Позиционные кодирования и длинный контекст
RoPE, YaRN, RNoPE, document masking. Как модели масштабируются от 4K до 128K+ токенов.
Позиционные кодировки и длинный контекст
Без позиционной информации трансформер не видит разницы между "собака съела кошку" и "кошка съела собаку" — для него это bag of words. За 7 лет индустрия прошла путь от жёстко заданных синусоид до подхода "а давайте вообще без PE". Каждый шаг расширял максимальный контекст и решал свои проблемы.
1. Sinusoidal PE (Vaswani et al., 2017)
Оригинальный Transformer использовал детерминированные позиционные кодировки: каждой позиции pos и каждому измерению i сопоставляется значение по формуле sin/cos с разной частотой. Идея в том, что разные частоты дают модели "линейки" разного масштаба — одни компоненты меняются быстро (различают соседние позиции), другие медленно (различают далёкие).
Чётные измерения — sin, нечётные — cos. Чем больше i, тем ниже частота. d — размерность модели
import torch
import math
def sinusoidal_pe(max_len: int, d_model: int) -> torch.Tensor:
"""Генерирует таблицу синусоидальных PE. Shape: (max_len, d_model)"""
pe = torch.zeros(max_len, d_model)
position = torch.arange(max_len).unsqueeze(1).float() # (max_len, 1)
div_term = torch.exp(
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)
) # (d_model/2,)
pe[:, 0::2] = torch.sin(position * div_term) # чётные
pe[:, 1::2] = torch.cos(position * div_term) # нечётные
return pe
# Пример: первые 3 позиции при d_model=4
# pos=0: [sin(0), cos(0), sin(0), cos(0)] = [0.0, 1.0, 0.0, 1.0]
# pos=1: [sin(1), cos(1), sin(0.01), cos(0.01)] ≈ [0.84, 0.54, 0.01, 1.0]
# pos=2: [sin(2), cos(2), sin(0.02), cos(0.02)] ≈ [0.91, -0.42, 0.02, 1.0]Проблема: PE-таблица генерируется для позиций 0..max_len−1. Модель обучается с max_len=512 — и никогда не видит позиции 513+. Технически можно вычислить sin(513/...), но attention-паттерны не обучены на таких значениях. Результат: деградация качества за пределами тренировочной длины.
📌 Sinusoidal PE — абсолютные
2. Learnable PE (BERT, GPT-2)
Вместо формулы — просто обучаемая таблица. nn.Embedding(max_len, d_model) — каждая позиция имеет свой вектор, который учится через backprop вместе с остальными параметрами модели.
import torch.nn as nn
class LearnablePE(nn.Module):
def __init__(self, max_len: int, d_model: int):
super().__init__()
self.pe = nn.Embedding(max_len, d_model) # обучаемая таблица
def forward(self, x):
# x: (batch, seq_len, d_model)
positions = torch.arange(x.size(1), device=x.device)
return x + self.pe(positions) # прибавляем к token embeddings
# BERT: max_len=512, GPT-2: max_len=1024- ✅ Плюс: модель учит оптимальные позиционные паттерны — гибче формулы
- ✅ Плюс: на практике работают не хуже синусоид (иногда чуть лучше)
- ❌ Минус: жёсткий max_len. Позиция 1025 для GPT-2 просто не существует
- ❌ Минус: абсолютные — те же ограничения что у синусоид
3. ALiBi — Attention with Linear Biases (2022)
ALiBi — первый радикальный отход от "добавь PE к embedding". Вместо этого — линейный штраф в attention scores: чем дальше ключ от запроса, тем сильнее штраф. Нет обучаемых параметров. Нет PE в embedding вообще.
bias = −m × |i − j|. m — фиксированный коэффициент, свой для каждой attention head (геометрическая прогрессия: m₁=1/2, m₂=1/4, m₃=1/8, ...)
Каждая голова получает свой коэффициент m. Головы с большим m сильнее штрафуют дальние токены — фокус на локальном контексте. Головы с маленьким m — мягкий штраф, видят далеко. Модель получает набор "линз" с разным фокусным расстоянием.
- ✅ Нет обучаемых параметров — zero overhead, коэффициенты m фиксированы
- ✅ Экстраполяция: обучена на 1K, работает на 2K+ (потому что bias — линейная функция, привычная для модели)
- ✅ Простота: одна строка кода в attention
- ❌ Экстраполяция ограничена: на 4-8× от тренировочной длины качество падает
- ❌ Уступает RoPE на длинных контекстах (линейный bias слишком грубый)
- 📎 Используется: BLOOM (176B), MPT-7B/30B
4. RoPE — Rotary Position Embedding (2021)
RoPE — доминирующий подход в современных LLM. Вместо того чтобы прибавить номер позиции к embedding или штрафовать attention, мы ВРАЩАЕМ пары компонент Q и K-векторов. Каждая пара крутится на угол, пропорциональный позиции токена. При вычислении attention скалярное произведение повёрнутых Q и K автоматически кодирует относительное расстояние — через разность фаз вращения.
Угол вращения для k-й пары. pos — позиция токена, base — базовая частота (обычно 10000), d — размерность Q/K
Почему вращение, а не сложение? При вращении Q на угол α и K на угол β, их скалярное произведение зависит только от (α − β) — то есть от разности позиций. Это автоматически даёт relative position encoding без явного вычисления расстояний. В отличие от синусоид (абсолютные), RoPE кодирует именно "кто от кого на сколько далеко".
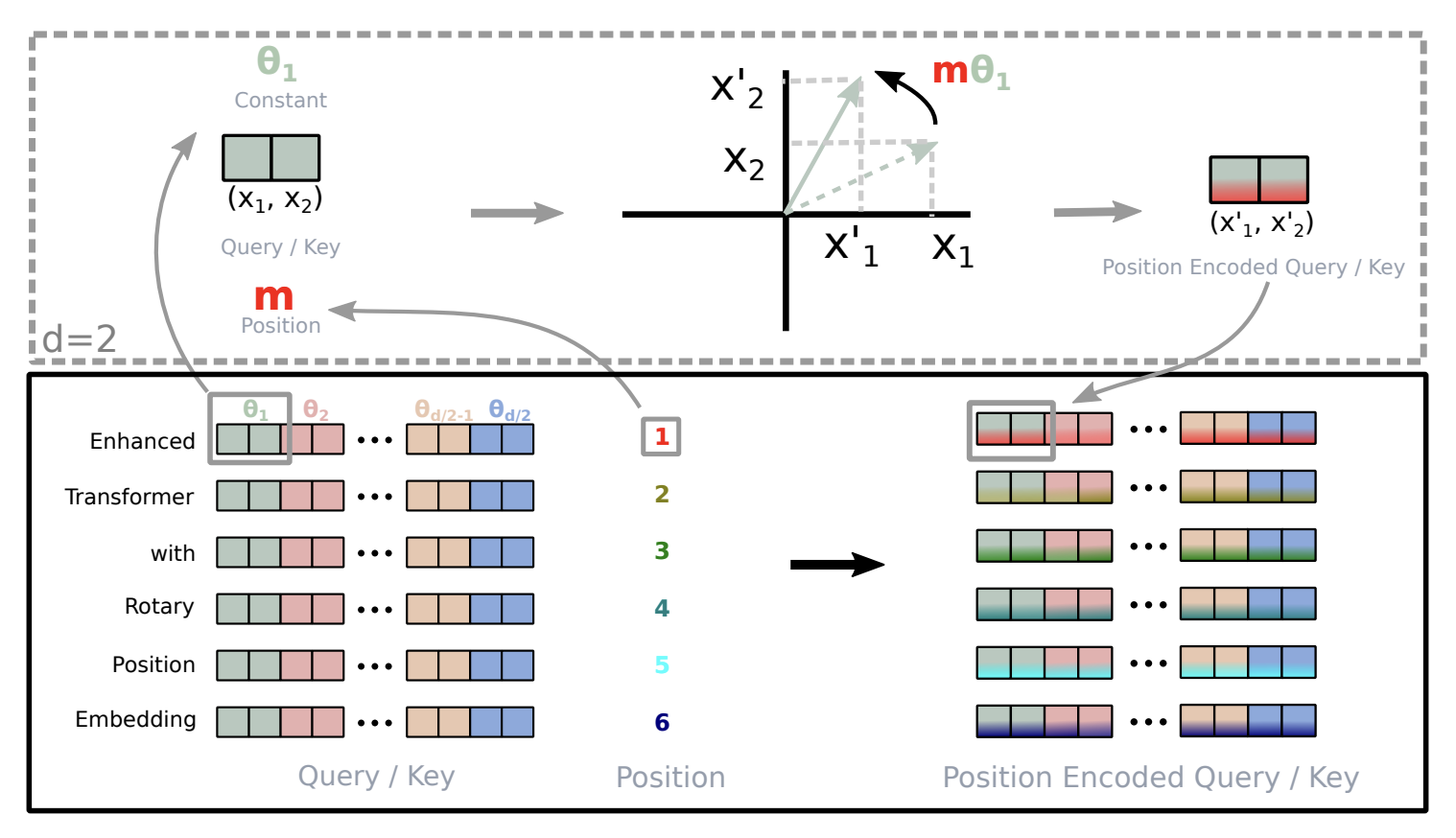
import torch
def apply_rope(x, positions, base=10000):
"" RoPE Q K .
x: (batch, seq, n_heads, d_head)
positions: (batch, seq)
""
d = x.shape[-1]
# Частоты: 1/base^(2k/d) для каждой пары компонент
freqs = 1.0 / (base ** (torch.arange(0, d, 2, device=x.device) / d))
# Углы вращения: position × frequency
angles = positions.unsqueeze(-1) * freqs # (batch, seq, d/2)
cos, sin = angles.cos(), angles.sin()
# Вращаем пары компонент: (x0, x1) → (x0·cos - x1·sin, x0·sin + x1·cos)
x_even, x_odd = x[..., 0::2], x[..., 1::2]
rotated = torch.stack([
x_even * cos - x_odd * sin,
x_even * sin + x_odd * cos
], dim=-1).flatten(-2)
return rotated
# При base=10000 и позиции=4000 → последние пары вращаются на ~0.4 рад
# При позиции=64000 → те же пары на ~6.4 рад → модель такого НЕ видела!
# Решение: ABF увеличивает base до 2M → углы снова маленькиеПроблема RoPE: если модель обучалась на контексте 4K, она видела только определённый диапазон углов. На 64K углы вылетают за знакомую область — модель паникует. Качество деградирует. Именно поэтому появились методы расширения контекста: ABF и YaRN.
- ✅ Relative PE: скалярное произведение зависит только от разности позиций
- ✅ Стандарт де-факто: LLaMA, Mistral, Qwen, Gemma, DeepSeek, GPT-4
- ✅ Совместим с KV-cache: вращение применяется один раз при вычислении Q/K
- ❌ Не экстраполирует "из коробки": нужен ABF/YaRN для расширения контекста
5. NoPE — No Position Embedding
NoPE — радикальный подход: убираем позиционные кодировки ПОЛНОСТЬЮ. Ни синусоид, ни вращений, ни штрафов в attention. Звучит безумно — откуда модель узнает порядок токенов?
Как это работает: causal mask = implicit position
Ключевая идея: в авторегрессионной (causal) модели маска внимания уже несёт позиционную информацию. Каждый токен видит ровно столько предыдущих токенов, сколько позиций перед ним:
- Токен на позиции 0 видит 0 предыдущих токенов (только себя)
- Токен на позиции 1 видит 1 предыдущий токен
- Токен на позиции 5 видит 5 предыдущих токенов
- Токен на позиции 1000 видит 1000 предыдущих токенов
Модель учится: "если я вижу ровно N предыдущих токенов в attention — значит, я на позиции N". Количество видимых токенов = неявный номер позиции. Это работает, потому что каузальная маска — строго нижнетреугольная, и каждая строка уникальна по количеству видимых элементов.
🎯 Конкретный пример
import torch
def causal_attention_nope(Q, K, V):
""Attention . .
Q, K, V: (batch, n_heads, seq_len, d_head)
""
seq_len = Q.size(-2)
# Causal mask: нижнетреугольная матрица
# Каждая строка i содержит ровно (i+1) незамаскированных элементов
mask = torch.triu(
torch.full((seq_len, seq_len), float('-inf')),
diagonal=1
)
# mask[0] = [0, -inf, -inf, -inf] ← видит 1 токен (себя)
# mask[1] = [0, 0, -inf, -inf] ← видит 2 токена
# mask[2] = [0, 0, 0, -inf] ← видит 3 токена
# mask[3] = [0, 0, 0, 0 ] ← видит 4 токена
scores = Q @ K.transpose(-2, -1) / (Q.size(-1) ** 0.5)
scores = scores + mask # позиция неявно закодирована в маске
attn = torch.softmax(scores, dim=-1)
return attn @ V
# Это ВСЁ. Никаких PE. Модель учится определять позицию
# по количеству видимых токенов в attention паттерне.- ✅ Нет проблемы экстраполяции — нечему экстраполировать. Углы не улетают, частоты не ломаются, потому что их нет
- ✅ Идеально для длинного контекста: позиция 1M — просто ещё одна строка в маске с 1M видимыми токенами
- ✅ Меньше параметров и вычислений: нет RoPE-вращения, нет PE-таблиц
- ❌ Хуже на коротких задачах с reasoning — позиция неявная (implicit), модель не может точно различить "3-й или 4-й элемент в списке"
- ❌ Хуже на задачах с знанием (knowledge retrieval) — без явной позиции сложнее "запомнить, что факт X был на 5-й позиции"
- ❌ Работает только для causal (авторегрессионных) моделей — в bidirectional (BERT) маски нет → позиция неоткуда
6. RNoPE — Rotary and No Position Embeddings
Если RoPE хорош для локальных отношений, а NoPE — для длинного контекста, почему бы не совместить? RNoPE чередует слои: часть слоёв с RoPE (ловят точную локальную позицию), часть без PE (NoPE-слои, ловят дальние зависимости через каузальную маску).
Интуиция: для понимания локальной грамматики ("прилагательное перед существительным") нужна точная позиция — RoPE. Для ответа на вопрос по документу в 100K токенов нужно видеть далёкие связи — NoPE. RNoPE даёт модели оба инструмента одновременно.
- RoPE-слои: точная локальная позиция (кто рядом, порядок слов)
- NoPE-слои: дальние зависимости без ограничений по расстоянию
- Ablation HuggingFace: на коротких задачах все варианты (RoPE, NoPE, RNoPE) работают одинаково. Но на long-context RNoPE — лучший
- SmolLM3 выбрал RNoPE как основу + поэтапное расширение контекста
💡 Почему именно чередование?
7. Расширение контекста: ABF vs YaRN
Обе техники решают одну проблему: модель обучена на 4K контексте с RoPE, а нужно 128K. Углы вращения на позиции 128K улетают далеко за пределы того, что модель видела. Как "вернуть" углы в знакомый диапазон?
ABF — Adjusted Base Frequency
Тупо и гениально: увеличиваем base в RoPE (10000 → 2000000). Формула: θ = pos / base^(k/d). Больше base → меньше угол при той же позиции. Углы на позиции 128K с base=2M попадают в тот же диапазон, что углы на позиции 4K с base=10K. Одна строка кода, работает.
YaRN — Yet another RoPE extensioN
Проблема ABF: сжимая ВСЕ частоты одинаково, мы теряем разрешение — модель хуже различает соседние позиции. YaRN решает это неоднородной интерполяцией: высокочастотные компоненты (различают соседей) — оставляем как есть, низкочастотные (дальний контекст) — интерполируем сильнее. Плюс scaling factor для attention logits, компенсирующий изменение распределения.
- ABF: одна строка (base=2M), достаточно для умеренного расширения (4K→32K, 32K→64K)
- YaRN: сложнее, но лучше для больших прыжков (64K→128K). Неоднородная интерполяция сохраняет локальное разрешение
- Практика: сначала ABF для первых этапов, YaRN для финального расширения
- Пример SmolLM3: 4K→32K (ABF, base=2M) → 64K (ABF, base=5M) → 128K (YaRN от 64K чекпоинта)
💡 Почему YaRN от 64K, а не от 32K?
8. Сравнительная таблица: модель → PE → контекст
- Transformer (2017) — Sinusoidal → 512 токенов
- BERT (2018) — Learnable → 512 токенов
- GPT-2 (2019) — Learnable → 1 024 токена
- BLOOM-176B (2022) — ALiBi → 2 048 токенов
- MPT-7B/30B (2023) — ALiBi → 8 192 токена
- LLaMA 1 (2023) — RoPE → 2 048 токенов
- LLaMA 2 (2023) — RoPE → 4 096 токенов
- Mistral 7B (2023) — RoPE + SWA → 32K
- LLaMA 3 (2024) — RoPE + ABF → 128K
- Qwen 2.5 (2024) — RoPE + DCA → 1M
- Gemma 3 (2025) — RoPE + SWA → 128K
- DeepSeek-V3 (2025) — RoPE + YaRN → 128K
- SmolLM3 (2025) — RNoPE + ABF + YaRN → 128K
- Kimi K2 (2025) — RoPE + YaRN → 128K
Document masking: инфраструктура длинного контекста
При обучении документы разной длины пакуются в последовательности фиксированной длины. Без дополнительных мер токены документа B "видят" токены документа A из того же батча — cross-document leakage. Document masking ограничивает внимание строго своим документом.
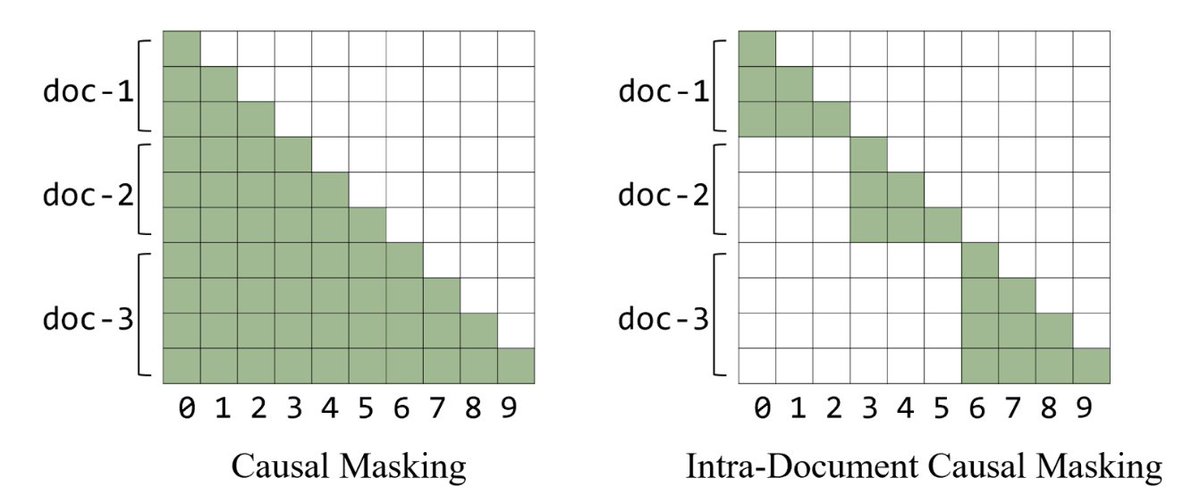
На коротких задачах document masking почти ничего не даёт. Но стоит расширить контекст до 64K+ — и без него всё разваливается. Это один из тех приёмов, которые "не нужны, пока не нужны, а потом без них никуда".
Attention для длинного контекста
- Sliding Window Attention (SWA): каждый токен видит до w позиций назад. Через L слоёв: receptive field = L × w. Gemma 3 чередует SWA и full attention через слой
- Dual Chunk Attention (DCA): внутри чанка — полное внимание, между чанками — ограниченное окно. Qwen 2.5: до 1M токенов
- Interleaving: чередование local и global attention слоёв. Local снижает O(n²), global сохраняет дальние зависимости

🎯 На собеседовании
Материалы
Оригинальный Transformer (2017) — sinusoidal positional encodings.
Оригинальная статья RoPE — как вращение в 2D кодирует позиционную информацию.
ALiBi — линейные штрафы в attention вместо позиционных кодировок.
YaRN: неоднородная интерполяция частот для расширения контекста до 128K+.
RNoPE: чередование RoPE/NoPE блоков — лучший вариант для long-context.
Qwen 2.5: Dual Chunk Attention для контекста до 1M токенов.