Языковые модели
N-грамм LM, нейросетевые LM, перплексия, стратегии генерации.
Языковые модели — P(следующее слово | контекст)
Ты набираешь в телефоне «Привет, как» — клавиатура предлагает «дела». Ты пишешь в поиске «рецепт борща» — и поисковик дополняет «с пампушками». За этими подсказками стоит языковая модель (Language Model, LM) — система, которая умеет предсказывать следующее слово по контексту.
Формально: языковая модель — это распределение вероятностей P(w₁, w₂, …, wₜ) над последовательностями слов. На практике мы раскладываем его по цепному правилу: P(текст) = P(w₁) · P(w₂|w₁) · P(w₃|w₁,w₂) · … — и учим модель хорошо оценивать каждый множитель P(wₜ | контекст). Чем точнее оценки — тем «умнее» модель.
Этот принцип — фундамент всего современного NLP. GPT генерирует текст, предсказывая токен за токеном. BERT учит внутренние представления, заполняя замаскированные слова. Машинный перевод, суммаризация, чат-боты — всё это языковые модели разной архитектуры, но с одной идеей: моделируем P(next | context).
Большая картина: эволюция языковых моделей
История языковых моделей — это история борьбы с одной проблемой: как учитывать контекст. Чем больше контекста модель может «видеть» и понимать — тем лучше предсказания.
1980-2000-е: N-граммы. Считаем частоты пар, троек, четвёрок слов в корпусе. Контекст = последние n−1 слов. Просто, быстро, но контекст крошечный (2-5 слов), а редкие комбинации получают нулевую вероятность. 2003: Feed-forward нейронная LM (Bengio). Вместо таблиц частот — эмбеддинги слов + нейросеть. Контекст по-прежнему фиксированный (n слов), но похожие слова получают похожие вероятности благодаря эмбеддингам. 2010-е: RNN/LSTM языковые модели. Рекуррентная сеть читает текст последовательно и хранит «сжатое» представление всего прочитанного в скрытом состоянии. Контекст теоретически неограничен, но на практике длинные зависимости затухают. 2017+: Transformer LM. Self-attention позволяет каждому токену напрямую обращаться к любому другому. Контекст — тысячи и миллионы токенов. Параллелизм на GPU. Это GPT, LLaMA и все современные LLM.
N-gram модели: считаем вероятности по частотам
Самый простой способ оценить P(wₜ | контекст) — посчитать частоты в большом корпусе текстов. Марковское допущение (Markov assumption) упрощает задачу: вероятность следующего слова зависит не от всей истории, а только от последних n−1 слов. Биграмная модель (n=2) смотрит на одно предыдущее слово, триграмная (n=3) — на два.
Аналогия: представь, что ты угадываешь следующее слово в предложении, но тебе закрыли весь текст кроме последних двух слов. Видишь «…столица России» — и уверенно предсказываешь точку или тире. Видишь «…на» — и выбор огромный. Вот так работает триграмная модель: контекст — узкое окошко.
Цепное правило + марковское допущение: полную вероятность последовательности раскладываем в произведение условных, а каждую условную приближаем n-граммой
Оценка вероятности — подсчёт частот (Maximum Likelihood Estimation):
Биграмная MLE: вероятность слова wₜ после wₜ₋₁ = сколько раз эта пара встретилась / сколько раз встретилось wₜ₋₁
from collections import Counter
tokens = ["я", "люблю", "кота", "я", "люблю", "собаку", "я", "ем", "кота"]
bigrams = list(zip(tokens[:-1], tokens[1:]))
bigram_counts = Counter(bigrams)
unigram_counts = Counter(tokens[:-1])
# P("кота" | "люблю") = count("люблю кота") / count("люблю")
p = bigram_counts[("люблю", "кота")] / unigram_counts["люблю"]
print(f'P("кота"|"люблю") = {p:.2f}') # 0.50 (1 из 2)
# P("кота" | "ем") = count("ем кота") / count("ем")
p2 = bigram_counts[("ем", "кота")] / unigram_counts["ем"]
print(f'P("кота"|"ем") = {p2:.2f}') # 1.00 (1 из 1)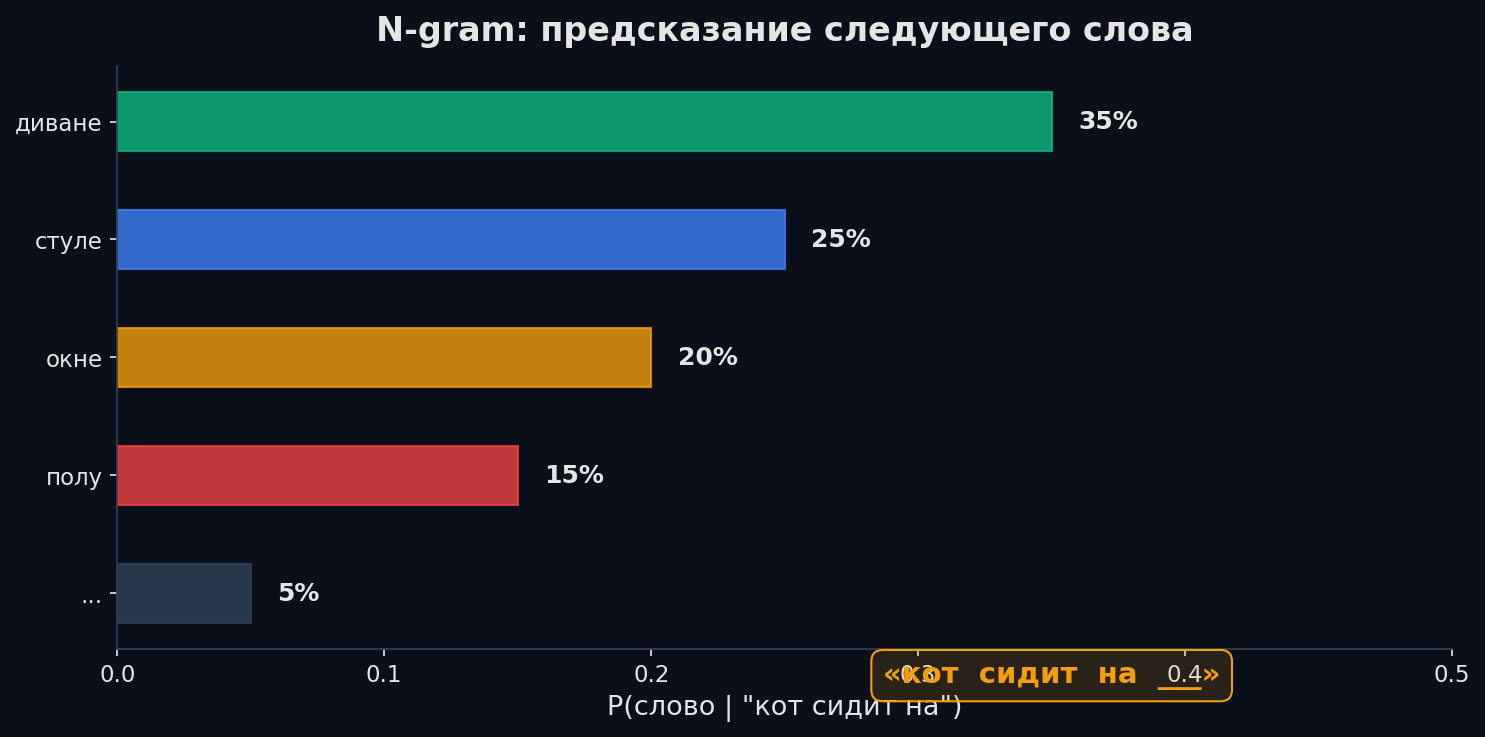
Проблема разреженности и сглаживание (smoothing)
У n-грамм есть фатальная проблема. Если триграмма «кот съел пирог» ни разу не встретилась в корпусе — count = 0, P = 0, и вся последовательность получает нулевую вероятность (потому что это произведение, а ноль убивает произведение). Модель говорит: «это предложение невозможно» — просто потому что не видела такую комбинацию в обучающих данных. Это явно неправильно.
Сглаживание (smoothing) решает проблему: мы «крадём» немного вероятностной массы у частых событий и перераспределяем на редкие. Основные подходы:
- Add-1 (Laplace) — добавляем 1 к каждому счётчику. Грубо: сильно искажает распределение при большом словаре (если |V| = 50K, добавляем 50K единиц)
- Add-k (k < 1) — мягче Laplace, но k нужно подбирать на dev-сете
- Backoff / Interpolation — если триграмма не найдена, откатываемся к биграмме: P(w|u,v) = λ₃·P_tri + λ₂·P_bi + λ₁·P_uni. Коэффициенты λ подбираются на валидации
- Kneser-Ney — state-of-the-art для n-грамм. Ключевая идея: учитываем не просто частоту слова, а разнообразие контекстов, в которых оно встречается. Слово «Франциско» редкое в целом, но почти всегда после «Сан» → для backoff оценка должна это учитывать
Perplexity — главная метрика языковых моделей
Как сравнить две языковые модели? Нужна метрика, которая оценивает, насколько хорошо модель предсказывает реальный текст. Эта метрика — перплексия (perplexity, PPL).
Интуиция: перплексия — это «средний размер выбора» на каждом шаге. Если PPL = 10, модель в среднем «колеблется» между 10 кандидатами на каждый следующий токен. Если PPL = 100 — между 100 кандидатами. Чем ниже перплексия — тем увереннее модель, тем лучше она предсказывает текст.
Аналогия: представь, что ты играешь в «Угадай следующее слово». Если каждый раз предлагаешь 5 вариантов и среди них правильный — твоя «перплексия» = 5. Если предлагаешь 500 и один из них правильный — перплексия = 500. Хороший предсказатель = маленький список вариантов.
Perplexity = 2 в степени кросс-энтропии. T — количество токенов в тестовом тексте, P(wₜ|w<ₜ) — вероятность, которую модель присвоила правильному токену. Ниже PPL = лучше
Связь с кросс-энтропией и loss-ом: PPL = 2^H, где H — кросс-энтропия (если логарифм по основанию 2). Если модель обучается с cross-entropy loss и натуральным логарифмом, то PPL = exp(loss). Так что перплексия — это просто экспонента от loss-а, интерпретируемая как «эффективный размер словаря».
import math
# Модель дала вероятности правильных токенов:
probs = [0.4, 0.7, 0.1, 0.5, 0.3] # P(wₜ | context) для 5 токенов
# Кросс-энтропия (log base 2)
H = -sum(math.log2(p) for p in probs) / len(probs)
ppl = 2 ** H
print(f"Cross-entropy H = {H:.2f} bits") # ≈ 2.01
print(f"Perplexity = {ppl:.1f}") # ≈ 4.0
# Интерпретация: модель в среднем выбирает из ~4 кандидатов
# Для сравнения: случайное угадывание из словаря 50K → PPL = 50000⚠️ Ловушки перплексии
Нейронные языковые модели: от Bengio к RNN-LM
Главная проблема n-грамм — они не понимают семантику. «Кот сидел на коврике» и «кошка лежала на подстилке» — для n-грамм это полностью разные контексты с разными счётчиками. Если модель видела первое предложение, но не видела второе — она не перенесёт знания. Нейронные LM решают это через эмбеддинги: похожие слова получают близкие вектора, и знание о «коте» автоматически переносится на «кошку».
Feed-Forward LM (Bengio, 2003)
Первая нейронная языковая модель — удивительно простая. Берём эмбеддинги последних n−1 слов, конкатенируем в один длинный вектор, прогоняем через один скрытый слой с tanh, затем линейный слой + softmax по всему словарю. На выходе — распределение P(wₜ | wₜ₋ₙ₊₁, …, wₜ₋₁).
Это выглядит как n-грамма по структуре (фиксированное окно контекста), но с двумя ключевыми преимуществами: 1. Обобщение через эмбеддинги. Синонимы автоматически получают похожие предсказания. 2. Компактность. Вместо таблицы из |V|ⁿ счётчиков — матрица эмбеддингов |V|×d + параметры сети.
Статья Bengio «A Neural Probabilistic Language Model» (2003) собрала 15 000+ цитирований и заложила фундамент: эмбеддинги + нейросеть → языковая модель. Но фиксированное окно — ограничение. Для контекста в 10 слов нужен огромный входной слой, а 100 слов — уже нереально.
RNN/LSTM языковая модель
RNN элегантно снимает ограничение фиксированного окна. Сеть читает слова одно за другим и обновляет скрытое состояние hₜ — «сжатую память» всего прочитанного. Предсказание P(wₜ₊₁) зависит от hₜ, которое теоретически кодирует весь предыдущий контекст.
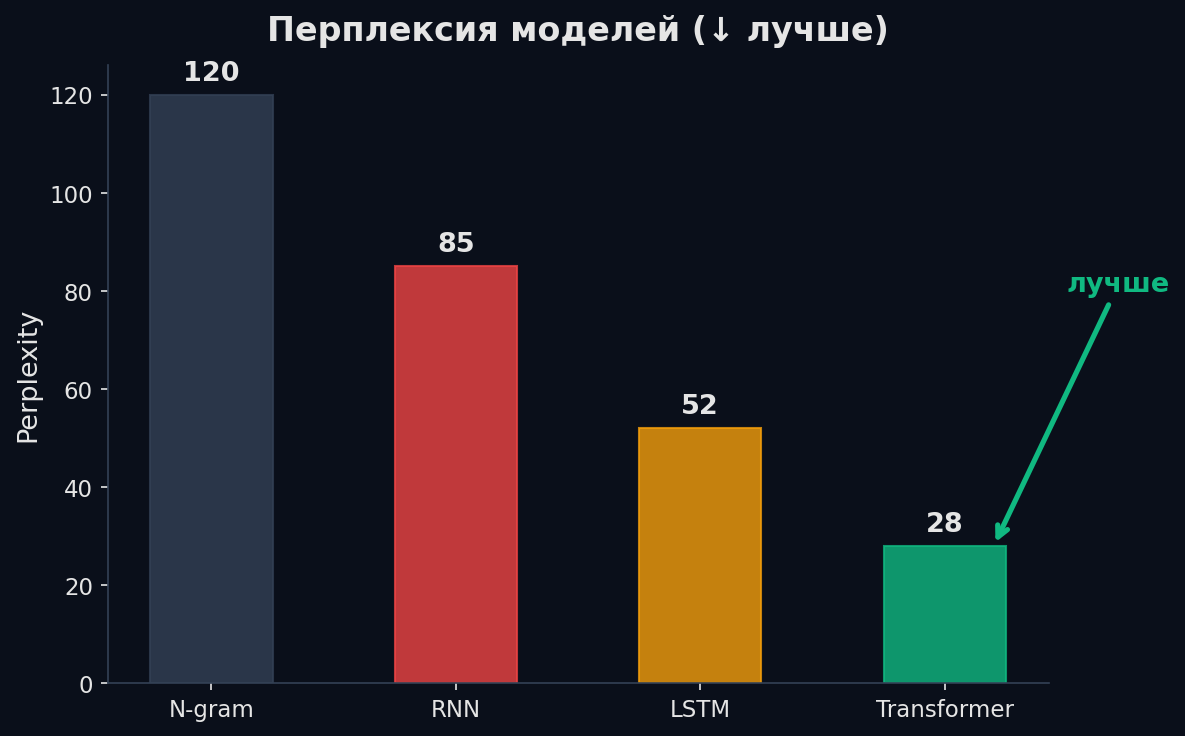
На практике: чистая RNN страдает от vanishing gradients — сигнал от далёких слов затухает. LSTM/GRU решают это частично с помощью gating-механизмов. LSTM-LM был стандартом от Mikolov (2010) до появления трансформеров. На Penn Treebank: n-грамм PPL ~150, LSTM-LM PPL ~60, Transformer-LM PPL ~20.
import torch
import torch.nn as nn
class RNNLM(nn.Module):
"""Минимальная RNN языковая модель."""
def __init__(self, vocab_size: int, embed_dim: int = 256, hidden_dim: int = 512):
super().__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
self.rnn = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.head = nn.Linear(hidden_dim, vocab_size) # проекция → словарь
def forward(self, x):
# x: [batch, seq_len] — индексы токенов
emb = self.embed(x) # [batch, seq_len, embed_dim]
h, _ = self.rnn(emb) # [batch, seq_len, hidden_dim]
logits = self.head(h) # [batch, seq_len, vocab_size]
return logits # loss = CrossEntropy(logits, targets)
# Обучение: на каждой позиции t модель предсказывает токен t+1
# targets = x[:, 1:] (сдвинутая последовательность)А потом пришёл Transformer — и всё изменилось. Self-attention дал прямой доступ к любому токену контекста без затухания, плюс полную параллельность на GPU. Подробнее — в ноде Transformer.
Генерация текста: от распределения к словам
Языковая модель на каждом шаге выдаёт распределение вероятностей по словарю — но это ещё не текст. Нужна стратегия декодирования: как выбрать конкретный следующий токен? Оказывается, это далеко не тривиальный вопрос, и выбор стратегии сильно влияет на качество текста.
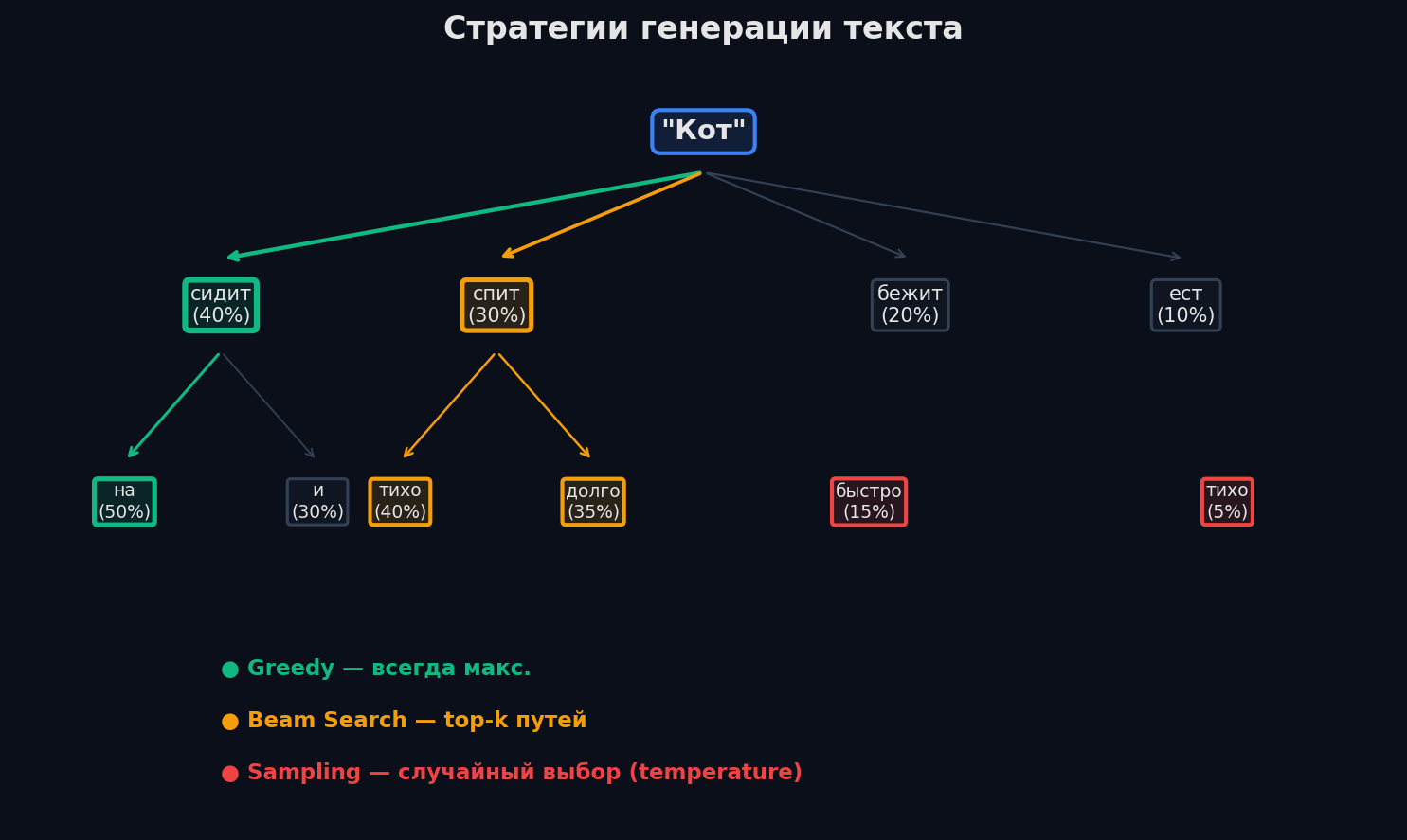
Greedy decoding и Beam Search
Greedy decoding — самый простой подход: на каждом шаге берём токен с максимальной вероятностью (argmax). Быстро, детерминированно, но скучно: текст полон повторов («The cat sat on the mat. The cat sat on the mat.»). Причина — greedy выбирает локально лучший вариант, но глобально оптимальная последовательность может начинаться с менее вероятного токена.
Beam search — компромисс. На каждом шаге держим B лучших гипотез (beams) параллельно и расширяем каждую. Из всех расширений оставляем B лучших по суммарной log-вероятности. При B=1 это greedy, при B=5-10 — стандарт для машинного перевода и суммаризации. Beam search находит более вероятные последовательности, но по-прежнему детерминированный и склонен к «безопасным» фразам.
Sampling, Temperature, Top-k и Top-p
Для генерации «живого» текста (чат-боты, креативное письмо) нужен случайный выбор (sampling). Но наивное сэмплирование из полного распределения рискованно: модель может выбрать токен с вероятностью 0.0001% — и текст уйдёт в бессмыслицу. Поэтому используют приёмы, ограничивающие пространство выбора:
Temperature (τ) — управляет «остротой» распределения. Перед softmax логиты делятся на τ: • τ = 1.0 — оригинальное распределение • τ < 1.0 — распределение «острее», модель увереннее. τ → 0 ≈ greedy • τ > 1.0 — распределение «площе», больше разнообразия, но и больше мусора
Temperature sampling: zᵢ — логиты модели, τ — температура. При τ<1 распределение сдвигается к argmax, при τ>1 — к равномерному
Top-k sampling — сэмплируем только из k наиболее вероятных токенов, остальные обнуляем. k=50 — разумный дефолт. Проблема: k фиксирован. В контексте «Столица Франции —» модель уверена на 95% в «Париж», и k=50 тащит 49 ненужных вариантов. А в контексте «Я люблю…» выбор реально широкий, и k=50 может отрезать хорошие варианты.
Top-p (nucleus) sampling решает эту проблему элегантно: сэмплируем из наименьшего набора токенов, суммарная вероятность которых ≥ p. Если модель уверена — набор маленький (2-3 токена). Если нет — большой (100+). p=0.9-0.95 стал стандартом в GPT-like моделях. На практике часто комбинируют: temperature + top-p + top-k.
import torch
import torch.nn.functional as F
def sample_next_token(logits: torch.Tensor, temperature=0.8, top_p=0.9):
"""Top-p sampling с temperature."""
logits = logits / temperature
probs = F.softmax(logits, dim=-1)
# Сортируем по убыванию вероятности
sorted_probs, sorted_idx = probs.sort(descending=True)
cum_probs = sorted_probs.cumsum(dim=-1)
# Обнуляем всё после порога p
mask = cum_probs - sorted_probs > top_p
sorted_probs[mask] = 0.0
sorted_probs /= sorted_probs.sum() # перенормировка
# Сэмплируем
token_idx = torch.multinomial(sorted_probs, 1)
return sorted_idx[token_idx]
# Пример: logits для словаря из 5 слов
logits = torch.tensor([2.0, 1.0, 0.5, -1.0, -2.0])
token = sample_next_token(logits, temperature=0.7, top_p=0.9)
print(f"Выбранный токен: {token.item()}")Как оценивать языковые модели
Оценка LM — это не только perplexity. В зависимости от задачи используют разные подходы:
Intrinsic-метрики оценивают модель «саму по себе», без привязки к задаче: • Perplexity — основная метрика (разобрали выше). Показывает, насколько модель «удивлена» текстом. Быстро считается, хорошо коррелирует с качеством для одного типа моделей. • Bits-per-character (BPC) — кросс-энтропия на символ. Удобна для сравнения моделей с разной токенизацией.
Extrinsic-метрики (downstream evaluation) оценивают, насколько LM полезна для конкретной задачи: • Перевод → BLEU, COMET • Суммаризация → ROUGE • Вопрос-ответ → Exact Match, F1 • Генерация → MAUVE, AlpacaEval Современные LLM оценивают на бенчмарках: MMLU (знания), HumanEval (код), GSM8K (математика), MT-Bench (диалог).
Human evaluation — золотой стандарт, но дорогой. Люди оценивают fluency (беглость), coherence (связность), factual accuracy (фактическую точность). Для чат-ботов — Chatbot Arena (ELO-рейтинг через попарное сравнение). Перплексия и человеческие оценки не всегда коррелируют: модель с PPL=15 может генерировать скучные повторы, а модель с PPL=25 — живой и полезный текст.
Собираем всё вместе
Языковая модель — это P(next word | context). Вся эволюция LM — это расширение того, сколько контекста модель может эффективно использовать: 2 слова (биграмма) → n слов (n-грамма) → «всё прочитанное» (RNN) → весь вход параллельно (Transformer). Параллельно улучшалось обобщение: от таблиц частот к эмбеддингам и нейросетям.
Если запомнить одну вещь: LM = предсказание следующего токена. Perplexity = насколько модель удивлена текстом (ниже = лучше). Генерация = сэмплирование из распределения модели с ограничениями (temperature, top-p).
Дальше: Transformer — архитектура, которая сделала LM по-настоящему мощными. GPT — decoder-only LM, масштабированная до сотен миллиардов параметров. BERT — masked LM для задач понимания.
🎯 На собеседовании
Junior
Middle
Senior
Материалы
Лучшее интерактивное объяснение n-грамм, нейронных LM и перплексии с визуализациями.
Классическая глава: n-граммы, smoothing, perplexity — подробно и с примерами.
Лекция Мэннинга: от n-грамм к RNN-LM. Хорошо объясняет мотивацию перехода.
Практическое руководство по стратегиям генерации (greedy, beam, sampling, top-k/top-p) с кодом.
Оригинальная статья: первая нейронная языковая модель. 15K+ цитирований.