RLHF и DPO
Alignment через RLHF, DPO, RLVR. Как модель учится быть полезной и безопасной.
RLHF и DPO — как научить модель быть полезной и безопасной
SFT (supervised fine-tuning) учит модель подражать — она копирует стиль и формат ответов из тренировочного датасета. Но подражание ≠ понимание. SFT-модель с одинаковой уверенностью процитирует Шекспира и сгенерирует инструкцию по взлому. Она не знает, что «полезно», а что «вредно» — у неё нет системы ценностей.
Alignment (выравнивание) решает эту проблему: модель учится человеческим предпочтениям — какие ответы лучше, какие хуже, где граница допустимого. Именно alignment превращает «base model, которая умеет продолжать текст» в ChatGPT, который реально помогает людям. Без alignment невозможна ни одна коммерческая LLM — это не опциональный шаг, а обязательная часть pipeline.
Большая картина: от предпочтений к aligned-модели
Весь alignment строится на одной идее: у людей есть предпочтения, и мы хотим научить модель их воспроизводить. Из двух ответов на один вопрос человек выбирает лучший — и эта простая информация «A лучше B» оказывается достаточной, чтобы кардинально улучшить поведение модели.
Alignment pipeline за 3 шага: Шаг 1. Собрать предпочтения. Модель генерирует пары ответов на вопросы. Аннотаторы (или сильная модель) выбирают лучший ответ из каждой пары. Получаем датасет: (prompt, chosen_response, rejected_response). Шаг 2. Превратить предпочтения в сигнал обучения. Два подхода: обучить отдельную reward model, которая оценивает качество ответа числом (RLHF), или напрямую выразить preference loss через policy (DPO). Шаг 3. Оптимизировать модель. RLHF использует PPO (RL-алгоритм), DPO — обычный supervised loss. Результат одинаковый: модель учится генерировать ответы, которые люди предпочли бы.

Почему SFT недостаточно: пределы подражания
SFT — это imitation learning: модель копирует поведение из примеров. Представь, что ты учишься водить, глядя видео. Ты запомнишь, как крутить руль на поворотах из видео — но что делать, когда тебя подрежут? Этого в обучающих данных не было.
Проблема 1: усреднение. Если в датасете на один и тот же вопрос есть лаконичный и развёрнутый ответы — модель научится генерировать что-то среднее, что не оптимально ни для кого. SFT минимизирует NLL (negative log-likelihood), а это эквивалент среднего по всем ответам.
Проблема 2: нет понимания качества. SFT не различает «отличный» и «нормальный» ответы — они оба в датасете, оба получают одинаковый градиент. Модель учится копировать формат, но не отличать хорошее от посредственного.
Проблема 3: ceiling эффект. Модель не может стать лучше своих учителей. Если в тренировочных данных нет идеальных ответов — SFT-модель их не сгенерирует. Alignment-методы, напротив, оптимизируют модель относительно предпочтений — и она может научиться комбинировать сильные стороны разных ответов, превосходя каждый в отдельности.
RLHF: Reinforcement Learning from Human Feedback
RLHF — оригинальный метод alignment, на котором взлетел ChatGPT. Идея: обучить отдельную нейросеть (reward model), которая предсказывает человеческие предпочтения, а затем использовать её как reward function для RL-оптимизации.
Pipeline состоит из трёх стадий: Стадия 1: SFT. Берём pre-trained LLM и дообучаем на качественных диалогах. Это стартовая точка — модель, которая уже умеет отвечать на вопросы, но пока «без ценностей». Стадия 2: Reward Model. Собираем preference data — пары (chosen, rejected) ответов на один промпт. Обучаем reward model предсказывать, какой ответ человек предпочтёт. На выходе — скалярная оценка «хорошести» ответа. Стадия 3: RL (PPO). Модель генерирует ответы, reward model оценивает их, PPO обновляет веса модели в направлении более высоких наград. KL-штраф не позволяет уйти далеко от SFT-модели.
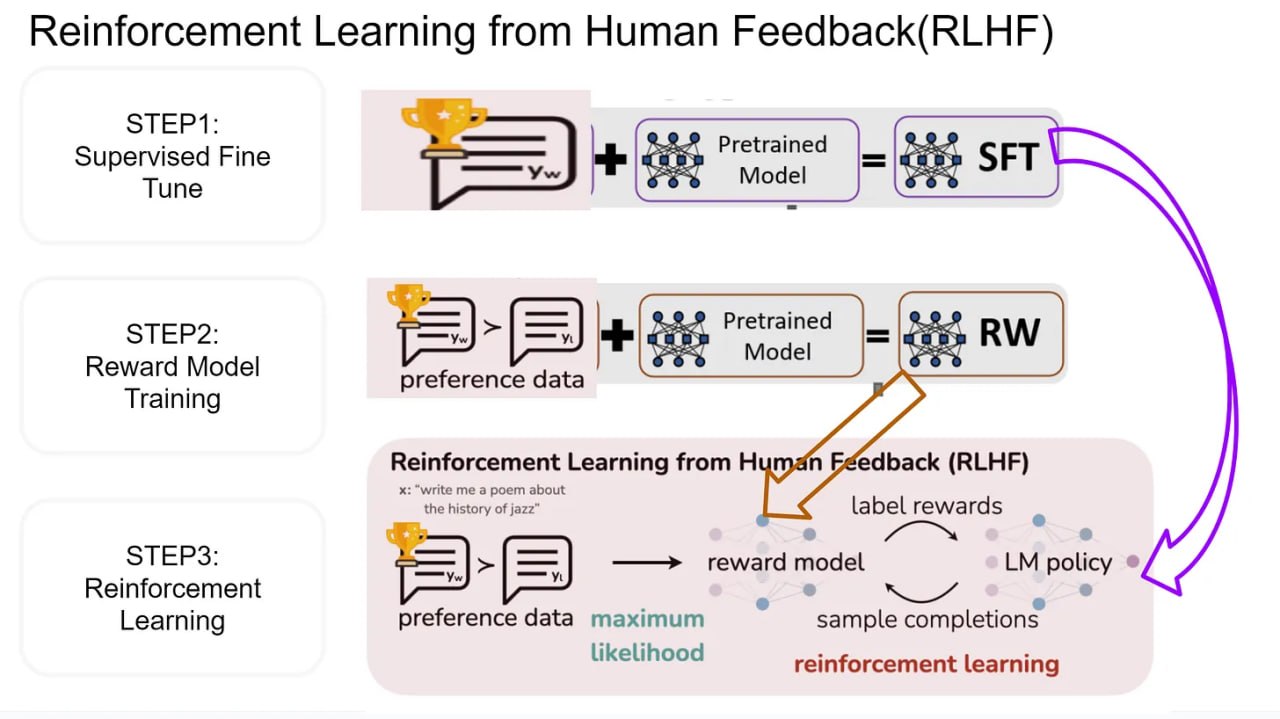
Reward Model: как научить оценивать ответы
Reward model (RM) — это нейросеть, чаще всего тот же LLM, у которого последний слой заменён на линейную проекцию в скаляр. На вход — (prompt, response), на выход — одно число r(x, y): «насколько этот ответ хорош».
Обучается RM на preference data по модели Bradley-Terry. Эта модель из теории сравнений утверждает: вероятность, что ответ y_w лучше y_l, пропорциональна экспоненте разницы их «сил» (rewards). Оптимизируем log-likelihood этого выражения:
Loss reward model: r_φ — reward model, y_w — preferred ответ, y_l — rejected, σ — сигмоида. Модель учится давать preferred ответу более высокий reward, чем rejected.
Обрати внимание: reward model учит разницу между ответами, а не абсолютные оценки. Это ключевой момент — абсолютный «рейтинг» ответа определить сложно, но сказать «A лучше B» гораздо проще и для человека, и для модели.
Качество данных — главный bottleneck
PPO: как RL оптимизирует модель
Имея reward model, запускаем RL-цикл. Модель (policy π_θ) генерирует ответ y на промпт x, reward model выдаёт оценку r(x, y). PPO (Proximal Policy Optimization) обновляет веса модели, чтобы максимизировать ожидаемый reward.
Но есть ловушка: если оптимизировать только reward, модель быстро находит эксплойты. Это reward hacking — как студент, который оптимизирует GPA, а не знания. Модель генерирует бессмысленные, но высокооценённые ответы: повторяет ключевые фразы, раздувает длину, соглашается со всем.
Решение — KL-штраф: ограничиваем, насколько далеко policy может уйти от reference model (обычно SFT-модель). Итоговый reward:
r_φ — reward model, β — коэффициент KL-штрафа (типично 0.01-0.2). Чем больше β — тем ближе к reference model, тем консервативнее обучение.
Зачем привязка к reference model? Три причины: 1. Предотвращает reward hacking. Модель не может уйти в «инопланетные» ответы, которые хакают reward. 2. Сохраняет знания. SFT-модель уже много знает — без KL-штрафа RL может это «забыть» (catastrophic forgetting). 3. Стабилизация обучения. RL-цикл по природе нестабилен — KL-штраф работает как якорь.
Почему PPO — это боль
DPO: alignment без reward model и RL
DPO (Direct Preference Optimization, 2023) — элегантное решение, которое выкидывает из RLHF reward model и RL целиком. Ключевой математический инсайт: оптимальную policy из RLHF-формулировки можно выразить в замкнутом виде, а reward model — аналитически через policy и reference model.
Это значит: вместо трёхстадийного pipeline (SFT → RM → PPO) можно напрямую оптимизировать policy на preference data. Один loss, один этап обучения, обычный supervised gradient descent:
DPO loss: y_w — preferred ответ, y_l — rejected, β — «температура» (аналог KL-штрафа в RLHF). π_θ — обучаемая policy, π_ref — reference model (замороженная SFT).
Что формула говорит интуитивно? Для каждой пары (chosen, rejected): • Вычисляем implicit reward каждого ответа: β·log(π_θ/π_ref) — насколько текущая policy «предпочитает» ответ по сравнению с reference model. • Хотим, чтобы implicit reward для chosen был больше, чем для rejected. • Сигмоида + log — стандартный binary cross-entropy loss на этой разнице. По сути, DPO учит модель: «увеличивай вероятность chosen ответов и уменьшай вероятность rejected — но не отходи далеко от reference model».
DPO vs RLHF: ключевые отличия
Зоопарк методов: RLHF, DPO, IPO, KTO — когда что
После DPO появилось множество вариаций. Основные:
IPO (Identity Preference Optimization) — фикс известной проблемы DPO. DPO предполагает, что preference data идеально описывается моделью Bradley-Terry — но в реальности аннотаторы ошибаются. IPO регуляризирует loss, предотвращая переобучение на шумные пары. На практике IPO полезен при noisy labels.
KTO (Kahneman-Tversky Optimization) — работает без парных данных вообще. Вместо пар (chosen, rejected) использует отдельные примеры с бинарной меткой: «хороший ответ» или «плохой ответ». Это дешевле собирать — thumb up / thumb down вместо сравнения пар. Loss вдохновлён теорией перспектив Канемана: потери (плохие ответы) штрафуются сильнее, чем награждаются выигрыши (хорошие).
ORPO (Odds Ratio Preference Optimization) — вообще не требует reference model. Объединяет SFT и preference optimization в один loss: NLL-часть учит модель генерировать хорошие ответы, odds ratio-часть отталкивает от плохих. Ещё проще, чем DPO — но пока менее проверен на масштабе.
- RLHF (PPO): максимальный контроль, on-policy обучение. Когда: крупные модели (100B+), критичные приложения, бюджет на инфраструктуру.
- DPO: простота и стабильность. Когда: основной выбор для большинства задач, качественные парные данные есть.
- IPO: DPO + устойчивость к шуму. Когда: данные от аннотаторов с низким agreement, noisy labels.
- KTO: не нужны пары. Когда: есть только thumbs up/down фидбек (продуктовые логи, пользовательские реакции).
- ORPO: не нужна reference model. Когда: ограниченные ресурсы, нет возможности держать 2 модели в памяти.
Практика: DPO-обучение с HuggingFace TRL
DPO — один из самых практичных alignment-методов. Минимальный код для обучения с библиотекой TRL (Transformer Reinforcement Learning):
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import DPOConfig, DPOTrainer
from peft import LoraConfig # QLoRA для экономии памяти
# 1. Модель и токенизатор
model_name = "meta-llama/Llama-3.1-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype="bfloat16", device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
# 2. Данные: каждая строка = {prompt, chosen, rejected}
dataset = load_dataset("argilla/ultrafeedback-binarized-preferences")
# 3. LoRA — обучаем только ~0.5% параметров
peft_config = LoraConfig(
r=16, lora_alpha=32, lora_dropout=0.05,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
task_type="CAUSAL_LM",
)
# 4. DPO-обучение
training_args = DPOConfig(
output_dir="./dpo-llama",
beta=0.1, # «температура» — баланс quality vs diversity
learning_rate=5e-7, # для DPO lr обычно ниже, чем для SFT
num_train_epochs=1, # 1-3 эпохи, больше — переобучение
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
bf16=True,
logging_steps=10,
)
trainer = DPOTrainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
processing_class=tokenizer,
peft_config=peft_config,
)
trainer.train()Гиперпараметры DPO — на что обратить внимание
Как собирают preference data
Качество preference data определяет качество alignment. Вот основные способы сбора — от дорогого к дешёвому:
- Human annotation. Аннотаторы сравнивают пары ответов. Дорого ($2-10 за пару), но gold standard. ChatGPT обучался именно так. Требует чётких гайдлайнов и контроля качества.
- LLM-as-judge. GPT-4, Claude или другая сильная модель оценивает пары. В 10-50× дешевле людей, коррелирует с человеческими оценками на 70-85%. Основной способ в 2024-2025.
- Rejection sampling. Модель генерирует N ответов (N=16-64), лучший по reward model = chosen, худший = rejected. Полностью автоматический, но нужна хорошая reward model.
- Strong-vs-weak. Ответ сильной модели (GPT-4) = chosen, ответ слабой (GPT-3.5) = rejected. Простой proxy для предпочтений.
- Product signals. Thumbs up/down, regenerate, edit — пользователи дают implicit feedback бесплатно. Шумный, но масштабируемый.
RLVR: RL с верифицируемыми наградами
Отдельная ветка alignment — RLVR (RL with Verifiable Rewards). Идея: для задач с объективным ответом (math, code) reward model не нужна вообще. Правильно решил — +1, неправильно — 0. Проверяем автоматически: сверяем число, запускаем тесты.
DeepSeek-R1 продемонстрировал мощь этого подхода: GRPO (Group Relative Policy Optimization) на math/code задачах, без human preferences. Модель сама научилась рассуждать — появились emergent behaviors: self-correction, длинный chain-of-thought, рефлексия. Никто этому не учил — возникло из оптимизации reward.
RLVR vs RLHF
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Alignment — обязательный этап создания LLM. SFT учит модель формату, но не учит различать хорошее от плохого. Alignment заполняет этот пробел через человеческие предпочтения.
Если запомнить одну вещь из этой ноды: RLHF = preference data → reward model → PPO (мощно, но сложно). DPO = preference data → один loss (проще, дешевле, часто не хуже). Оба метода решают одну задачу разными путями — выбор зависит от масштаба, данных и бюджета.
Дальше: Fine-tuning LLM — как адаптировать модель к конкретной задаче (LoRA, QLoRA). RAG — как дать модели доступ к внешним знаниям без переобучения.
Материалы
Статья Rafailov et al. Как вывести DPO loss из RLHF и почему это эквивалентно.
Статья OpenAI про RLHF pipeline. Три стадии: SFT → RM → PPO. Основа ChatGPT.
Практический гайд по DPO-обучению с кодом. Быстрый старт для экспериментов.
Подробный пост с визуализациями всего RLHF pipeline. Хороший обзор для начинающих.
GRPO, RLVR, emergent reasoning. Как RL без SFT научил модель рассуждать.