Математика и статистика
Линейная алгебра, матстат, теория вероятностей — фундамент для понимания алгоритмов.
Математика и статистика для ML — от вероятности до A/B-тестов
ML-модель — это способ принимать решения в условиях неопределённости. Пользователь купит подписку? Новая кнопка повысила конверсию? Два кластера в данных — реальный паттерн или случайность? На все эти вопросы отвечает статистика.
Математика для ML — это не абстрактные теоремы. Это конкретный инструментарий: вероятность говорит «насколько мы уверены», распределения описывают поведение данных, оценка параметров позволяет обучать модели, а проверка гипотез отвечает на вопрос «это реальный эффект или шум?». Без этого фундамента ты будешь нажимать кнопки в sklearn, не понимая, что происходит внутри.
Большая картина: от вероятности к решениям
Шаг 1. Вероятность. Формализуем неопределённость. Какова вероятность, что клиент уйдёт? Условная вероятность и теорема Байеса — инструменты для обновления знаний при поступлении данных. Шаг 2. Распределения. Данные не хаотичны — они подчиняются закономерностям. Рост людей — нормальное, число кликов — Пуассон, доля конверсий — биномиальное. Шаг 3. Оценка параметров. У распределения есть параметры (среднее, дисперсия). MLE и MAP — способы оценить их по данным. Это ровно то, что делает обучение модели. Шаг 4. Проверка гипотез. Новая фича увеличила метрику на 0.3%. Это реальное улучшение или шум? A/B-тест, p-value и power analysis дают формальный ответ.
Вероятность: условная, Байес и обновление знаний
Вероятность — число от 0 до 1, отражающее степень уверенности в событии. Условная вероятность P(A|B) — вероятность A при условии, что B произошло. Вероятность пробки — 30%, но если час пик — уже 70%. Условие меняет оценку.
Условная вероятность: P(A|B) — вероятность A при условии B
Теорема Байеса — обновляем знания данными
Теорема Байеса переворачивает условную вероятность: зная P(данные|гипотеза), получаем P(гипотеза|данные). Это формула обучения: есть начальные знания (prior), пришли данные — обновляешь убеждения (posterior).
P(H) — prior (начальная уверенность), P(D|H) — likelihood (правдоподобие данных), P(H|D) — posterior (обновлённая уверенность), P(D) — evidence
Пример: тест на редкую болезнь
Болезнь встречается у 1 из 1000 человек. Тест верный в 99% случаев. Ты получил положительный результат. Какова вероятность, что ты болен?
Интуиция кричит «99%!». Считаем по Байесу: • Prior: P(болен) = 0.001 • Likelihood: P(+тест | болен) = 0.99 • P(+тест) = 0.99 × 0.001 + 0.01 × 0.999 = 0.01098 • Posterior: P(болен | +тест) = 0.99 × 0.001 / 0.01098 ≈ 0.09 (9%) Только 9%! Из 1000 человек тест найдёт 1 реально больного и ~10 ложноположительных. Prior имеет огромное значение — нельзя игнорировать базовую частоту.
# Теорема Байеса: тест на болезнь
prior = 0.001 # P(болен)
sensitivity = 0.99 # P(+тест | болен)
specificity = 0.99 # P(-тест | здоров)
p_positive = sensitivity * prior + (1 - specificity) * (1 - prior)
posterior = sensitivity * prior / p_positive
print(f"P(болен | +тест) = {posterior:.3f}") # 0.090Prior и Posterior в ML
Распределения: нормальное, биномиальное, Пуассон
Распределение описывает, какие значения случайная величина принимает и с какой вероятностью. Выбор правильного распределения — половина статистического анализа.

Нормальное распределение (Гауссиана)
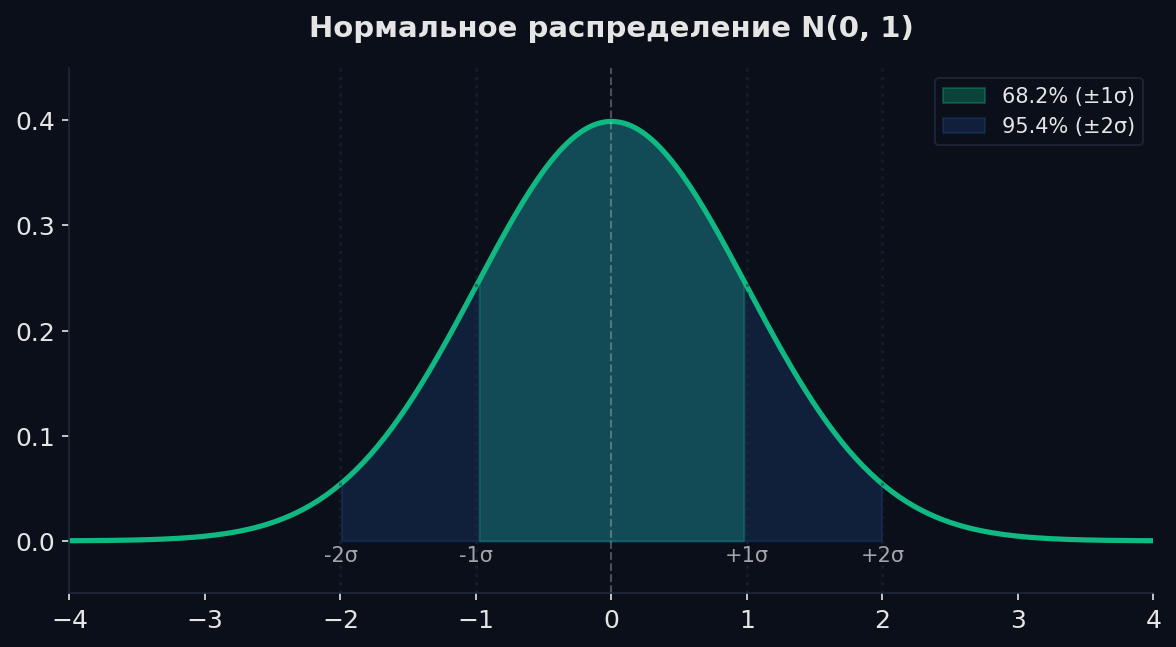
Рост людей, ошибки измерений, шум в данных — всё стремится к «колоколу». Параметры: μ (среднее — центр) и σ (стандартное отклонение — ширина). Используй для непрерывных данных вокруг среднего: рост, вес, ошибки модели.
Биномиальное распределение
Подбрасываешь монетку 100 раз — сколько орлов? Показываешь 1000 пользователям кнопку — сколько кликнет? Это биномиальное: n независимых экспериментов с вероятностью успеха p. A/B-тесты на конверсию — ровно этот случай.
n — число попыток, p — вероятность успеха, k — число успехов
Распределение Пуассона
Сколько запросов на сервер за минуту? Сколько багов за спринт? Число событий за фиксированный интервал при независимых событиях — Пуассон. Параметр: λ (среднее число событий). Для: ошибок, посещений, звонков, заявок.
λ — среднее число событий за интервал, k — наблюдаемое число
Центральная предельная теорема (ЦПТ)
ЦПТ — одна из самых мощных теорем в статистике. Суть: среднее N случайных величин с ЛЮБЫМ распределением стремится к нормальному при росте N. Не важно, как распределены исходные данные — их среднее будет «колоколом».
Почему это важно? ЦПТ — фундамент A/B-тестов и доверительных интервалов. Мы можем не знать распределение кликов каждого пользователя, но среднее по выборке будет нормальным при N > 30. Именно поэтому формулы для CI используют нормальное распределение.
import numpy as np
# ЦПТ в действии: среднее ЛЮБОГО распределения → нормальное
rng = np.random.default_rng(42)
# Экспоненциальное — совсем не "колокол"!
sample_means = [rng.exponential(2.0, size=50).mean() for _ in range(10000)]
# Но распределение средних → нормальное!
print(f"Skew исходного: ~2.0, Skew средних: {np.mean(sample_means):.2f} ± {np.std(sample_means):.3f}")Оценка параметров: MLE, MAP и доверительные интервалы
Данные подчиняются распределению с неизвестными параметрами. Задача: оценить параметры по выборке. Это фундамент обучения любой модели.
MLE — Maximum Likelihood Estimation
Выбрать параметры θ, при которых наблюдаемые данные наиболее вероятны:
MLE максимизирует log-likelihood — сумму логарифмов вероятностей каждого наблюдения
Пример: 100 бросков монетки, 60 орлов → MLE-оценка: θ = 0.6. В ML: обучение логистической регрессии через минимизацию log-loss — это MLE. Loss = −log-likelihood.
MAP — Maximum A Posteriori
MLE использует только данные. MAP добавляет prior — априорное знание о параметрах:
MAP = log-likelihood + log-prior. Первое — данные, второе — наши знания о θ
Если prior — гауссиан с центром в нуле, log P(θ) = −λ·||θ||². Это L2-регуляризация! Prior Лапласа → L1-регуляризация. Вот главная связь: регуляризация = байесовский prior на параметры.
Доверительный интервал
Точечная оценка — одно число, но насколько ей доверять? Доверительный интервал (CI) — диапазон, в который истинный параметр попадает с заданной вероятностью. 95%-CI для среднего: x̄ ± 1.96·σ/√N.
«95%» означает: при 100 повторениях эксперимента в ~95 случаях параметр окажется внутри интервала. Параметр фиксирован, интервал — случаен. Удвоение выборки N сужает CI в √2 раз: хочешь в 2 раза точнее — нужно в 4 раза больше данных.
A/B-тесты: проверяем гипотезы на практике
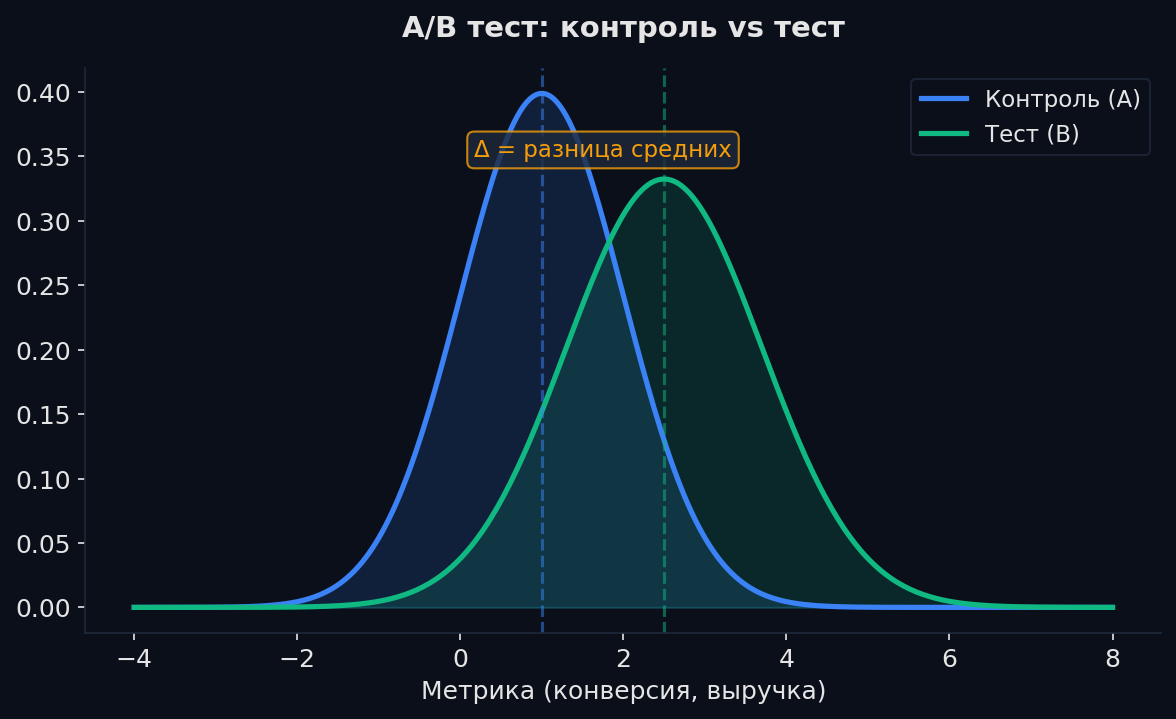
Ты поменял кнопку с синей на зелёную. Конверсия выросла с 3.2% до 3.5%. Это реальный рост или случайность? A/B-тест даёт формальный ответ. 1. H₀ (нулевая гипотеза): эффекта нет, разница = 0. 2. H₁ (альтернативная): эффект есть. 3. Считаем тестовую статистику (z-score). 4. Вычисляем p-value — вероятность такой разницы при H₀. 5. p-value < α (0.05) → отвергаем H₀, эффект значим.
p-value — что это на самом деле
p-value — это НЕ вероятность того, что H₀ верна. Это вероятность получить такие или более экстремальные данные, если H₀ верна. Аналогия: монетка, 100 бросков, 60 орлов. p-value = «вероятность ≥60 орлов при честной монетке». Если мала (< 0.05) → заключаем: монетка нечестная.
Ошибки I и II рода
• Ошибка I рода (False Positive, α): нашли эффект, которого нет. «Пожарная сигнализация сработала, пожара нет». α = 0.05 → готовы ошибиться так в 5% случаев. • Ошибка II рода (False Negative, β): пропустили реальный эффект. «Пожар был, сигнализация молчит». • Мощность (Power) = 1 − β: вероятность обнаружить реальный эффект. Стандарт — 80%. Снижаешь α → растёт β. Единственный способ улучшить оба — увеличить выборку.
Power analysis — сколько данных нужно
Перед запуском теста рассчитай размер выборки. Входы: α (0.05), Power (0.8), MDE (Minimum Detectable Effect). Чем меньше MDE — тем больше нужна выборка. Это причина, почему A/B-тесты идут неделями — нужны миллионы наблюдений для эффекта в 0.1%.
from scipy.stats import proportions_ztest
from statsmodels.stats.power import NormalIndPower
# A/B-тест: 320 конверсий из 10000 (контроль) vs 350 из 10000 (тест)
z_stat, p_value = proportions_ztest([350, 320], [10000, 10000])
print(f"z = {z_stat:.2f}, p-value = {p_value:.4f}, значимо: {p_value < 0.05}")
# Power analysis: сколько нужно в каждой группе?
n = NormalIndPower().solve_power(effect_size=0.01, alpha=0.05, power=0.8)
print(f"Нужно ~{int(n)} объектов в каждой группе")Ловушка множественных сравнений
Корреляция: Pearson, Spearman и почему ≠ причинность
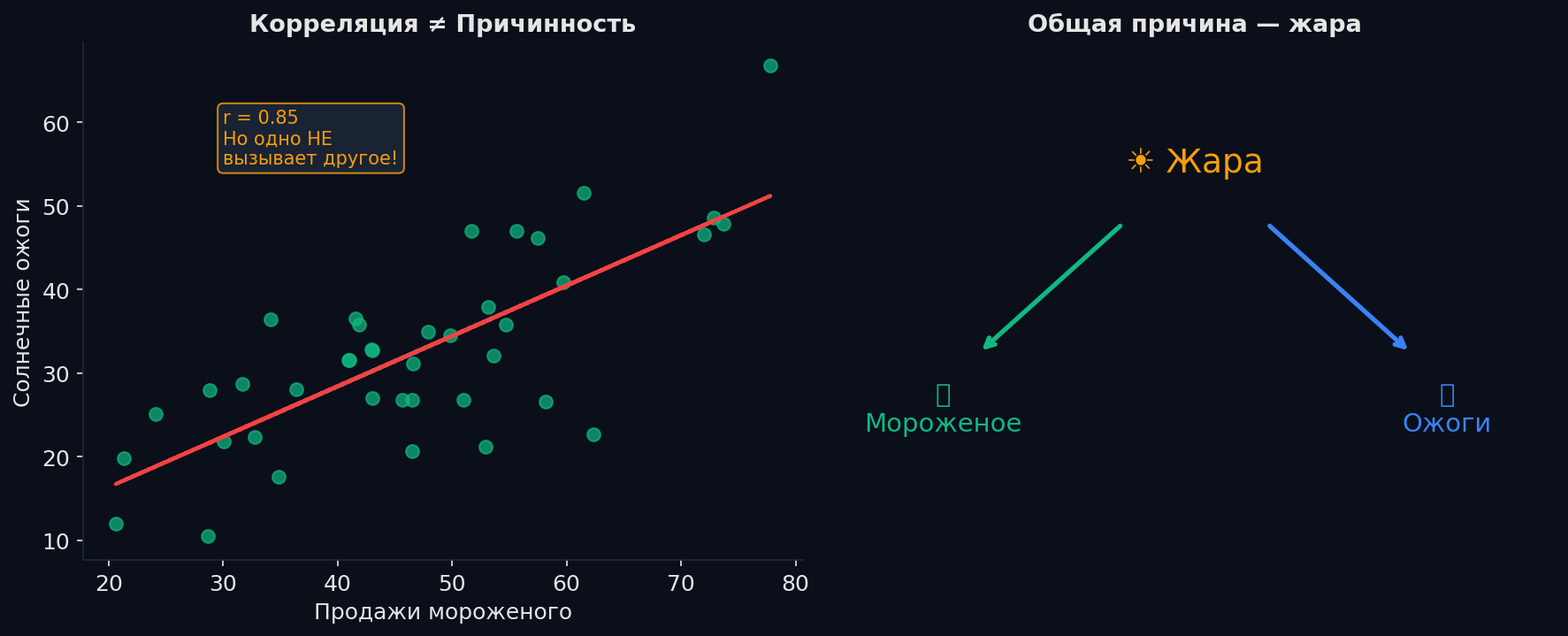
Pearson (r) — линейная связь. Значения от −1 до +1. Чувствителен к выбросам. r = 0 не означает отсутствие связи — может быть нелинейная! Spearman (ρ) — монотонная связь (на рангах). Если доход растёт → счастье растёт (но не линейно), Spearman поймает, Pearson — нет. Робастен к выбросам.
Корреляция ≠ причинность. Три ловушки: • Конфаундер: мороженое и утопления связаны через лето. • Обратная причинность: «больницы → больше смертей» (люди *приходят* в больницы, потому что больны). • Случайная корреляция: на больших данных при тысячах пар переменных неизбежны. Для причинности нужен эксперимент (A/B-тест с рандомизацией) или каузальный анализ.
PCA: снижение размерности
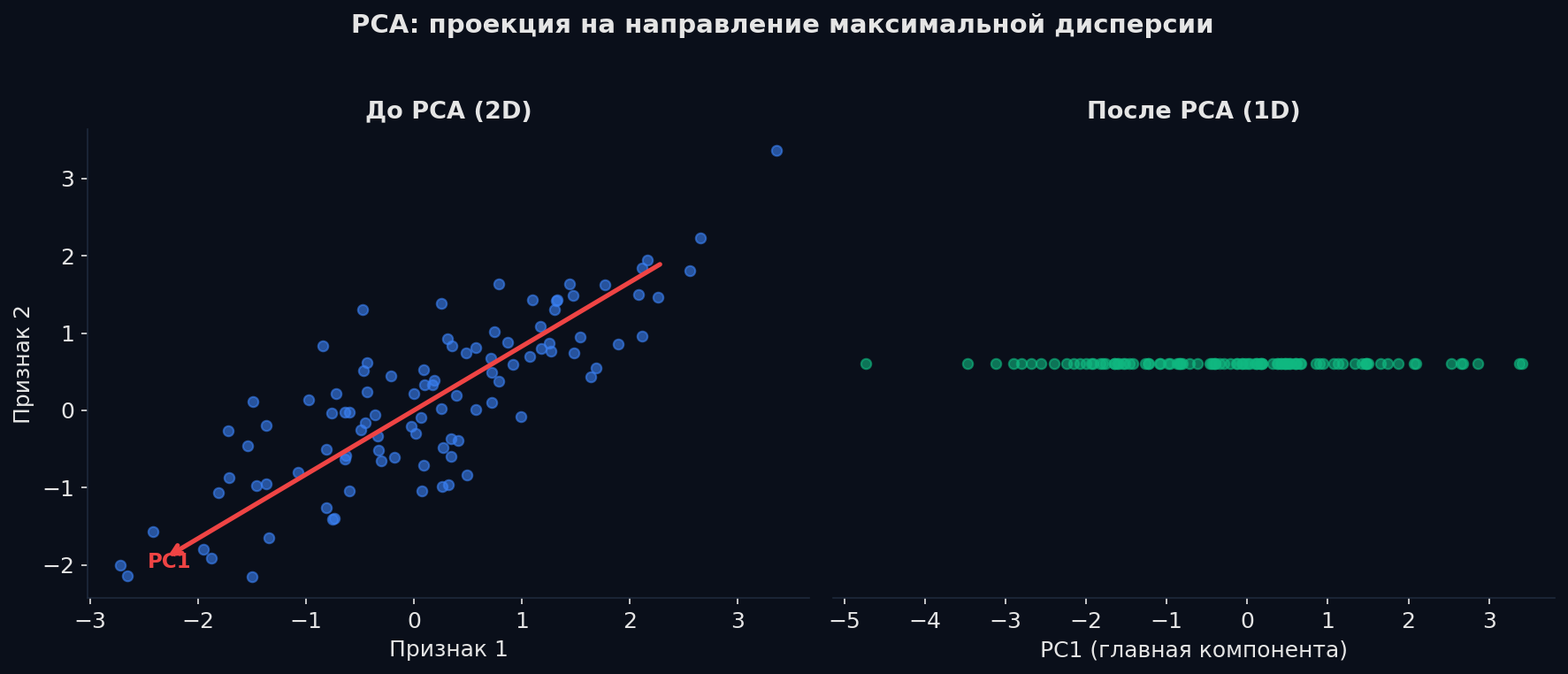
У тебя 500 признаков, многие коррелируют (рост и вес, доход и стоимость машины). PCA находит новые «направления» — главные компоненты — с максимумом информации (дисперсии), и отбрасывает остальные.
Аналогия: фотографируешь скульптуру. С одного ракурса видно максимум деталей (первая компонента), с другого — чуть меньше (вторая), с третьего — ничего нового. PCA находит «лучшие ракурсы» для данных.
Как работает: 1. Центрируем данные (вычитаем среднее). 2. Считаем ковариационную матрицу (как признаки связаны). 3. Находим собственные векторы — направления главных компонент. 4. Собственные значения = сколько дисперсии объясняет каждая компонента. 5. Берём первые k компонент, объясняющих 95% дисперсии.
SVD — математическая основа PCA. Столбцы V — главные компоненты, Σ — их важность
Зачем: визуализация (500 → 2D), ускорение обучения, борьба с мультиколлинеарностью, шумоподавление. Ограничения: только линейные комбинации. Для нелинейных — t-SNE, UMAP (визуализация) или автоэнкодеры.
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits
X, y = load_digits(return_X_y=True) # 64 признака (8x8 пиксели)
pca = PCA(n_components=0.95) # сохранить 95% дисперсии
X_reduced = pca.fit_transform(X)
print(f"{X.shape[1]} → {X_reduced.shape[1]} компонент ({pca.explained_variance_ratio_.sum():.0%} дисперсии)")🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Математика для ML — цепочка от неопределённости к решениям. Вероятность формализует «насколько мы уверены». Теорема Байеса обновляет уверенность данными — это и есть обучение модели. Распределения описывают поведение данных, ЦПТ объясняет, почему так много методов опираются на нормальное. MLE/MAP подбирают параметры, причём регуляризация — это prior. A/B-тесты отвечают: реальный эффект или шум.
Если запомнить одну вещь: статистика — искусство отличать сигнал от шума. p-value, доверительные интервалы, Байес — способы сказать «с какой уверенностью мы можем утверждать X».
Дальше: Классический ML покажет, как эти инструменты работают внутри моделей, а Model Selection научит проверять качество через кросс-валидацию.
Материалы
Визуальное объяснение линейной алгебры — must watch для понимания PCA и SVD.
Интерактивные визуализации вероятности, распределений и статистики.
Лучший вводный курс статистики на русском: распределения, проверка гипотез.
Лучшее визуальное объяснение теоремы Байеса с примером теста на болезнь.
Статистика для DS: распределения, проверка гипотез, A/B-тесты с Python.