Классический ML
Деревья, бустинг, линейные модели, кластеризация — основа большинства production-решений.
Классический ML — от линейной регрессии до градиентного бустинга
Нейросети на хайпе, но 80% production-моделей на табличных данных — это градиентный бустинг. Кредитный скоринг, прогноз оттока, рекомендации товаров, предсказание цен — везде работают «классические» алгоритмы. Они быстрее обучаются, проще в интерпретации и часто не уступают нейросетям на структурированных данных.
Классический ML делится на два больших лагеря: • Supervised learning (обучение с учителем) — есть правильные ответы (метки). Модель учится предсказывать y по x. Регрессия (предсказать число: цена квартиры) и классификация (предсказать класс: спам/не спам). • Unsupervised learning (обучение без учителя) — меток нет. Модель ищет структуру в данных: кластеризация (k-means), снижение размерности (PCA), поиск аномалий. В этой ноде фокус на supervised learning — именно его спрашивают на собеседованиях в 90% случаев.

Большая картина: как устроен ML-пайплайн
Прежде чем углубляться в конкретные алгоритмы, посмотрим на весь путь от «сырых» данных до работающей модели. Это один и тот же пайплайн для любого алгоритма — от линейной регрессии до XGBoost:
Шаг 1. Данные. Собираем таблицу: строки = объекты (пользователи, квартиры, транзакции), столбцы = признаки (features). Шаг 2. Feature engineering. Сырые данные → полезные признаки. Кодируем категории, нормализуем числа, создаём новые фичи (например, «возраст аккаунта в днях» из даты регистрации). Шаг 3. Обучение модели. Алгоритм ищет зависимость между признаками (X) и целевой переменной (y). Линейная регрессия ищет коэффициенты, дерево — пороги разбиения. Шаг 4. Предсказание. Обученная модель получает новый объект и выдаёт ответ: число (регрессия) или класс/вероятность (классификация). Шаг 5. Оценка. Сравниваем предсказания с реальностью. Метрики: MSE, MAE (регрессия), Accuracy, F1, ROC-AUC (классификация). Подробнее — в ноде Метрики классификации.
Линейная регрессия — первый бейзлайн
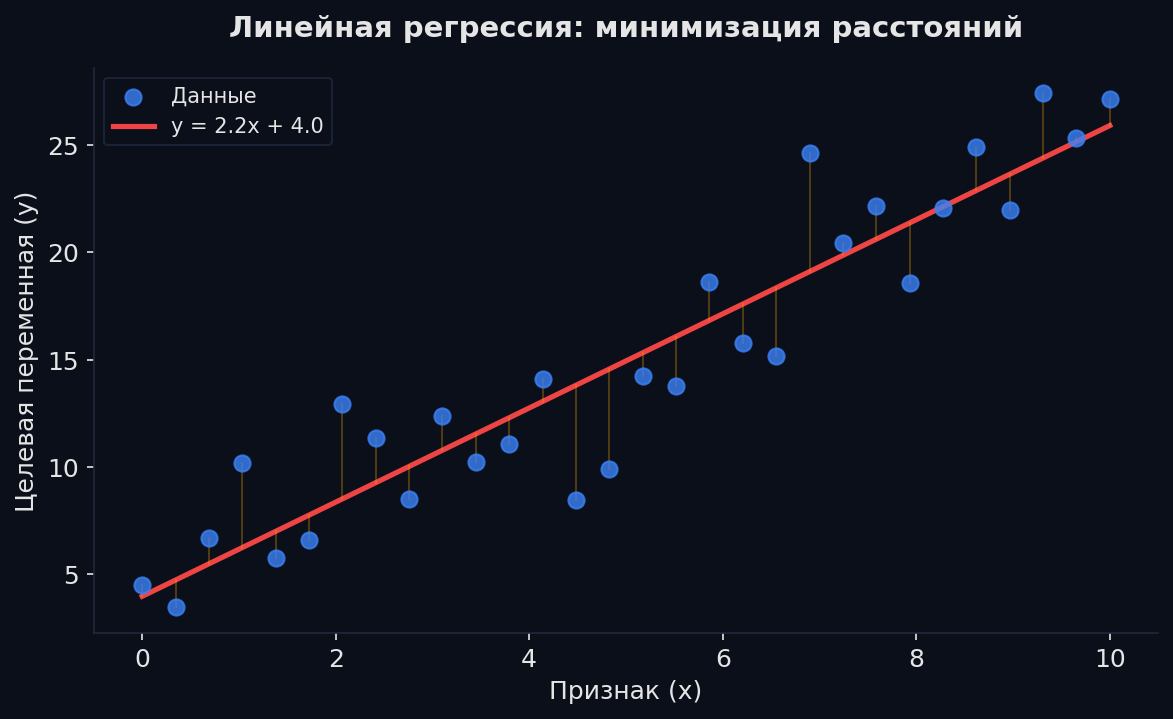
Задача: предсказать число (цену квартиры, зарплату, температуру). Линейная регрессия предполагает, что ответ — это взвешенная сумма признаков плюс свободный член. По сути — провести «лучшую прямую» через облако точек.
Аналогия: ты оцениваешь стоимость квартиры «на глазок». Каждый квадратный метр добавляет ~X рублей, каждый этаж — ещё Y, близость к метро — ещё Z. Линейная регрессия делает то же самое, но находит оптимальные X, Y, Z по данным.
ŷ — предсказание, x₁…xₙ — признаки, w₁…wₙ — веса (сколько «стоит» каждый признак), b — bias (свободный член)
Как найти оптимальные веса? Минимизируем ошибку — среднеквадратичную разницу между предсказаниями и реальными значениями:
MSE (Mean Squared Error) — средний квадрат ошибки. N — число объектов, yᵢ — правильный ответ, ŷᵢ — предсказание модели
Два способа минимизировать MSE: 1. Аналитически (нормальные уравнения): w = (X^T X)^{-1} X^T y. Точное решение за один шаг. Работает для небольших данных, но для миллионов строк — слишком медленно (O(n·d²) по памяти). 2. Градиентный спуск (gradient descent): начинаем со случайных весов, считаем градиент MSE по весам, сдвигаем веса в направлении уменьшения ошибки. Повторяем. Это универсальный метод оптимизации — он же используется в нейросетях.
Числовой пример: предсказываем цену квартиры
Простейший случай: один признак — площадь (x), целевая — цена (y, млн ₽). | Площадь (м²) | Цена (млн ₽) | |---|---| | 30 | 4.5 | | 50 | 7.0 | | 70 | 9.5 | Модель: ŷ = w·x + b. Подставим оптимальные веса (можно вычислить вручную): w = 0.125, b = 0.75. Проверяем: ŷ(30) = 0.125 × 30 + 0.75 = 4.5 ✓, ŷ(50) = 0.125 × 50 + 0.75 = 7.0 ✓. Новая квартира 60 м²: ŷ(60) = 0.125 × 60 + 0.75 = 8.25 млн ₽.
Логистическая регрессия — классификация через вероятность
Теперь задача другая: предсказать не число, а класс. Купит ли пользователь подписку? Спам или не спам? Одобрить кредит или нет? Это бинарная классификация.
Идея: берём линейную комбинацию признаков (как в линейной регрессии), но пропускаем результат через сигмоиду — функцию, которая «сжимает» любое число в диапазон от 0 до 1. Получаем вероятность принадлежности к классу 1.
σ — сигмоида. Если w^T x + b = 0, то σ = 0.5 (граница). Если > 0 → ближе к 1, если < 0 → ближе к 0
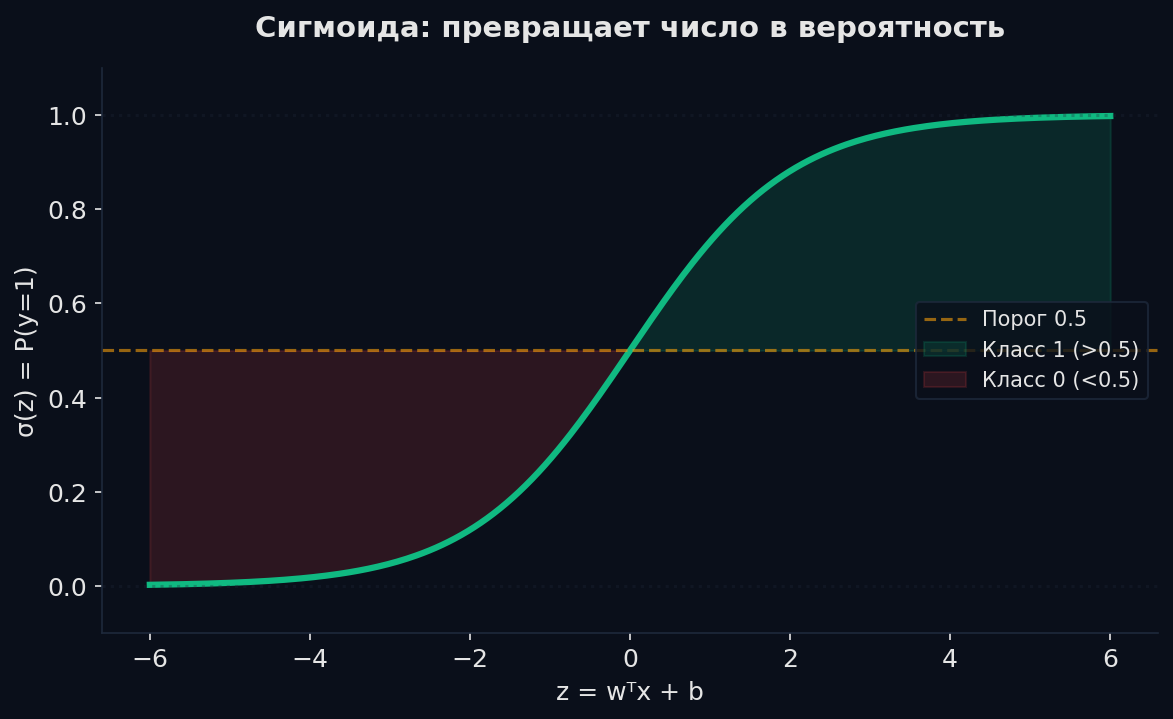
Decision boundary (граница решения) — это гиперплоскость, где P(y=1) = 0.5, то есть w^T x + b = 0. По одну сторону — класс 0, по другую — класс 1. В 2D — это прямая, в 3D — плоскость.
Загрузка интерактивного виджета...
Обучается логрег через log-loss (бинарная кросс-энтропия), а не MSE. Почему? MSE для классификации даёт невыпуклую функцию с локальными минимумами, а log-loss — выпуклую, с единственным глобальным минимумом.
На собесе: зачем нормализовать признаки?
Деревья решений — модель, которую можно объяснить бизнесу
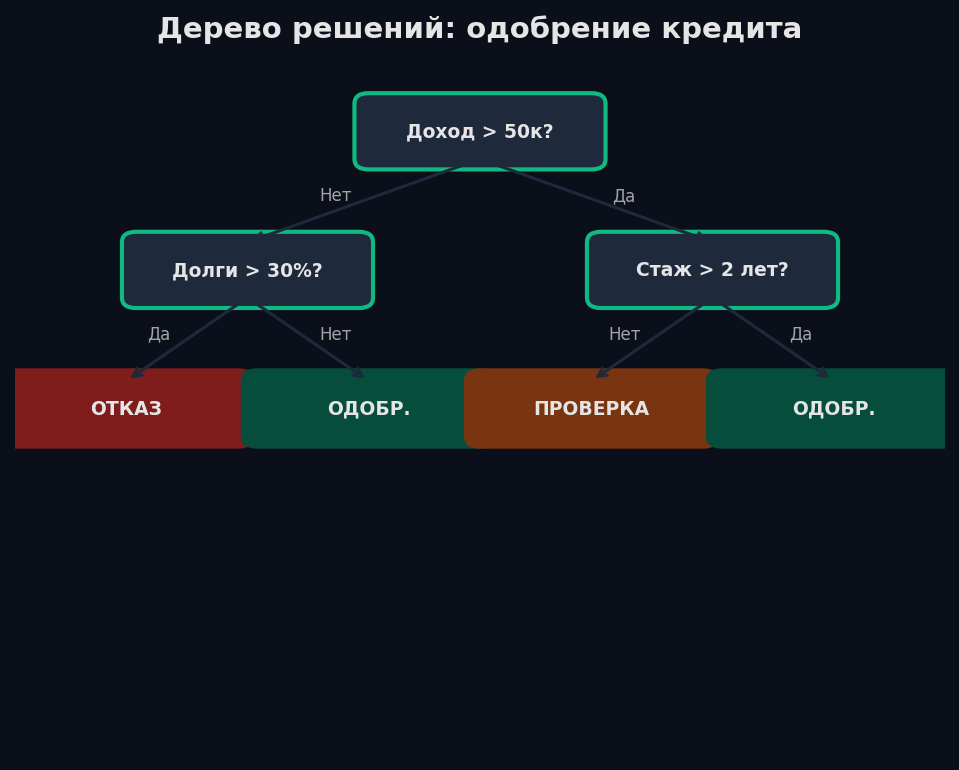
Линейные модели проводят одну границу (прямую/плоскость). А что если граница сложная? Дерево решений разбивает пространство признаков на прямоугольные области, задавая последовательность вопросов: «Доход > 50K? → Возраст > 30? → Одобрить кредит».
Аналогия: врач ставит диагноз по симптомам. «Температура > 38? → Да → Кашель? → Да → Скорее всего грипп». Каждый вопрос делит пациентов на две группы. Дерево решений делает то же самое, но автоматически подбирает вопросы.
Как дерево выбирает вопрос: Gini и Entropy
На каждом шаге дерево перебирает все признаки и все пороги, выбирая тот, который лучше всего разделяет объекты по классам. «Лучше» определяется критерием:
• Gini impurity: Gini = 1 − Σ pᵢ². Чистый узел (один класс): Gini = 0. Максимально «грязный» (50/50): Gini = 0.5. Дерево ищет разбиение, которое максимально снижает Gini. • Entropy (информационный выигрыш): Entropy = −Σ pᵢ · log₂(pᵢ). Чистый узел: 0. Максимально «грязный»: 1. Принцип тот же — выбираем разбиение, которое снижает «хаос». На практике разница между ними минимальна — Gini чуть быстрее (без логарифма), поэтому используется по умолчанию в sklearn.
Пример: 100 заявок на кредит (60 одобрено, 40 отказано). Gini = 1 − (0.6² + 0.4²) = 0.48. Разбиваем по «доход > 50K»: левый узел (55 одобрено, 10 отказано) → Gini = 0.26, правый (5 одобрено, 30 отказано) → Gini = 0.24. Средневзвешенный Gini = 0.65·0.26 + 0.35·0.24 = 0.253 — значительно лучше, чем 0.48.
Переобучение и pruning
Одно дерево без ограничений будет расти, пока каждый лист не станет чистым (один класс). Результат — идеальная точность на обучении и катастрофа на тесте. Дерево выучило шум, а не паттерны.
Как бороться: • Ограничение глубины (max_depth): не давать дереву расти слишком глубоко • Минимум объектов в листе (min_samples_leaf): не создавать листья из 1-2 объектов • Pruning (обрезка): вырастить полное дерево, потом «обрезать» ветви, которые не улучшают качество на валидации Но главное решение проблемы одного дерева — ансамбли.
Random Forest — сила толпы
Одно дерево нестабильно: убрал пару объектов из выборки — получил совершенно другое дерево. Высокий variance (разброс). Как это починить? Построить много деревьев и усреднить их ответы.
Аналогия: хочешь узнать температуру на улице. Один термометр может врать. Но если ты спросишь 100 человек с разными термометрами и возьмёшь среднее — результат будет точнее. Это и есть идея бэггинга (bagging = bootstrap aggregating).
Как работает Random Forest: 1. Из N объектов обучающей выборки создаём T бутстрэп-выборок — случайных выборок с возвращением (каждая размера N, но некоторые объекты повторяются, а ~37% не попадают). 2. На каждой выборке строим дерево. Ключевой трюк: на каждом разбиении дерево выбирает из случайного подмножества из m признаков (обычно m = √d для классификации, m = d/3 для регрессии). Это делает деревья некоррелированными. 3. Для предсказания собираем ответы всех деревьев: голосование (классификация) или среднее (регрессия).
Почему Random Forest лучше одного дерева? Одно дерево ошибается от шума (high variance). Среднее T некоррелированных деревьев имеет дисперсию в T раз меньше — ошибки «гасят» друг друга. При этом бэггинг не увеличивает bias — каждое дерево по-прежнему достаточно сложное. Результат: меньше variance при том же bias = лучшее качество.
Важное свойство
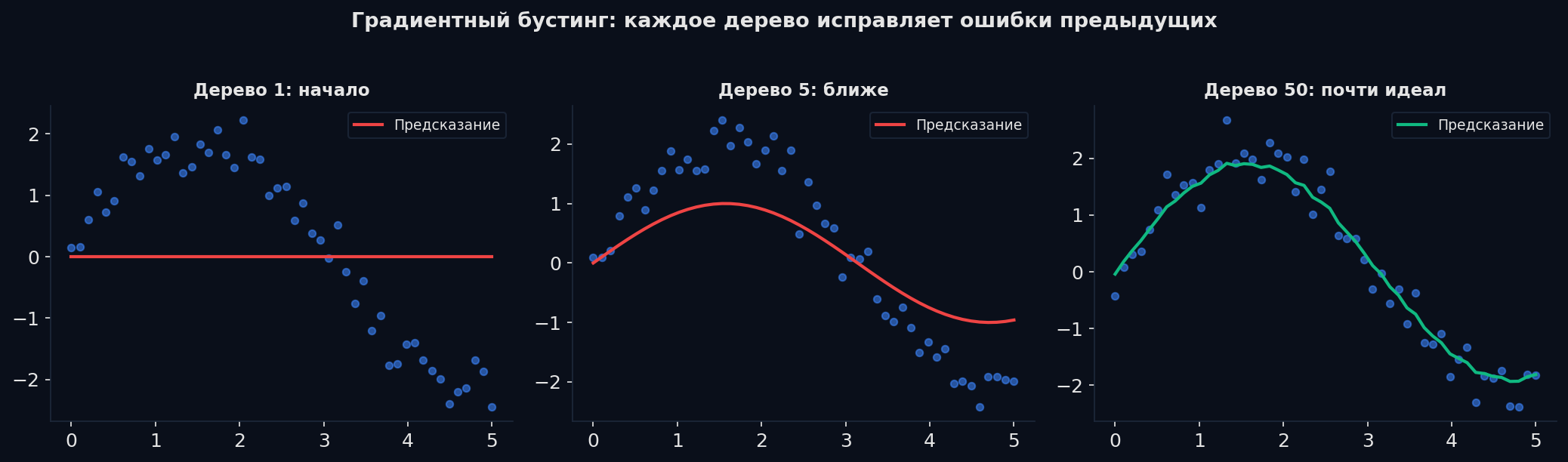
Градиентный бустинг — последовательное исправление ошибок
Random Forest строит деревья параллельно и независимо. Градиентный бустинг — принципиально другой подход: каждое новое дерево учится на ошибках предыдущих.
Аналогия: ты пишешь сочинение. Первый черновик — грубый, но покрывает основные идеи. Второй проход — исправляешь самые грубые ошибки. Третий — шлифуешь детали. Каждая итерация делает текст чуть лучше. Бустинг делает то же: каждое дерево — это «правка» предыдущего результата.
Как работает градиентный бустинг: пошагово
1. Стартовая модель: предсказываем среднее y для всех объектов. Пример: средняя цена квартир = 7 млн. 2. Вычисляем остатки (residuals): для каждого объекта разница между реальным y и текущим предсказанием. Квартира стоит 10 млн, предсказали 7 → остаток = +3. 3. Строим дерево на остатках: новое дерево учится предсказывать эти остатки (ошибки), а не исходные значения. 4. Обновляем предсказание: новое_предсказание = старое + lr × дерево(x), где lr — learning rate (обычно 0.01-0.1). 5. Повторяем шаги 2-4 сотни раз.
Числовой пример: | Квартира | Реальная цена | Шаг 0 (среднее) | Остаток | Шаг 1 (дерево 1) | Новый предсказ | |---|---|---|---|---|---| | A (30 м²) | 4.5 | 7.0 | −2.5 | −2.3 | 7 + 0.1 × (−2.3) = 6.77 | | B (50 м²) | 7.0 | 7.0 | 0 | +0.1 | 7 + 0.1 × 0.1 = 7.01 | | C (70 м²) | 9.5 | 7.0 | +2.5 | +2.2 | 7 + 0.1 × 2.2 = 7.22 | После первого дерева предсказания уже ближе к реальности. После 100-500 деревьев — ещё точнее.
XGBoost, LightGBM, CatBoost — три фреймворка
Идея градиентного бустинга одна, но реализации отличаются. Три главных фреймворка:
XGBoost (2014) — первый «промышленный» бустинг. Регуляризация в loss-функции (L1/L2 на листья). Approximate split finding для больших данных. Доминировал на Kaggle 5+ лет. LightGBM (2017, Microsoft) — leaf-wise рост дерева вместо level-wise. Вместо того чтобы расти «по уровням» (все узлы одной глубины), LightGBM растит лист с наибольшей ошибкой — быстрее сходится. Histogram-based разбиение: признаки дискретизируются в бины, поиск порога за O(#bins) вместо O(#objects). В 5-10× быстрее XGBoost на больших данных. CatBoost (2017, Яндекс) — лучшая обработка категориальных признаков: ordered target statistics вместо one-hot или label encoding. Ordered boosting — борется с target leakage при построении дерева. Работает «из коробки» без тюнинга лучше остальных.
from catboost import CatBoostClassifier
model = CatBoostClassifier(
iterations=500, # число деревьев
depth=6, # глубина каждого дерева
learning_rate=0.05, # шаг обучения (маленький → больше деревьев → точнее)
cat_features=['city', 'profession'], # категориальные признаки
verbose=0,
)
model.fit(X_train, y_train)
print(f"Test accuracy: {model.score(X_test, y_test):.3f}")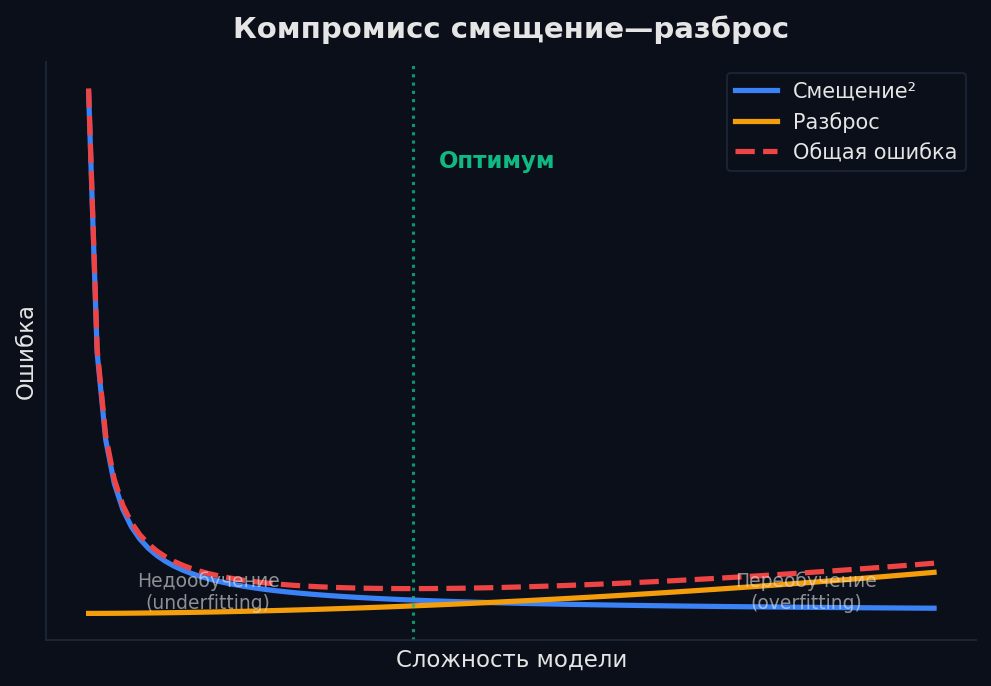
Когда что использовать: таблица выбора алгоритма
Нет «лучшего алгоритма» — есть подходящий для задачи. Вот практические рекомендации:
| Ситуация | Алгоритм | Почему | |---|---|---| | Первый бейзлайн | Логистическая регрессия | Быстро, интерпретируемо, даёт нижнюю границу | | Мало данных (<1K) | Логрег / Random Forest | Бустинг переобучится, линейные модели — нет | | Табличные данные | CatBoost / LightGBM | Лучшее качество на табличных данных. Точка | | Есть категории | CatBoost | Ordered target stats лучше one-hot | | Большие данные (>1M строк) | LightGBM | Histogram + leaf-wise = скорость | | Нужна интерпретируемость | Логрег / одно дерево | Коэффициенты / правила читаются напрямую | | Нужна объяснимость бустинга | SHAP поверх CatBoost | Feature importance + объяснение каждого предсказания | | Изображения / текст / аудио | Нейросети | Классический ML не работает с неструктурированными данными |
Feature engineering — искусство создания признаков
Данные редко приходят в идеальном виде. Feature engineering — это подготовка и трансформация данных так, чтобы модель могла извлечь из них максимум информации. На практике качественные фичи дают больше, чем сложный алгоритм.
Нормализация (для линейных моделей и kNN): • StandardScaler: x → (x − μ) / σ. Среднее = 0, стандартное отклонение = 1. • MinMaxScaler: x → (x − min) / (max − min). Значения в [0, 1]. • Для деревьев/бустинга нормализация не нужна — они работают с порогами. Кодирование категорий: • One-Hot Encoding: город → [0, 1, 0, 0]. Для линейных моделей и когда категорий мало (<20). • Label Encoding: город → 1, 2, 3. Для деревьев — ок, для линейных — опасно (модель решит, что «3 > 1»). • Target Encoding: город → средний y по этому городу. Мощно, но осторожно — risk of target leakage. CatBoost делает это правильно «из коробки». Feature importance — какие признаки реально влияют на результат: • Встроенная (в бустинге): сколько раз признак использовался в разбиениях. • Permutation importance: перемешиваем значения одного признака — смотрим, насколько упало качество. • SHAP values: объясняет вклад каждого признака в каждое конкретное предсказание. Золотой стандарт.
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Классический ML — это лестница от простого к сложному. Линейная регрессия — базовый бейзлайн, взвешенная сумма признаков. Логистическая регрессия — то же + сигмоида для классификации. Деревья решений — нелинейные границы, но склонны к переобучению. Random Forest — ансамбль независимых деревьев, усреднение снижает variance. Градиентный бустинг — последовательное исправление ошибок, снижает bias — и это то, что стоит в продакшне.
Если запомнить одну вещь из этой ноды: на табличных данных бустинг (CatBoost/LightGBM) — король. Но начинай с логрега как бейзлайна, а бустинг — как основная модель. Feature engineering часто важнее выбора алгоритма.
Дальше на роадмапе: Метрики классификации расскажут, как правильно оценить качество модели, а Model Selection — как бороться с переобучением через кросс-валидацию и подбор гиперпараметров.
Материалы
Лучший русскоязычный материал по классическому ML. От линейных моделей до бустинга с теорией и практикой.
Визуальное объяснение градиентного бустинга — пошагово, с числовым примером.
Ordered boosting, обработка категорий, symmetric trees — из первых рук.
Наглядное объяснение бэггинга и Random Forest за 10 минут.
Подробный разбор линейной и логистической регрессии с математикой и кодом.