Стабильность обучения и оптимизаторы
Logit softcapping, z-loss, AdamW, Muon, MuonClip, LR schedules, batch size scaling.
Training Stability и Optimizers — как не уронить тренировку на миллиарде параметров
Стабильность тренировки — не про экзотические трюки. Это про правильные defaults, без которых твои $100M на GPU улетят в NaN. Loss spikes, расходящиеся логиты, gradient explosions — рутинная боль при масштабе. Тут разбираем: logit softcapping, z-loss, QK-norm, AdamW vs Muon, MuonClip и типичные причины, почему тренировка падает.
Logit Softcapping
Logit softcapping — это как ограничитель оборотов в двигателе. Логиты начинают улетать в космос? tanh мягко прижимает их обратно к земле, в диапазон (−c, +c). В отличие от hard clipping (где градиент просто умирает на границе), softcapping гладкий и дифференцируемый. Gemma 2 ставит его на attention logits (cap=50) и LM head (cap=30). HuggingFace выбрали его вместо z-loss.
Logit softcapping: значения плавно сжимаются в (-c, +c). Gemma 2: c=50 для attention, c=30 для LM head
Подводный камень: softcapping несовместим с Flash Attention / SDPA при тренировке — эти fused kernels ожидают стандартный attention. Придётся юзать attn_implementation="eager". Да, медленнее. Зато не взрывается. На инференсе SDPA работает с минимальной потерей quality.
z-loss и QK-norm
z-loss штрафует модель за большие логиты через log²(Z) от softmax denominator. Звучит полезно, но HuggingFace протестировали на 1B — ноль эффекта на loss и evals. Не стоит overhead. QK-norm (LayerNorm на Q,K) стабилизирует attention logits, но внимание: исследователи RNoPE показали, что нормализация вредит long-context — убирает magnitude info и де-акцентирует релевантные токены. Лечим одно, ломаем другое.
z-loss: Z — softmax denominator. Штрафует модель за большой масштаб логитов
AdamW — всё ещё дефолт
AdamW — как Toyota Camry. Ничего модного, но работает и не ломается. Несмотря на 10+ лет, он всё ещё дефолт. Адаптивные learning rates на каждый параметр через moving averages моментов градиента + weight decay. Гиперпараметры окаменели: λ=0.1, β₁=0.9, β₂=0.95, ε=10⁻⁸. Все frontier модели плюс-минус на этих числах.
AdamW: weight decay (1-αλ) + adaptive step size. m̂ и v̂ — bias-corrected moments
import torch
def logit_softcap(logits: torch.Tensor, cap: float = 30.0) -> torch.Tensor:
""Gemma 2-style logit softcapping.
(-cap, +cap) tanh.
""
return cap * torch.tanh(logits / cap)
# Пример: логит 100.0 → 30.0 * tanh(100/30) ≈ 30.0 (почти cap)
# Логит 15.0 → 30.0 * tanh(15/30) ≈ 30.0 * 0.46 ≈ 13.9 (мягкое сжатие)
# Логит 5.0 → 30.0 * tanh(5/30) ≈ 30.0 * 0.165 ≈ 4.95 (почти без изменений)
# В Gemma 2:
# - attention logits: cap=50 (до softmax)
# - LM head logits: cap=30 (перед cross-entropy)
# ⚠️ Несовместимо с Flash Attention при тренировке!Muon — матричный оптимизатор
Muon — свежий претендент на трон. В отличие от AdamW, который работает поэлементно, Muon мыслит матрицами целиком. Newton-Schulz итерация аппроксимирует matrix sign function, нормализуя сингулярные значения. Особенно эффективен при большом batch size. Arcee Trinity юзает гибрид: Muon для hidden layers, AdamW для embedding/output. Каждому слою — свой оптимизатор. Звучит как overkill? Работает.
Newton-Schulz5: итеративно применяя f, аппроксимируем sign function — нормализует сингулярные значения
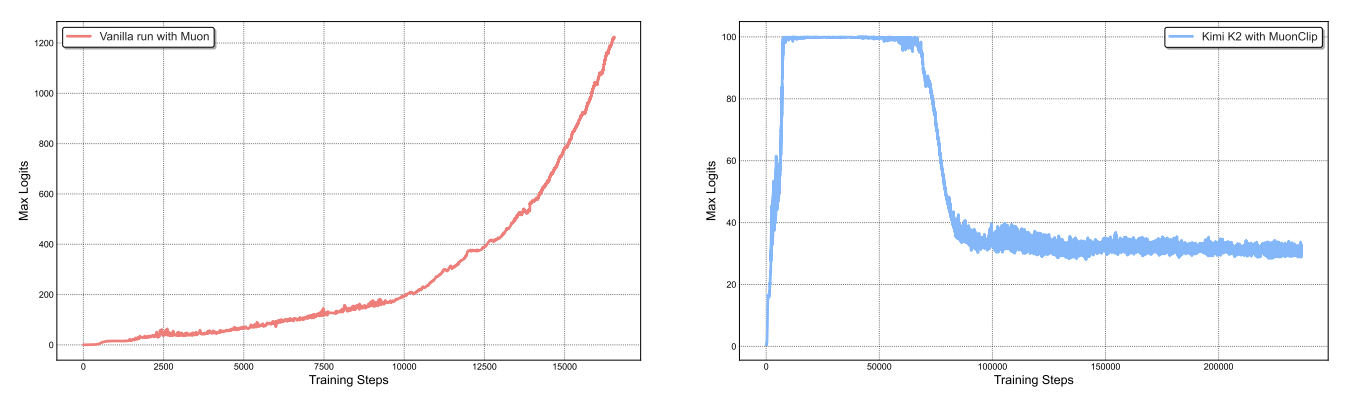
MuonClip — стабилизация от Kimi K2
MuonClip — ответ Kimi K2 на exploding attention logits при масштабе. Идея: для каждой attention head считаем максимальный логит. Если он превысил порог τ — мягко масштабируем query и key weights вниз. Per-head clipping: γ_h = min(1, τ/S_max^h) — не трогаем головы, которые ведут себя нормально. С MLA сложнее (K проецируются из латента), но принцип тот же.
Максимальный attention logit для головы h — метрика для срабатывания MuonClip
Learning Rate Schedules

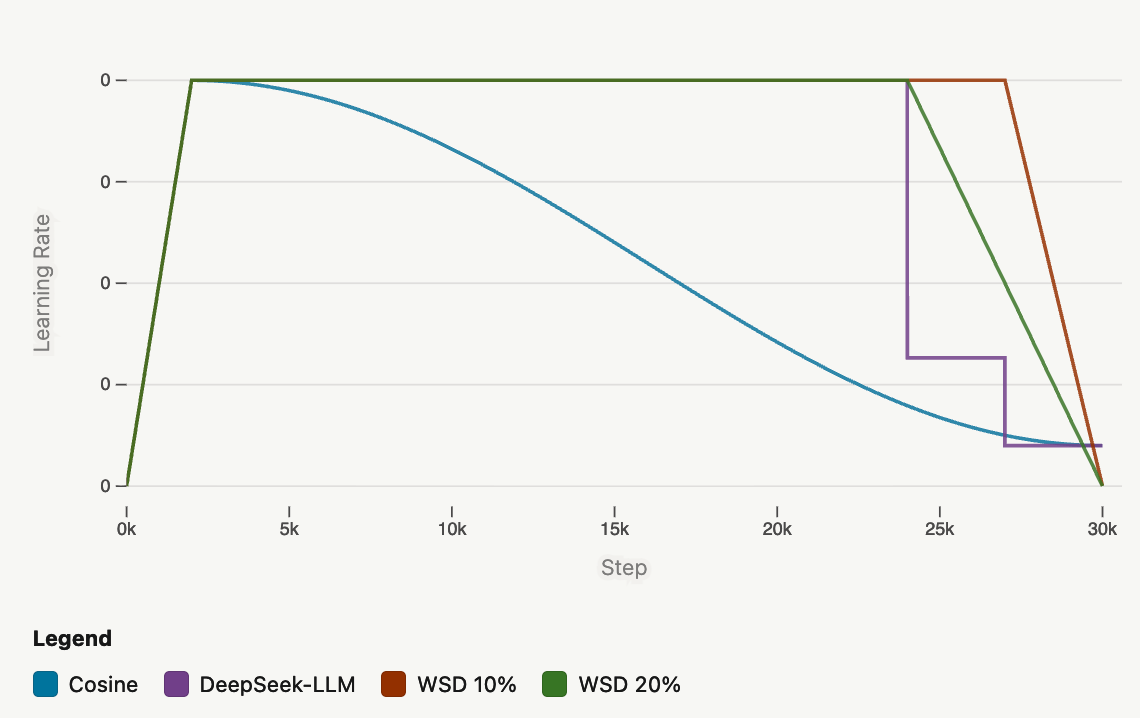
- Cosine annealing — классика, но inflexible: period должен точно совпадать с длительностью тренировки
- WSD (Warmup-Stable-Decay) — 10-20% на decay. SmolLM3: 2e-4 lr. Kimi K2: 10T tokens @ 2e-4, затем 5.5T cosine decay до 2e-5
- Multi-step — discrete drops (80/10/10 или 70/15/15). DeepSeek-V3: cosine между drops + constant phase
- WSD особенно удобен для ablations: можно перетренировать только end portion, не перезапуская с начала
Batch Size и Critical Batch Size
Critical batch size растёт по ходу тренировки: в начале модель учится жадно (маленький batch ок), потом стабилизируется и хочет больший batch для эффективности. При увеличении batch в k раз — lr масштабируй на √k, чтобы дисперсия обновлений не улетела:
Дисперсия обновления: η² × Σ/B. При B×k нужно η×√k для сохранения Var(Δw)
Common Training Failures
- High learning rate — самая частая причина loss spikes
- Bad data batches — специфические комбинации данных и parameter states вызывают spikes
- Poor initialization — OLMo2: N(0, 0.02) стабильнее scaled initialization
- Data filtering — OLMo2: удаление документов с 32+ повторениями 1-13 token spans значительно снижает частоту spikes
- Precision — fp16 опасен для больших моделей, bf16 — стандарт
- Imbalanced minibatches при sequence packing — gradient variance дестабилизирует тренировку
🎯 На собеседовании
Junior
Middle
Senior
💡 Takeaway