Введение в NLP
Задачи NLP, токенизация, предобработка текста, стемминг и лемматизация.
NLP — научить компьютер понимать текст
Компьютер не понимает текст. Для него «кот сидит на коврике» — такая же бессмысленная строка байтов, как «fdjksla qwerty xyz». Задача Natural Language Processing (NLP) — построить мост между человеческим языком и числами, с которыми умеют работать алгоритмы.
NLP — это не только ChatGPT. Каждый раз, когда ты гуглишь запрос, получаешь автоперевод, видишь подсказку при наборе текста или фильтруешь спам — за кулисами работает NLP-система. Классификация отзывов, извлечение имён и дат из документов, автоматическое резюмирование статей, ответы на вопросы — всё это задачи NLP.
В этой ноде мы пройдём весь путь от сырого текста до работающей модели: как текст чистят, как превращают в числа, какие задачи решают и как подходы к NLP эволюционировали от ручных правил до LLM.
Большая картина: от текста до предсказания
Любая NLP-система (от простого спам-фильтра до GPT) следует одному и тому же пайплайну из 4 шагов:
Шаг 1. Preprocessing (предобработка). Сырой текст — грязный. Разный регистр, HTML-теги, опечатки, эмодзи. Прежде чем что-то делать — текст нужно почистить и разбить на единицы (токены). Шаг 2. Representation (представление). Компьютер не умеет работать со строками — ему нужны числа. Токены превращаются в числовые вектора: через подсчёт частот (Bag of Words, TF-IDF) или через обученные эмбеддинги (Word2Vec, BERT). Шаг 3. Model (модель). Числовые представления подаются в модель — от логистической регрессии до трансформера. Модель учится находить паттерны: «если в тексте много слов "ужасный", "разочарован" — это негативный отзыв». Шаг 4. Output (результат). Модель выдаёт ответ: класс («спам / не спам»), извлечённые сущности, перевод, сгенерированный текст.

Важная идея: качество предобработки и представления часто важнее выбора модели. Можно взять простую логрегрессию на хорошем TF-IDF и обойти нейросеть на плохих фичах. Это особенно верно для «классического» NLP до эпохи трансформеров.
Preprocessing: от грязного текста к чистым токенам
Токенизация — разбиваем текст на части
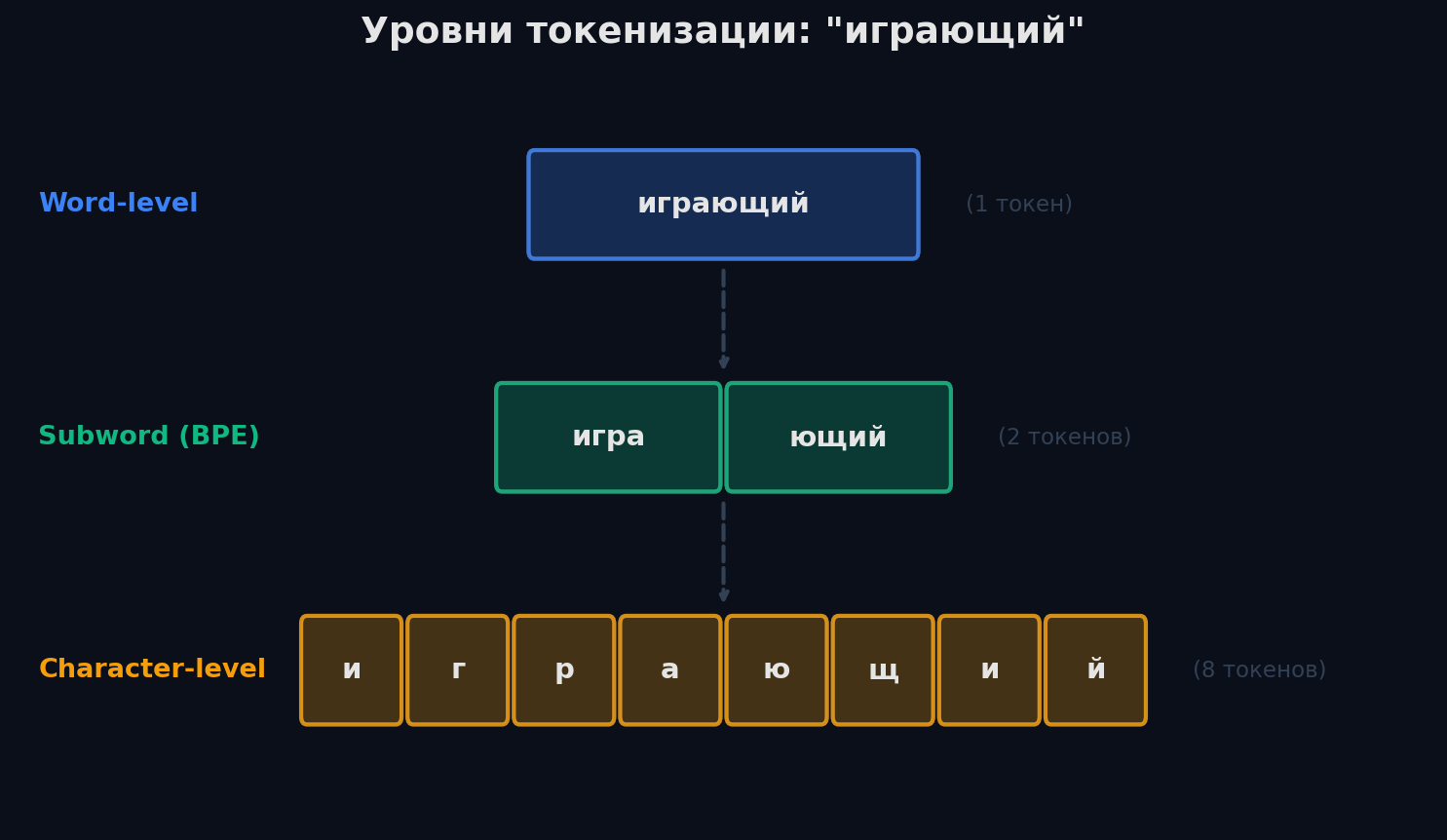
Токенизация — первый и самый важный шаг. Кажется простым: разбей по пробелам. Но попробуй разбить «Санкт-Петербург» или «don't» или «по-моему» — и простые правила ломаются. Три основных подхода:
- Word-level — разбиение по пробелам и пунктуации. Просто, но словарь огромный (100K+ слов), а новые/редкие слова → OOV (out-of-vocabulary)
- Subword (BPE, WordPiece, SentencePiece) — золотая середина. Частые слова остаются целиком, редкие разбиваются на части: «играющий» → «игра» + «##ющий». Стандарт для трансформеров (BERT, GPT)
- Character-level — каждый символ отдельно. Словарь крошечный (~100 символов), нет OOV, но последовательности очень длинные и модели сложнее ловить семантику
Нормализация текста
После токенизации текст нужно привести к единообразному виду. Но не существует универсального рецепта — каждый шаг зависит от задачи:
- Lowercasing — «Москва» → «москва». Но осторожно: «US» (страна) ≠ «us» (нас). Для sentiment analysis обычно нужен, для NER — опасен
- Удаление пунктуации — для bag-of-words полезно, для языковых моделей — часто вредно (восклицательный знак несёт эмоцию)
- Стоп-слова — «и», «в», «на», «the», «is» удаляем для TF-IDF (они не несут смысла), но оставляем для BERT/GPT (им нужен полный контекст)
- Нормализация Unicode — «ё» vs «е», разные типы кавычек, символы-двойники из разных алфавитов
Лемматизация vs стемминг
Обе техники приводят слова к «базовой» форме, чтобы модель понимала, что «бегу», «бежал», «бегущий» — это одно и то же. Но работают по-разному:
Стемминг — грубая обрезка суффиксов по правилам. Быстрый, не требует словаря. Результат — не настоящее слово: «бегущий» → «бегущ», «бежать» → «бежа». Алгоритмы: Porter, Snowball. Лемматизация — приведение к словарной форме с учётом части речи. Результат — настоящее слово: «бегущий» → «бежать», «лучше» → «хороший». Точнее, но требует морфологического словаря и медленнее.
Когда что использовать? Для поиска и TF-IDF часто хватает стемминга — нам не важна точная форма, важно объединить похожие слова. Для задач, где важен смысл (QA, NER, генерация) — лемматизация. Для трансформеров ни то, ни другое обычно не нужно — BPE-токенизация решает проблему сама.
# Стемминг: быстрый, но грубый
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer("russian")
words = ["бегущий", "бежать", "бегу", "побежали"]
print([stemmer.stem(w) for w in words])
# ['бегущ', 'бежа', 'бег', 'побежа'] ← не настоящие слова!
# Лемматизация: точная, но медленная
import pymorphy2
morph = pymorphy2.MorphAnalyzer()
words = ["бегущий", "бежать", "бегу", "побежали"]
print([morph.parse(w)[0].normal_form for w in words])
# ['бежать', 'бежать', 'бежать', 'побежать'] ← настоящие словаBag of Words и TF-IDF — простые представления текста
Итак, текст почищен и разбит на токены. Но модели нужны числа. Самый простой способ превратить текст в вектор — Bag of Words (BoW): считаем, сколько раз каждое слово встретилось в документе. «Кот сидит, кот спит» → {кот: 2, сидит: 1, спит: 1}.
Проблема BoW: слово «и» встречается в каждом документе 50 раз — это не делает его информативным. TF-IDF решает это: умножает частоту слова в документе (TF) на «редкость» слова в корпусе (IDF). Слова, которые часты в конкретном документе, но редки в целом — получают высокий вес. «Нейросеть» в статье про ML → высокий TF-IDF. «И» в любой статье → низкий TF-IDF.
f_{t,d} — число вхождений слова t в документ d, N — общее число документов, знаменатель IDF — сколько документов содержат слово t
Плюсы BoW/TF-IDF: просто, быстро, интерпретируемо, работает с логрегрессией из коробки. Удивительно хорошо для классификации текстов (спам, тональность, тематика). Минусы: теряется порядок слов («собака укусила человека» = «человек укусил собаку»), нет семантики (синонимы «авто» и «машина» — разные слова), огромная размерность (словарь = 50K-200K измерений).
Основные задачи NLP
NLP покрывает десятки задач, но большинство сводятся к нескольким фундаментальным типам:
- Text Classification — присвоить тексту метку. Спам/не спам, тональность (позитив/негатив/нейтрально), тематика. Самая распространённая задача на практике
- Named Entity Recognition (NER) — найти и классифицировать именованные сущности: имена людей, названия компаний, даты, адреса. Критично для поиска, извлечения данных из документов
- Question Answering (QA) — ответить на вопрос по тексту. Extractive QA выделяет span из текста, generative QA генерирует ответ. Основа RAG-систем
- Machine Translation — перевод текста между языками. Задача, породившая seq2seq и attention
- Summarization — сжатие текста с сохранением смысла. Extractive (выбор ключевых предложений) vs abstractive (генерация нового текста)
- Text Generation — генерация связного текста по промпту. ChatGPT, автодополнение, написание кода
Эволюция подходов: от правил до LLM
NLP прошёл через несколько эпох, каждая из которых радикально меняла подходы:
1950-2000: Rule-based. Ручные правила и словари. «Если в предложении есть "не" + прилагательное → негатив». Работает для узких задач, но не масштабируется — языки слишком сложны для ручного описания. 2000-2013: Классическое ML. BoW/TF-IDF + логрегрессия/SVM/Naive Bayes. Модель учится сама, а не по правилам. Прорыв: модель обобщает на новые тексты. Но представление текста фиксированное и неглубокое. 2013-2017: Эмбеддинги + Deep Learning. Word2Vec (2013) показал, что слова можно представить как плотные вектора, сохраняющие семантику. RNN/LSTM научились работать с последовательностями. Но проблемы: затухание градиентов на длинных текстах, невозможность параллелизма. 2017-2020: Трансформеры. «Attention Is All You Need» (2017) — параллельная обработка всех токенов через self-attention. BERT (2018) — предобучение на огромных корпусах, fine-tuning на задачу. Один BERT бьёт все предыдущие модели на большинстве NLP-задач. 2020-сейчас: LLM. GPT-3 показал, что огромная decoder-only модель может решать задачи «из промпта» без fine-tuning. Scaling laws: больше данных + больше параметров = лучше качество. ChatGPT, Claude, LLaMA — NLP стал доступен каждому.
Ключевой инсайт
Практический пример: классификация тональности с TF-IDF + LogReg
Соберём полный пайплайн: от сырых отзывов до работающей модели. Задача — определить тональность отзыва (позитивный/негативный). Удивительно, но TF-IDF + логистическая регрессия до сих пор даёт ~85-90% на многих задачах классификации — и это 3 строки кода.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# Данные: отзывы и метки (1 = позитив, 0 = негатив)
texts = [
"Отличный фильм, смотрел с удовольствием!",
"Потрясающая игра актёров, рекомендую",
"Фильм скучный, уснул на середине",
"Ужасный сюжет, потерял два часа жизни",
"Шедевр! Лучший фильм года",
"Полная ерунда, не тратьте время",
"Невероятно красивая картинка и музыка",
"Разочарован, ожидал большего",
]
labels = [1, 1, 0, 0, 1, 0, 1, 0]
# Шаг 1-2: Preprocessing + Representation (TF-IDF делает оба)
vectorizer = TfidfVectorizer(max_features=1000)
X = vectorizer.fit_transform(texts)
print(f"Размер матрицы: {X.shape}") # (8, N) — N уникальных слов
# Шаг 3: Model
model = LogisticRegression()
model.fit(X, labels)
# Шаг 4: Предсказание на новом тексте
new_texts = ["Замечательный фильм!", "Скука смертная"]
X_new = vectorizer.transform(new_texts)
predictions = model.predict(X_new)
print(dict(zip(new_texts, predictions)))
# {'Замечательный фильм!': 1, 'Скука смертная': 0}Этот код — рабочий и копируемый. Конечно, на 8 примерах модель не обобщит, но на реальном датасете (IMDB, SST, отзывы Яндекс.Маркета с 10K+ текстов) этот же подход даёт конкурентное качество. Добавь ngram_range=(1,2) в TfidfVectorizer — и модель будет учитывать биграммы («не понравился» как одна фича), что заметно улучшит результат.
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
NLP — это превращение текста в числа и обратно. Пайплайн: preprocessing (токенизация, нормализация, лемматизация) → representation (BoW, TF-IDF, эмбеддинги) → model (от логрегрессии до трансформера) → output. Качество предобработки и представления часто важнее выбора модели.
Если запомнить одну вещь: NLP прошёл путь от ручных правил до моделей, которые учатся всему сами — но базовые концепции (токенизация, TF-IDF, типы задач) не устарели и спрашиваются на каждом ML-собеседовании.
Дальше на роадмапе: Word Embeddings — как слова превращаются в вектора, сохраняющие семантику. RNN и LSTM — как нейросети научились работать с последовательностями. А Transformer — архитектура, которая изменила всё.
Материалы
Лучший бесплатный курс по NLP с интерактивными объяснениями. Начни с первых глав.
Первая лекция Stanford NLP от Мэннинга. Основы и мотивация.
Практический туториал: TF-IDF + классификация текстов на sklearn. Можно пройти за 30 минут.
Классический учебник по NLP, бесплатно онлайн. Главы 2 (Regular Expressions, Tokenization) и 4 (Naive Bayes, Sentiment).