Seq2Seq и Attention
Encoder-decoder, механизм внимания, beam search, BPE-токенизация.
Seq2Seq и Attention — от encoder-decoder к революции в NLP
Некоторые задачи NLP — это преобразование одной последовательности в другую: перевод («How are you?» → «Как дела?»), суммаризация (статья → три предложения), генерация ответа (вопрос → ответ). Входная и выходная последовательности могут быть разной длины — значит, нужна архитектура, которая умеет сжать вход и развернуть выход.
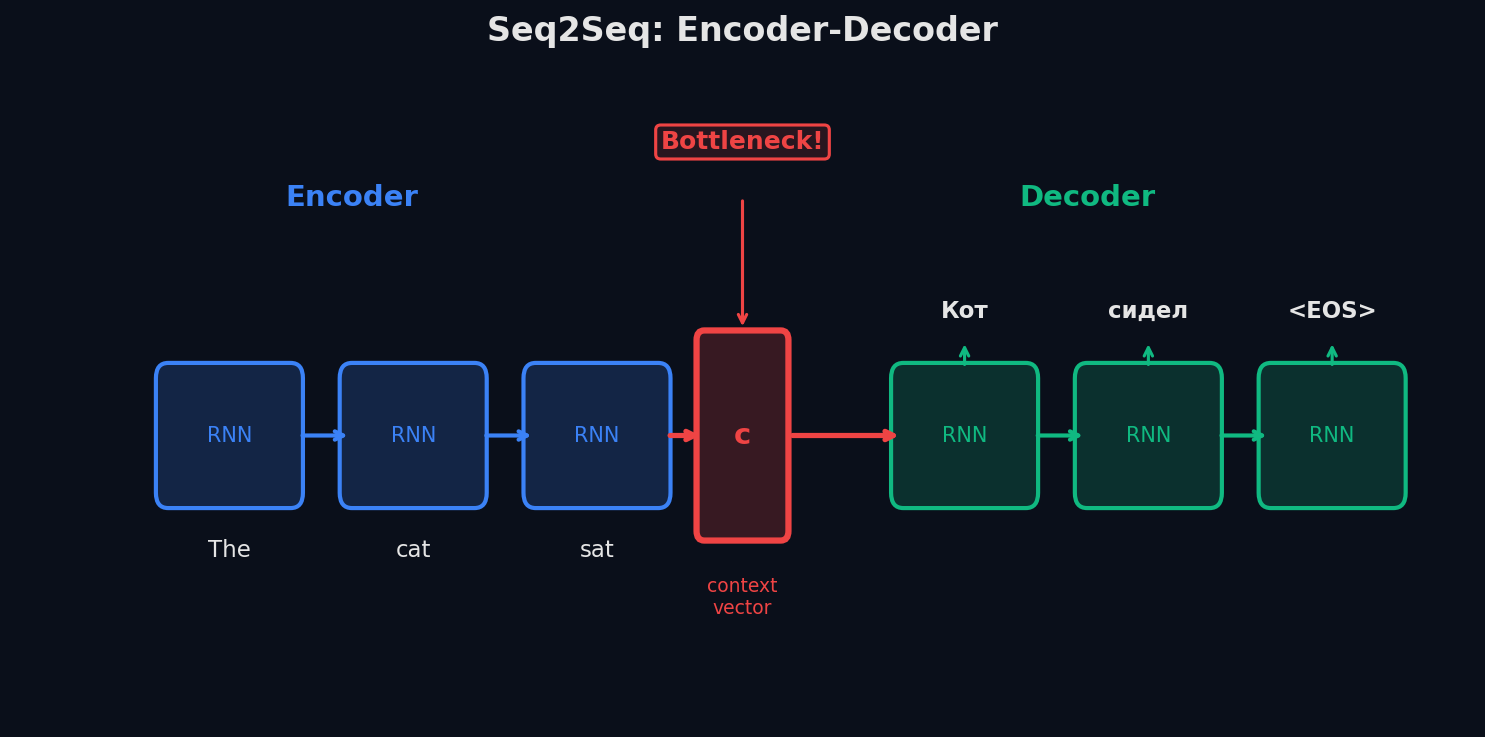
Такой архитектурой стала Seq2Seq (sequence-to-sequence) — два RNN, работающих в связке: encoder читает вход, decoder пишет выход. Модель была прорывом в 2014 году, но быстро упёрлась в ограничение — bottleneck: весь входной текст сжимается в один вектор фиксированного размера. Решением стал attention — механизм, позволяющий decoder «подглядывать» во все слова входа на каждом шаге генерации.
Именно attention лёг в основу Transformer (2017), и цепочка seq2seq → attention → self-attention → Transformer — одна из ключевых эволюционных линий NLP, которую часто спрашивают на собесах.
Большая картина: encoder сжимает, decoder разворачивает
Аналогия: переводчик-синхронист. Сначала он слушает всё предложение на английском и формирует в голове «смысл» — это encoder. Потом он произносит перевод слово за словом — это decoder. Связь между ними — тот самый «смысл в голове», один вектор фиксированного размера, который называют context vector.
Вот как это работает шаг за шагом: Шаг 1. Encoder — RNN (обычно LSTM или GRU), которая читает входную последовательность токен за токеном. На каждом шаге обновляет своё скрытое состояние h_t. После последнего токена финальное скрытое состояние h_T становится context vector — «сжатым представлением» всего входа. Шаг 2. Передача контекста. Context vector передаётся в decoder как начальное скрытое состояние. Вся информация о входном предложении — в этом одном векторе. Шаг 3. Decoder — другая RNN, которая генерирует выход токен за токеном. На каждом шаге принимает предыдущий сгенерированный токен + текущее скрытое состояние и предсказывает следующий токен через softmax по словарю. Генерация останавливается на токене [END].
Загрузка интерактивного виджета...
Проблема bottleneck: один вектор на всё предложение
Главная слабость ванильного seq2seq — information bottleneck (узкое горлышко). Весь входной текст, будь то 5 слов или 50, сжимается в один вектор фиксированного размера (обычно 256-1024). Это как пересказать «Войну и мир» одним предложением — неизбежно теряешь детали.
Для коротких фраз (5-10 слов) это работает нормально. Но на длинных предложениях (20+ слов) качество резко падает: decoder «забывает» информацию из начала входа, потому что она была «перезаписана» по мере чтения следующих слов. Эксперименты Cho et al. (2014) показали: BLEU score seq2seq резко падает при длине предложения > 20 токенов.
Именно эта проблема подтолкнула к изобретению attention: а что если decoder мог бы на каждом шаге «подглядывать» во все промежуточные состояния encoder, а не только в финальный вектор?
Attention — пусть decoder смотрит на все слова входа
Идея attention (Bahdanau et al., 2014): вместо одного context vector decoder на каждом шаге генерации получает свой собственный контекстный вектор — взвешенную сумму всех скрытых состояний encoder. Веса определяют, на какие слова входа decoder «обращает внимание» прямо сейчас.
Аналогия: представь, что ты переводишь текст с листа. Без attention — ты прочитал весь текст, закрыл его и переводишь по памяти. С attention — ты переводишь с открытым листом: для каждого слова перевода заглядываешь в нужное место оригинала. Переводишь «кот» — смотришь на «cat». Переводишь «сидел» — смотришь на «sat». Каждый шаг генерации фокусируется на своей части входа.
Механизм attention за 3 шага: 1. Alignment scores — вычисляем «совместимость» текущего состояния decoder s_t с каждым состоянием encoder h_j. Получаем число для каждой пары (s_t, h_j). 2. Attention weights — прогоняем scores через softmax, получаем вероятностное распределение: сумма весов = 1. Чем выше вес — тем важнее этот encoder state для текущего шага. 3. Context vector — взвешенная сумма всех encoder states по attention weights. Этот вектор конкатенируется с состоянием decoder и подаётся на генерацию следующего токена.

Виды attention: Bahdanau (additive) vs Luong (multiplicative)
Bahdanau attention (additive, 2014)
Bahdanau attention вычисляет alignment score через маленький MLP (одна скрытая пара слоёв): берём состояние decoder s_{t-1} и состояние encoder h_j, пропускаем через tanh и обучаемый вектор v. Название «additive» — потому что s и h складываются внутри MLP. Важная деталь: Bahdanau использует s_{t-1} (предыдущее состояние decoder), потому что attention вычисляется до обновления decoder на текущем шаге.
Alignment score: W_s и W_h — обучаемые матрицы, v — обучаемый вектор. s_{t-1} — состояние decoder, h_j — j-е состояние encoder
alpha — attention weights (softmax по всем позициям входа), c_t — context vector (взвешенная сумма encoder states)
Luong attention (multiplicative, 2015)
Luong attention — упрощённый и более быстрый вариант. Вместо MLP alignment score вычисляется через скалярное произведение (или билинейную форму). Название «multiplicative» — потому что s и h перемножаются. Три варианта scoring function: • dot: score = s_t^T · h_j — просто скалярное произведение. Самый быстрый. • general: score = s_t^T · W · h_j — билинейная форма с обучаемой матрицей W. • concat: score = v^T · tanh(W · [s_t; h_j]) — по сути аналог Bahdanau. Отличие от Bahdanau: Luong использует текущее s_t (а не s_{t-1}), то есть attention вычисляется после обновления decoder.
На практике разница между Bahdanau и Luong невелика: оба дают схожее качество. Dot-product attention оказался самым практичным — именно он лёг в основу Transformer. Ключевое наблюдение: не нужен MLP, хватает скалярного произведения для вычисления attention.
Alignment matrix — визуализация того, «куда смотрит» модель
Если собрать attention weights α_{t,j} для всех шагов decoder (t) и всех позиций encoder (j) в матрицу, получится alignment matrix — тепловая карта, где строки = выходные токены, столбцы = входные токены.
Для хорошего перевода alignment matrix часто близка к диагонали (с учётом перестановки слов между языками). Яркие ячейки показывают, какое входное слово «отвечает» за каждое выходное. Это даёт интерпретируемость: можно увидеть, что модель при генерации «кот» действительно смотрит на «cat», а при генерации «сидел» — на «sat».
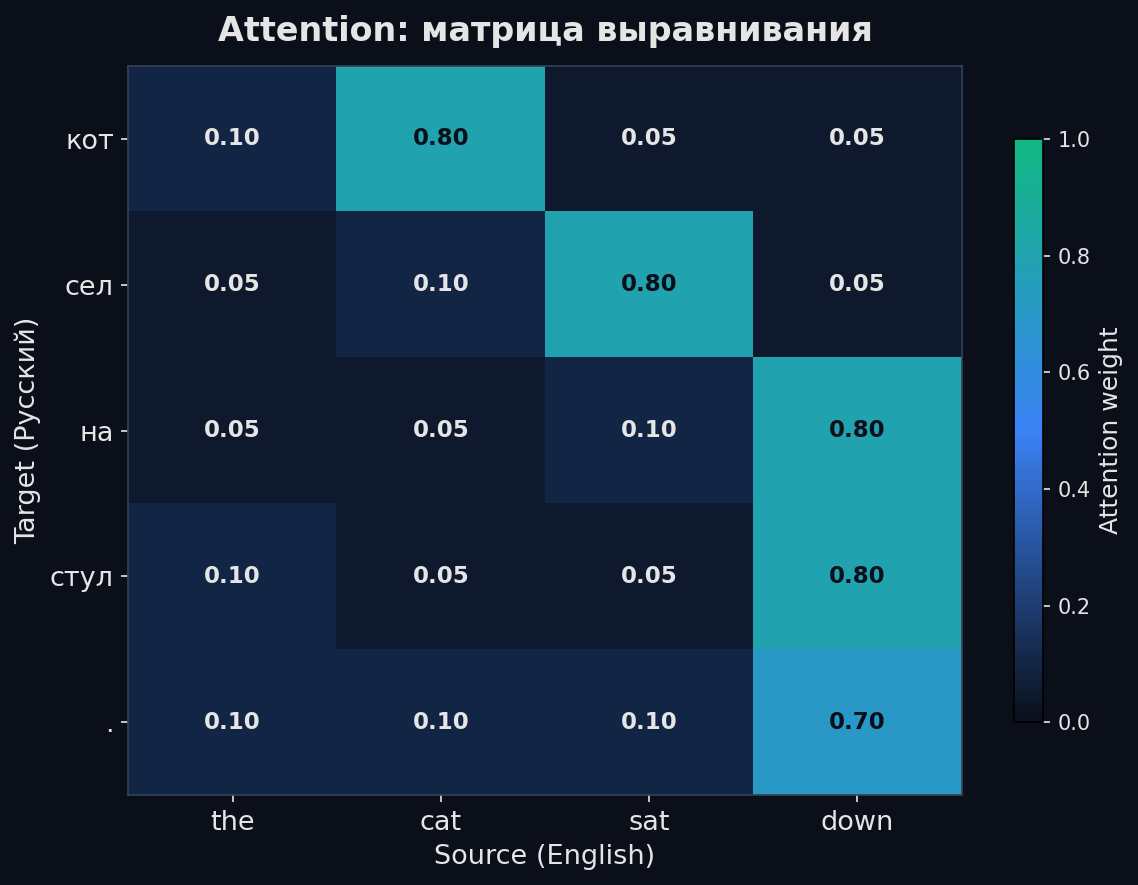
Alignment matrix стала одним из первых инструментов интерпретируемости в NLP. Позже в трансформерах анализ attention weights стал сложнее (много голов, много слоёв), но идея осталась: attention weights показывают, на что модель обращает внимание.
От attention к self-attention: дорога к Transformer
В seq2seq attention — это механизм связи между двумя разными последовательностями: decoder «смотрит» на encoder. Но в 2017 году авторы «Attention Is All You Need» задали вопрос: а что если применить attention к одной и той же последовательности? Пусть каждый токен «смотрит» на все остальные токены в том же предложении.
Это и есть self-attention (самовнимание) — основа Transformer. Три ключевых отличия от seq2seq attention: 1. Нет RNN. В seq2seq attention — надстройка над RNN. В Transformer RNN убрана полностью, attention — единственный механизм обработки. 2. Масштабирование. Dot-product attention масштабируется делением на √d_k, что стабилизирует обучение при больших размерностях. 3. Параллелизм. RNN обрабатывает токены последовательно. Self-attention — все токены одновременно, что идеально ложится на GPU.
Эволюционная цепочка: seq2seq (2014) → seq2seq + attention (Bahdanau, 2014) → self-attention без RNN (Transformer, 2017) → encoder-only (BERT, 2018) → decoder-only (GPT, 2018-2025). Понимание каждого шага этой цепочки — must have на собесе.
Teacher forcing — хитрость при обучении decoder
При обучении decoder есть выбор: что подавать на вход на каждом шаге — предыдущий предсказанный токен (который может быть ошибочным) или правильный токен из ground truth? Teacher forcing — это когда подаём правильный ответ, как учитель, который подсказывает.
Аналогия: учитель иностранного языка диктует текст. Без teacher forcing — ученик пишет слово, если ошибся — следующие слова тоже будут неправильными (ошибка накапливается). С teacher forcing — учитель после каждого слова говорит правильный вариант, и ученик продолжает от верного контекста.
Плюс: быстрая и стабильная сходимость — модель учится на правильных примерах, нет лавины ошибок. Минус: exposure bias — при обучении модель всегда видит правильные предыдущие токены, а при инференсе — свои собственные предсказания (которые могут быть ошибочными). Модель не учится «выбираться» из ошибок.
- Teacher forcing — всегда правильный токен. Быстрая сходимость, но exposure bias
- Scheduled sampling — с вероятностью p подаём правильный токен, с (1-p) — предсказанный. p уменьшается по мере обучения — плавный переход от teacher forcing к free running
- Free running — decoder всегда получает свой же выход. Нет exposure bias, но учится медленнее и менее стабильно
Beam search — как генерировать лучшие последовательности
Decoder генерирует текст токен за токеном. Greedy decoding берёт самый вероятный токен на каждом шаге — быстро, но часто субоптимально. Лучший токен сейчас не означает лучшую последовательность в итоге. Beam search — компромисс: держим B лучших гипотез (beams) параллельно. На каждом шаге расширяем каждую гипотезу всеми возможными продолжениями и оставляем top-B по суммарной log-probability.
- beam_size = 1 → greedy decoding
- beam_size = 4-10 → стандарт для машинного перевода
- Length normalization — без неё beam search предпочитает короткие последовательности (у них выше вероятность). Делят score на length^α
Практический пример: seq2seq с attention на PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
class BahdanauAttention(nn.Module):
"""Additive (Bahdanau) attention."""
def __init__(self, enc_dim: int, dec_dim: int, attn_dim: int = 128):
super().__init__()
self.W_h = nn.Linear(enc_dim, attn_dim, bias=False)
self.W_s = nn.Linear(dec_dim, attn_dim, bias=False)
self.v = nn.Linear(attn_dim, 1, bias=False)
def forward(self, s: torch.Tensor, h: torch.Tensor):
# s: [batch, dec_dim] — состояние decoder
# h: [batch, src_len, enc_dim] — все состояния encoder
scores = self.v(torch.tanh(
self.W_h(h) + self.W_s(s).unsqueeze(1)
)).squeeze(-1) # [batch, src_len]
weights = F.softmax(scores, dim=-1) # attention weights
context = (weights.unsqueeze(-1) * h).sum(dim=1) # [batch, enc_dim]
return context, weights
# Пример использования
attn = BahdanauAttention(enc_dim=256, dec_dim=256)
encoder_states = torch.randn(2, 10, 256) # batch=2, src_len=10
decoder_state = torch.randn(2, 256) # текущее состояние decoder
context, weights = attn(decoder_state, encoder_states)
print(f"context: {context.shape}") # [2, 256]
print(f"weights: {weights.shape}") # [2, 10] — вес на каждый encoder state🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Seq2Seq — это encoder-decoder архитектура для задач «последовательность → последовательность». Encoder сжимает вход в context vector, decoder разворачивает его в выход. Ключевая проблема — bottleneck: один вектор не может вместить всю информацию длинного предложения.
Attention решает bottleneck: вместо одного вектора decoder на каждом шаге получает взвешенную сумму всех encoder states. Bahdanau (additive) и Luong (multiplicative) — два основных варианта, оба работают одинаково хорошо. Alignment matrix даёт интерпретируемость.
Если запомнить одну вещь из этой ноды: attention — это механизм, позволяющий decoder динамически фокусироваться на релевантных частях входа, вместо того чтобы полагаться на один сжатый вектор. Этот принцип оказался настолько мощным, что стал фундаментом Transformer — архитектуры, на которой построены все современные LLM.
Дальше на роадмапе: Transformer берёт идею attention и делает из неё единственный механизм обработки — self-attention, убирая RNN полностью. А BERT и GPT показывают два способа использовать эту архитектуру.
Материалы
Интерактивный курс с лучшими визуализациями attention. Must-read.
Оригинальная статья по additive attention (2014). Одна из самых цитируемых в NLP.
Multiplicative attention, сравнение scoring functions (dot, general, concat).
Лекция Мэннинга: seq2seq, attention, beam search — всё в одном.
Визуальное пошаговое объяснение encoder-decoder с attention. Отличные иллюстрации.