Mixture of Experts (MoE)
Sparse-модели: routing, load balancing, shared experts. DeepSeek-V3, Kimi K2.
Mixture of Experts — масштабирование без пропорционального роста compute
Dense-модель при инференсе гоняет каждый токен через ВСЕ параметры. Расточительно, не находишь? MoE (Mixture of Experts) заменяет FFN-слой кучей мелких экспертов (MLP) и роутером, который выбирает top-k из них для каждого токена. Итог: модель с 1T параметрами, но считает как 30B — потому что 97% экспертов в каждый момент спят. Хитро.
Архитектура: FFN → Router + Experts
Роутер — это обучаемый линейный слой + softmax, который раздаёт «оценки привлекательности» каждому эксперту. Top-k gating берёт k лучших. Масштабы впечатляют: в Kimi K2 — 384 эксперта, активны 8 (sparsity=48!). В DeepSeek-V3 — 256 экспертов, активны 8. В gpt-oss-120b гранулярность 2 — каждый эксперт примерно вдвое уже dense FFN.

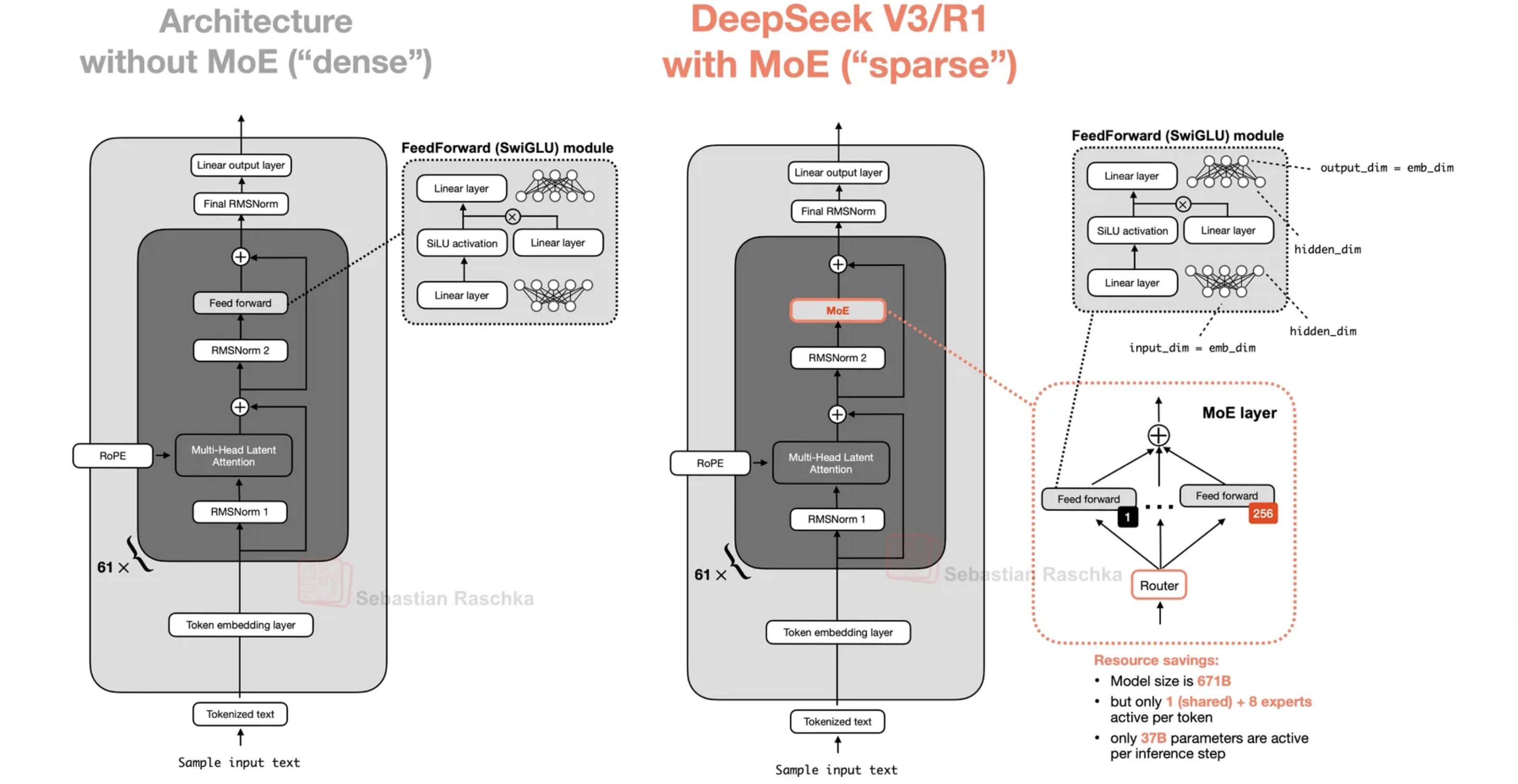
Гранулярность и shared experts
Гранулярность — это насколько мелко нашинкованы эксперты. Выше G = больше маленьких экспертов. Ant Group показали прикольную штуку: гранулярность почти не влияет на loss, но сильно влияет на efficiency leverage — сколько FLOPs ты экономишь по сравнению с dense при том же качестве.
Гранулярность G: число, пропорциональное количеству экспертов, нужных для покрытия ширины dense FFN. gpt-oss-120b: G=2, Qwen3-Next: G=8
Shared experts — это эксперты-трудоголики, которые работают всегда, для каждого токена. Они берут на себя базовые, общие паттерны, чтобы routing-эксперты могли спокойно специализироваться на интересном. Обычно хватает одного shared expert (DeepSeek-V2 поставил два — для надёжности).
import torch
import torch.nn as nn
import torch.nn.functional as F
class MoELayer(nn.Module):
"""Simplified MoE layer: router + top-k expert selection."""
def __init__(self, d_model: int, n_experts: int = 8, top_k: int = 2):
super().__init__()
self.router = nn.Linear(d_model, n_experts, bias=False)
self.experts = nn.ModuleList([
nn.Sequential(nn.Linear(d_model, d_model * 4), nn.SiLU(),
nn.Linear(d_model * 4, d_model))
for _ in range(n_experts)
])
self.top_k = top_k
self.n_experts = n_experts
def forward(self, x): # x: (batch, seq, d_model)
logits = self.router(x) # (batch, seq, n_experts)
weights, indices = logits.topk(self.top_k) # top-k экспертов
weights = F.softmax(weights, dim=-1) # нормализуем
# Прогоняем только через выбранных экспертов
out = torch.zeros_like(x)
for k in range(self.top_k):
expert_idx = indices[..., k] # какой эксперт
w = weights[..., k:k+1] # вес этого эксперта
for i in range(self.n_experts):
mask = (expert_idx == i)
if mask.any():
out[mask] += w[mask] * self.experts[i](x[mask])
return out # sparse: 75% экспертов не считали ничегоLoad balancing — ключ к эффективности MoE
Без load balancing MoE превращается в тыкву: один эксперт пашет за всех, остальные курят. GPU плачут, эффективная ёмкость модели падает. Три подхода, чтобы это починить:
- Auxiliary loss (классический): штрафуем разницу между долей токенов fi и вероятностью маршрутизации Pi для каждого эксперта
- Bias-based (DeepSeek-V3): добавляем bias к affinity scores перед softmax, обновляем bias на основе отклонения от среднего
- SMEBU (Kimi K2): нормализуем нарушения через tanh (независимо от seq len), обновляем bias с momentum — стабильнее sign(·)
Auxiliary loss: fi — доля токенов для эксперта i, Pi — средняя вероятность маршрутизации. α контролирует силу (не слишком большой, чтобы не задавить основной loss)
DeepSeek-V3: loss-free load balancing через bias. γ — скорость обновления, n̄ — среднее число токенов, ni — токены для эксперта i
SMEBU — апгрейд bias-based подхода от Kimi K2. Вместо грубого sign(·) — плавный tanh(κ · vi). Вместо прямого обновления — momentum buffer для стабильности. Нормализованное нарушение vi = (n̄ − ni)/n̄ не зависит от batch size — можно менять батч без перетюнивания гиперпараметров. Инженерная красота.
⚠️ Мониторинг MoE
Scaling: спarsity и trade-offs
Эмпирика: при фиксированных active experts, чем больше всего экспертов (выше sparsity) — тем лучше loss. Kimi K2 разогнал число экспертов до 384 (vs 256 у DeepSeek-V3), попутно срезав attention heads с 128 до 64. Цена: +0.5-1.2% validation loss. Награда: −45% inference FLOPs. Почти бесплатный x2 на инференсе — неплохая сделка.
- Higher sparsity → better performance при фиксированных FLOPs (Kimi, Ant Group)
- MoE эффективнее dense при тренировке и инференсе — при условии сбалансированного routing
- Trade-off: все эксперты должны быть загружены в память → MoE требует больше RAM/VRAM, чем dense с такими же active params
- Если инфра ограничена — dense модель проще в операционализации
🎯 На собеседовании
Материалы
DeepSeek-V3: loss-free load balancing, auxiliary loss alternatives, MoE + MLA.
Kimi K2: 384 экспертов, sparsity=48, SMEBU, MuonClip — scaling MoE до 1T параметров.
Ant Group: гранулярность, sparsity и efficiency leverage в MoE моделях.