Продвинутый post-training
GRPO, RLVR, KTO/ORPO/APO, on-policy distillation, DeepSeek-R1 pipeline.
Advanced Post-Training — GRPO, RLVR, distillation и beyond
SFT и DPO — фундамент, но frontier reasoning models идут дальше: GRPO вместо PPO, RLVR с верифицируемыми наградами, on-policy distillation, in-flight weight updates. DeepSeek-R1-Zero показал, что чистый RL без SFT порождает emergent reasoning behavior. Kimi K2 использует self-critique rubrics. В этом гайде — конкретные числа, формулы и pipeline из открытых отчётов.

GRPO vs PPO — почему GRPO побеждает
PPO с per-token KL penalty неявно штрафует длину ответа (KL последовательности раскладывается в сумму per-token KL). Для reasoning моделей, которые должны мыслить длинно, это вредно. GRPO (Group Relative Policy Optimization) не требует value model — экономит compute. DeepSeek: на MATH задачах GRPO стабильно лучше PPO с λ=1.0. Параметры DeepSeek R1-Zero GRPO: 10.4K steps, batch 512, lr 3e-6, KL coeff 0.001, reference policy replacement каждые 400 steps.
# GRPO: Group Relative Policy Optimization (упрощённо)
import torch
import torch.nn.functional as F
def grpo_loss(model, ref_model, prompts, responses, rewards, kl_coeff=0.001):
"""GRPO loss без value model. Из DeepSeek-R1."""
# 1. Считаем log-probs текущей и reference policy
logprobs = model.log_prob(prompts, responses) # (batch, group_size)
ref_logprobs = ref_model.log_prob(prompts, responses)
# 2. Group-relative advantage: нормализуем rewards внутри группы
mean_r = rewards.mean(dim=-1, keepdim=True)
std_r = rewards.std(dim=-1, keepdim=True) + 1e-8
advantages = (rewards - mean_r) / std_r # z-score внутри группы
# 3. Policy gradient + KL penalty
ratio = (logprobs - ref_logprobs).exp()
clipped = torch.clamp(ratio, 0.8, 1.2) # PPO-style clipping
pg_loss = -torch.min(ratio * advantages, clipped * advantages).mean()
kl = (ref_logprobs - logprobs).mean() # KL divergence
return pg_loss + kl_coeff * kl
# DeepSeek R1-Zero: 10.4K steps, batch=512, lr=3e-6, KL=0.001
# Reward: accuracy (correct=+1) + format (thinking tags=+0.5)RLVR — RL with Verifiable Rewards
RLVR, популяризованный DeepSeek-R1, использует верификаторы вместо learned reward models: математика — correct answer = +1; код — pass all tests = +1. Это масштабируемее и объективнее. Verifiers дают стабильный сигнал (нет reward drift), KL control предотвращает policy collapse. Для hybrid reasoning (/no_think) наивный GRPO приводит к reward hacking — модель начинает emit длинный CoT. Решение: overlong completion penalty в диапазоне 2.5K-3K tokens.
DPO Alternatives: KTO, ORPO, APO
- KTO (Kahneman-Tversky Optimization) — не нужны пары: каждый sample помечен как desirable/undesirable. Идея из behavioral economics
- ORPO (Odds Ratio PO) — интегрирует PO с SFT loss через odds ratio. Не нужна reference model (в отличие от DPO). Compute-efficient
- APO-zero — форсирует y⁺ вверх И y⁻ вниз (DPO оптимизирует только разницу). APO-down — push оба вниз, если y⁺ ниже текущего quality
- HuggingFace: APO-zero показал лучший out-of-domain performance среди всех DPO вариантов
On-Policy Distillation
Вместо preference pairs — сигнал от сильной teacher model. Student сэмплирует ответы на каждом шаге, KL divergence между student/teacher logits даёт learning signal. Дешевле GRPO: нужен 1 rollout (vs несколько), graded одним forward-backward pass. HuggingFace GOLD framework позволяет distill любого teacher в любого student. Thinking Machines показали, что distillation + 70% mid-training восстанавливает behavior после catastrophic forgetting.

Kimi K2 RL Objective
Kimi K2 адаптирует policy optimization из K1.5 с squared loss вместо clipped ratio. Mean reward r̄(x) как baseline снижает variance, τ-regularization по KL divergence стабилизирует обучение:
Kimi K2 RL loss: squared отклонение от mean reward + KL penalty с коэффициентом τ
In-Flight Updates (Intellect 3)
Prime Intellect 3 использует CPU orchestrator между training и inference кластерами. Orchestrator непрерывно запрашивает trainer, обновляет inference pool новой policy. Длинный rollout может генерироваться несколькими policies — это off-policy bias. IcePop ограничивает это через importance sampling clipping:
IcePop: importance weight k за пределами [α, β] обнуляется. Default: α=0.5, β=5 (асимметрично)
Self-Critique Rubric (Kimi K2)
K2 actor генерирует k rollouts, K2 critic ранжирует через pairwise evaluations по rubrics. Три типа rubrics: core (фундаментальные ценности), prescriptive (против reward hacking) и human-annotated (для специфических инструкций). Critic model refines через verifiable signals — transfer learning grounds субъективные суждения в верифицируемых данных. Critic рекалибруется вместе с эволюцией policy.
Curriculum Learning
Задачи сортируются в difficulty pools (easy/medium/hard) на основе observed solve rate. Intellect 3: 8 генераций Qwen3-4B-Thinking на задачу для math/code, 16 для science/logic. Избегаем trivially easy (нет сигнала) и impossibly hard (нет градиента в GRPO). Kimi K2 использует pass@k accuracy SFT модели для определения сложности.
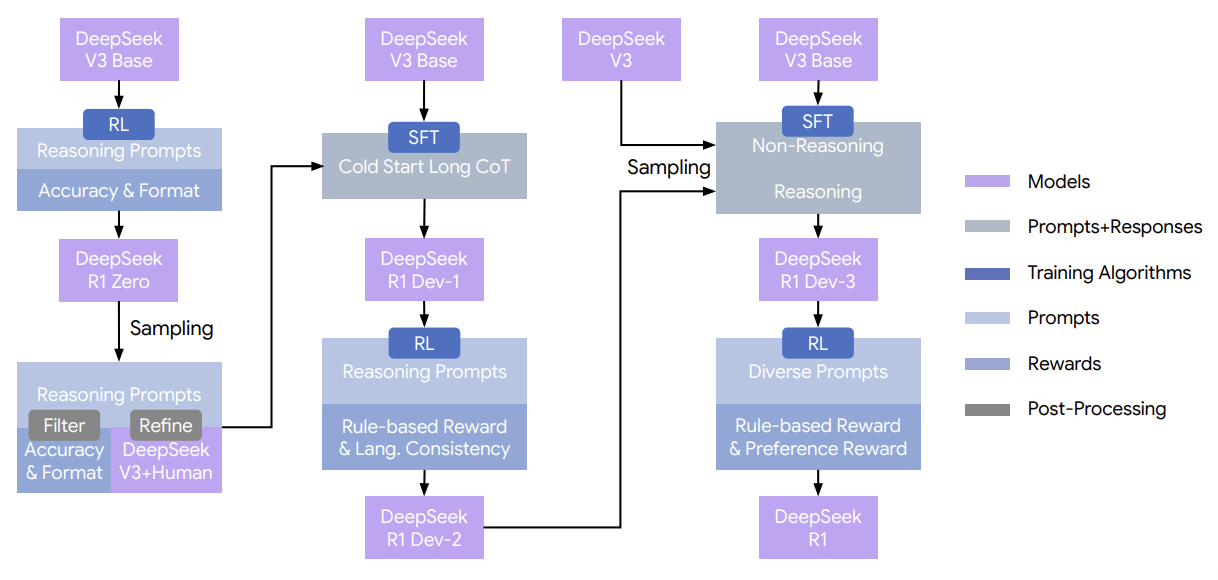
DeepSeek-R1-Zero — Emergent Reasoning
R1-Zero — уникальный эксперимент: pure RL (GRPO) без SFT. Два типа наград: accuracy (правильность ответа) и format (мысли между thinking tags). Результат: robust reasoning capabilities из чистого RL. Emergent behaviors: рефлексия (переоценка шагов), альтернативные подходы к задачам. Рефлексивные слова («wait», «mistake») выросли в 5-7 раз. Примечательно: до step 4K-7K — редкое использование, после step 8K — значительные spikes.
Greedy decoding на reasoning моделях увеличивает repetition rate и variability — объясняется risk aversion и inductive bias для temporally correlated errors (модель переизбирает ранее выбранные действия, создавая петли).
🎯 На собеседовании
Junior
Middle
Senior
💡 Takeaway