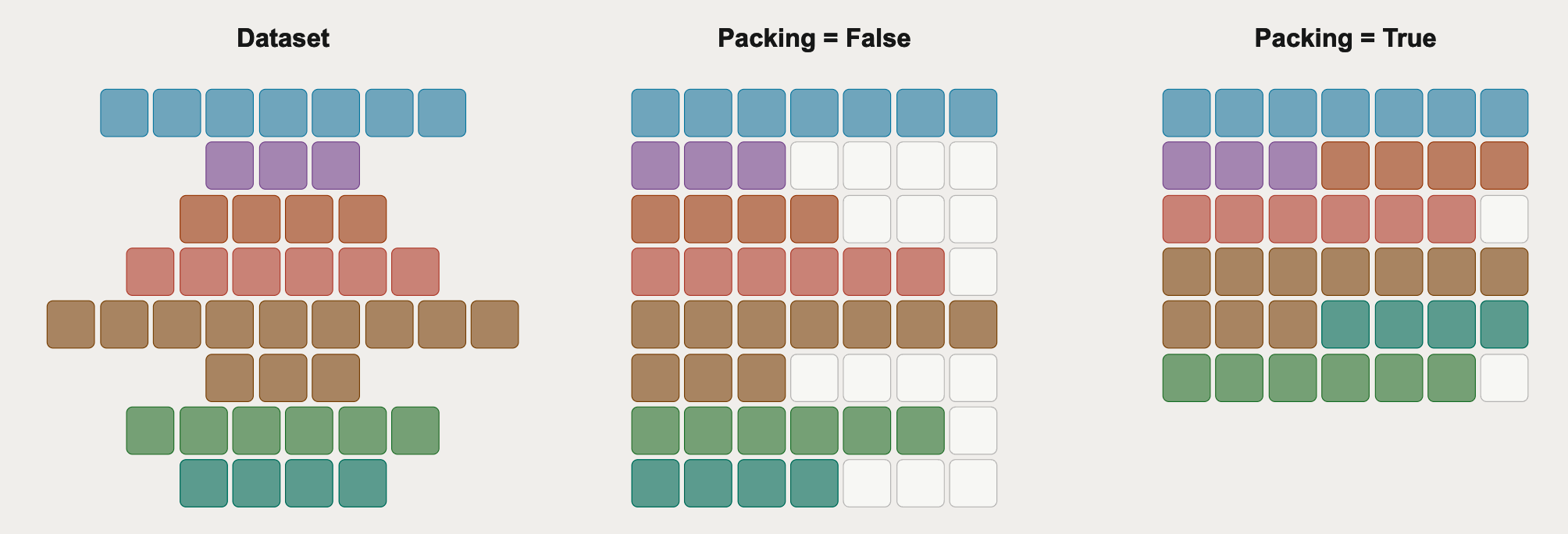
- Без packing: batch из коротких примеров = 80% padding, 20% полезных токенов
- С packing: несколько примеров в одну последовательность, padding < 5%
- Ускорение: 3-5x на коротких датасетах. Экономия GPU-часов = экономия денег
- TRL SFTTrainer поддерживает packing из коробки: packing=True
Learning rate и расписание
Главное правило SFT: learning rate на порядок ниже, чем при pre-training. Pre-training: ~3e-4. SFT: 3e-6 — 1e-5. Задрал LR? Получи catastrophic forgetting — модель забудет всё, что выучила за триллионы токенов. Месяцы тренировки коту под хвост. А вот больше эпох — сюрприз — лучше. SmolLM3 тренировали SFT целых 4 эпохи.
Distillation: учимся у сильной модели
Самый читерский способ получить хорошую модель — distillation. Берём умную модель (GPT-4, DeepSeek-R1), заставляем её сгенерить ответы на наш датасет, и скармливаем это слабой модели как targets для SFT. По сути, маленькая модель списывает у большой. DeepSeek показал: можно взять reasoning traces от R1 и научить мелкую модель (1.5B-70B) рассуждать почти так же круто. Дёшево, быстро, работает. Чит-код индустрии.
- Teacher → Student: сильная модель генерирует ответы, слабая учится их воспроизводить
- Reasoning traces: если teacher показывает chain-of-thought, student тоже учится рассуждать
- DeepSeek-R1-Distill: серия моделей 1.5B-70B, обученных на traces от R1. Qwen-32B-distill бьёт GPT-4o на math
- Стоимость: одна генерация teacher + SFT student ≈ в 100x дешевле, чем тренировка с нуля
🎯 На собеседовании
Junior
Middle
Senior
🎯 Запомни