Представление текста
Bag of Words, TF-IDF, n-граммы — как превратить текст в числа.
Представление текста — от слов к векторам
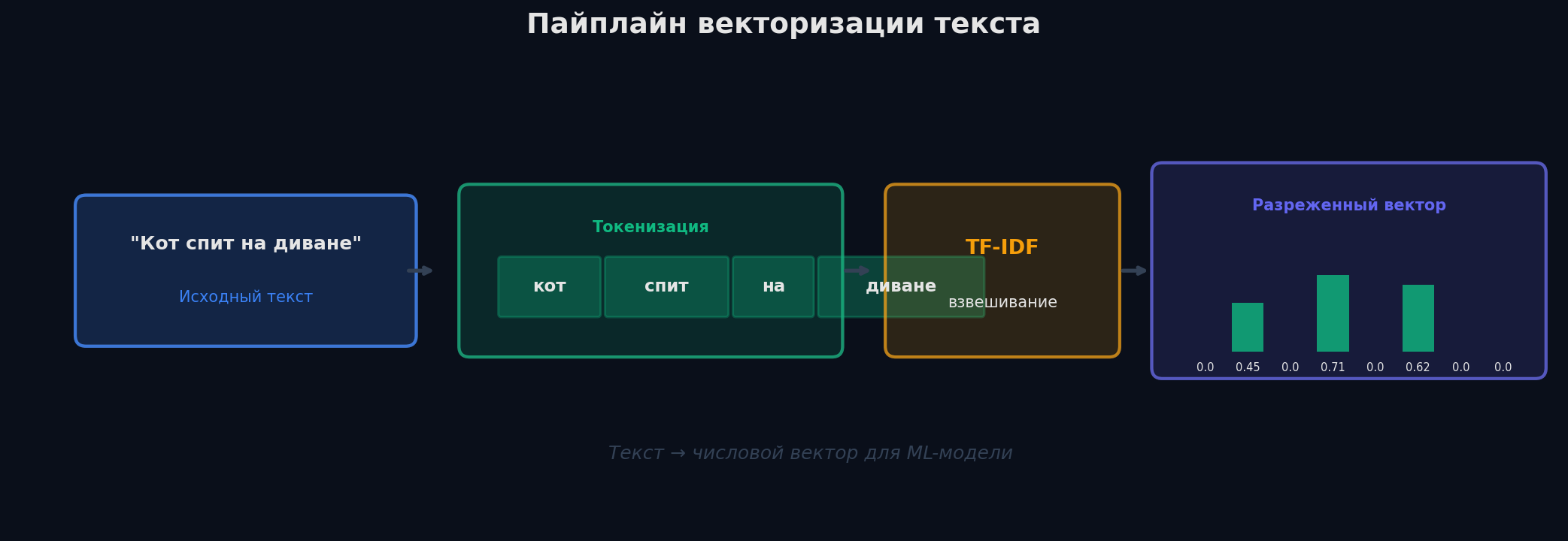
Модели ML работают с числами, а не со строками. Нужно превратить текст в вектор фиксированной длины. Классические методы — One-hot, Bag of Words, TF-IDF. Они простые, интерпретируемые и до сих пор работают как сильные бейзлайны. Но у всех одна проблема — они не учитывают порядок слов и семантику.
One-hot encoding
Каждое слово — вектор из нулей с единицей на своей позиции. Словарь из 100 000 слов → вектор длины 100 000 на каждое слово. Безумно расточительно. «Кот» и «кошка» ортогональны — между ними нулевое сходство. Для ML почти бесполезно, но идею стоит понимать — на ней строятся следующие методы.
Bag of Words (мешок слов)
Считаем, сколько раз каждое слово встретилось в документе. Порядок слов теряется — отсюда «мешок». Фраза «собака укусила человека» и «человек укусил собаку» — одинаковые векторы. Зато просто и работает для задач типа классификации тематики.
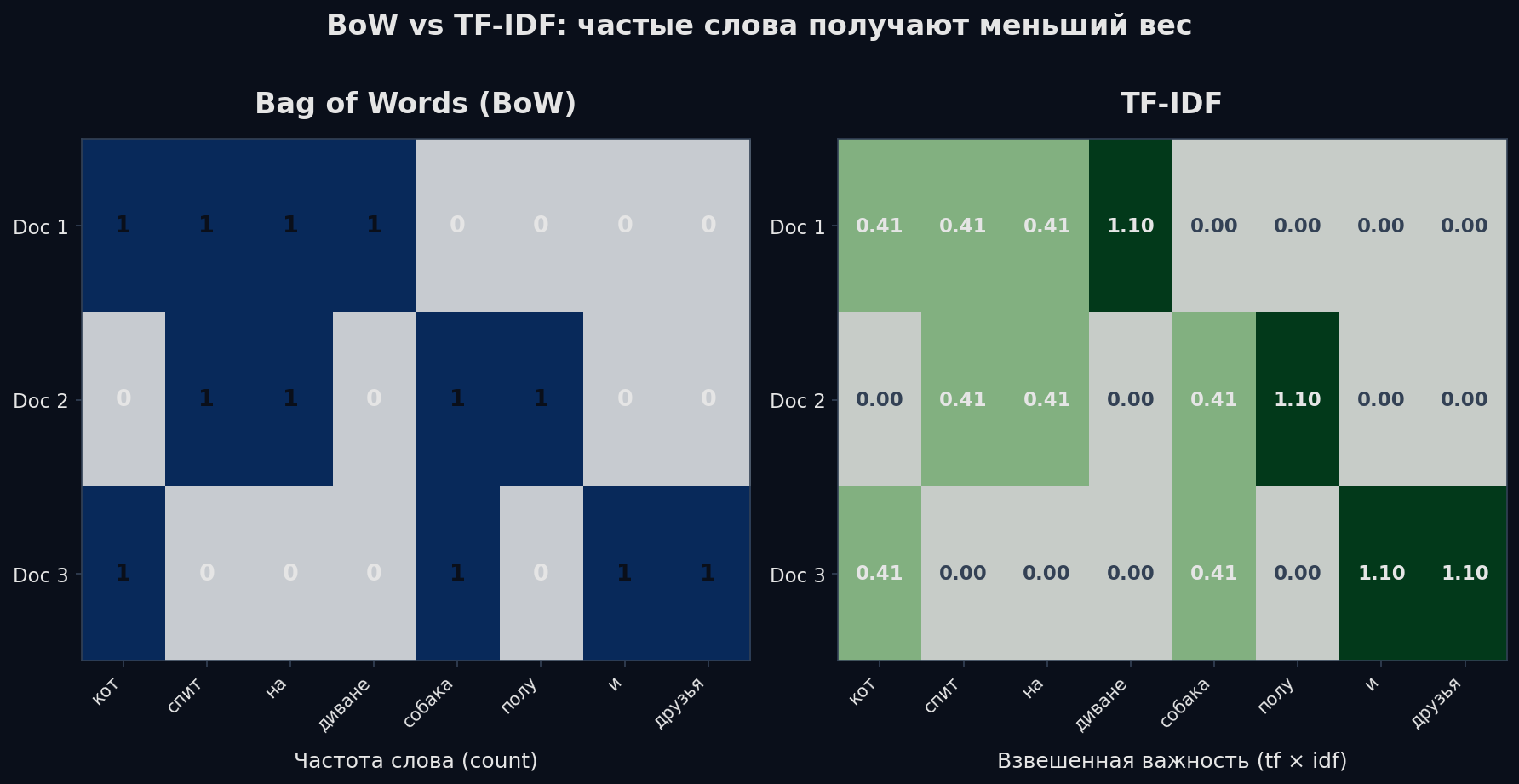
TF-IDF — умный Bag of Words
Слово «нейросеть» в статье про ML — информативно. Слово «является» — нет, оно везде. TF-IDF решает эту проблему: умножает частоту слова в документе (TF) на «редкость» слова в корпусе (IDF). Частые-везде слова получают низкий вес, уникальные для документа — высокий.
TF — как часто слово t встречается в документе d. IDF — логарифм отношения общего числа документов к числу документов, содержащих слово t
На собесе
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = ["кот спит на диване", "собака лежит на ковре"]
vec = TfidfVectorizer()
X = vec.fit_transform(corpus) # разреженная матрица (2, 7)
print(vec.get_feature_names_out())N-граммы — контекст без эмбеддингов
Bag of Words теряет порядок. Частичное решение — n-граммы: вместо отдельных слов считаем пары (биграммы), тройки (триграммы). «Нью Йорк» как биграмма осмыслена, отдельно «Нью» и «Йорк» — нет. Минус: размер словаря растёт комбинаторно. На практике обычно uni + bigrams хватает.
Проблема разреженности
Словарь — 50 000 слов. Документ содержит 30. Значит, 99.94% вектора — нули. Это разреженный вектор. Для хранения используют sparse-матрицы (scipy.sparse), иначе память закончится. Для метрик — косинусное сходство работает лучше евклидового расстояния на таких данных.
- One-hot → только как промежуточное представление, для ML бесполезен
- BoW → быстрый бейзлайн для коротких текстов и простых задач
- TF-IDF → стандартный бейзлайн для классификации, поиска, кластеризации
- TF-IDF + LogReg → на удивление сильный бейзлайн, часто бьёт сложные модели на малых данных
🎯 Суть для собеса