Основы нейросетей
Перцептрон, MLP, backpropagation, функции активации и потерь — как нейросети учатся.
Основы глубокого обучения — от перцептрона до backpropagation
В предыдущей ноде мы построили первую нейросеть, обучили MLP на MNIST и разобрались с forward pass. Теперь идём глубже: как именно сеть учится (backpropagation), какие функции потерь выбирать, и почему глубокие сети сложнее обучать (vanishing/exploding gradients). Это фундамент, без которого не получится осознанно проектировать и отлаживать модели.
Перцептрон и MLP — формальный взгляд
Перцептрон Розенблатта (1958) — исторически первая модель нейрона. Он принимает входы, умножает на веса, суммирует и пропускает через ступенчатую функцию: выход 0 или 1. Один перцептрон разделяет пространство гиперплоскостью — он не может решить даже XOR. Это ограничение описали Минский и Паперт в 1969 году, что привело к первой «зиме» нейросетей.
MLP (Multi-Layer Perceptron) решает проблему: несколько слоёв перцептронов с гладкими функциями активации могут аппроксимировать любую непрерывную функцию (Universal Approximation Theorem). Ключевое слово — гладкие: ступенчатая функция не дифференцируема, а нам нужны градиенты для обучения. Поэтому вместо неё используют sigmoid, tanh, ReLU и другие.
import torch
import torch.nn as nn
class MLP(nn.Module):
"""MLP с тремя скрытыми слоями — типичная архитектура для табличных данных."""
def __init__(self, input_dim: int, hidden_dim: int, num_classes: int):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(hidden_dim, num_classes), # logits, без softmax
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)
# Пример: 100 признаков, 256 скрытых нейронов, 10 классов
model = MLP(input_dim=100, hidden_dim=256, num_classes=10)
print(f"Параметров: {sum(p.numel() for p in model.parameters()):,}")
# → 92,938 — всё ещё маленькая сеть по меркам DLЗагрузка интерактивного виджета...
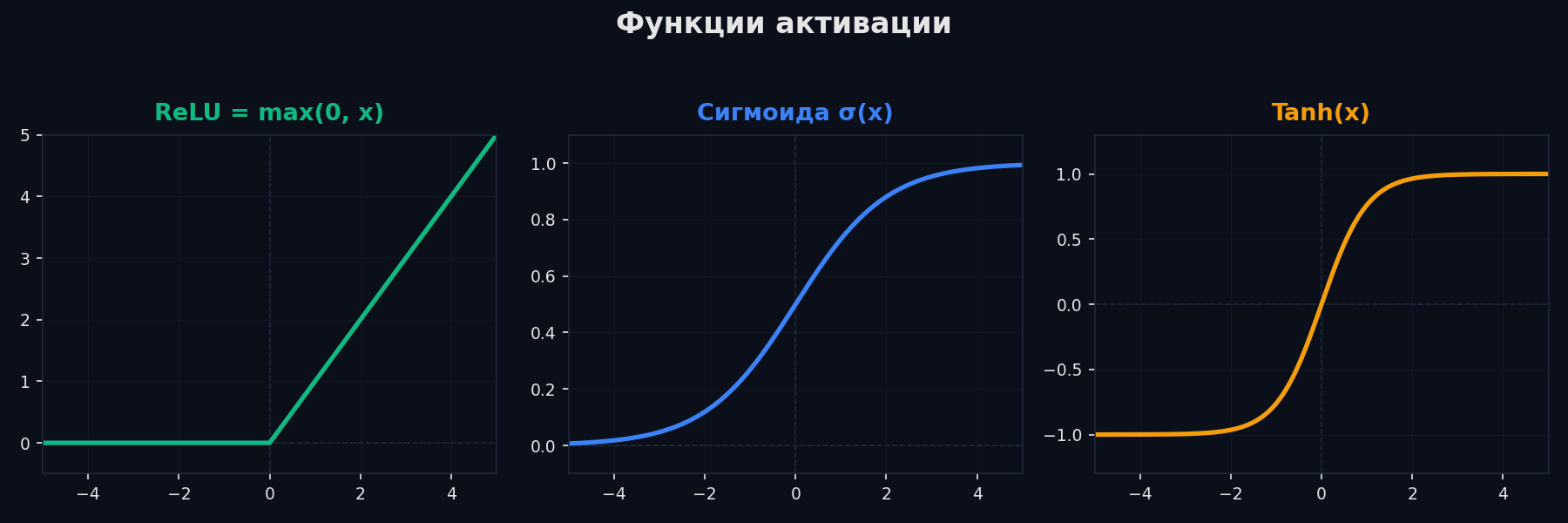
Функции активации: ReLU, sigmoid, tanh, GELU
Функция активации — это нелинейность, которая вставляется после каждого линейного слоя. Без неё глубокая сеть коллапсирует в одну линейную функцию (произведение матриц = матрица). Выбор активации влияет на скорость обучения, стабильность градиентов и выразительность сети.
- Sigmoid σ(x) = 1/(1+e⁻ˣ) — выход [0, 1]. Используется в выходном слое для бинарной классификации. В скрытых слоях не используется из-за vanishing gradients: максимальная производная всего 0.25.
- Tanh tanh(x) = (eˣ−e⁻ˣ)/(eˣ+e⁻ˣ) — выход [−1, 1]. Центрирована вокруг нуля (в отличие от sigmoid), что помогает оптимизации. Но тоже насыщается при |x| > 3. Используется в LSTM/GRU.
- ReLU f(x) = max(0, x) — стандарт для CNN и MLP. Производная = 1 при x > 0, нет насыщения. Проблема: dead neurons (если x < 0 всегда → нейрон никогда не обновляется). Решение: Leaky ReLU (f(x) = max(0.01x, x)).
- GELU x·Φ(x) — гладкая версия ReLU. Стандарт в трансформерах (BERT, GPT). Не обрезает отрицательные значения жёстко, а плавно «приглушает» их.
ReLU — простой и быстрый. GELU — гладкий аналог, используемый в трансформерах. Φ — CDF нормального распределения.
Практическое правило
Backpropagation — chain rule и граф вычислений
Backpropagation — это алгоритм вычисления градиентов функции потерь по всем параметрам сети. Математическая основа — chain rule (правило цепочки) из матанализа. Суть: если y = f(g(x)), то dy/dx = (dy/dg)·(dg/dx). Для нейросети: loss зависит от выходов последнего слоя, те — от предпоследнего, и так до первого слоя.
Chain rule для нейросети: градиент «протекает» обратно через слои. aₗ — активация слоя l, zₗ — линейная комбинация. Каждый множитель — производная одного слоя.
Computation graph (вычислительный граф) — это DAG (направленный ациклический граф), где каждый узел — операция (умножение, сложение, ReLU), а рёбра — тензоры. PyTorch строит этот граф динамически при каждом forward pass, а потом обходит его в обратном порядке (backward pass), вычисляя градиенты. Это и есть autograd.
Пошаговый пример. Один нейрон: z = w·x + b, a = ReLU(z), L = (a − y)². 1. Forward: x=2, w=0.5, b=0.1, y=1.5 → z = 0.5·2 + 0.1 = 1.1 → a = ReLU(1.1) = 1.1 → L = (1.1 − 1.5)² = 0.16 2. Backward: • ∂L/∂a = 2·(a − y) = 2·(1.1 − 1.5) = −0.8 • ∂a/∂z = 1 (ReLU, z > 0) • ∂z/∂w = x = 2 • ∂L/∂w = −0.8 · 1 · 2 = −1.6 — вес нужно увеличить (градиент отрицательный) • ∂z/∂b = 1 → ∂L/∂b = −0.8 · 1 · 1 = −0.8 3. Update: w ← w − lr·(−1.6) = 0.5 + 0.016 = 0.516 (при lr=0.01)
import torch
# PyTorch строит computation graph автоматически
x = torch.tensor(2.0)
w = torch.tensor(0.5, requires_grad=True)
b = torch.tensor(0.1, requires_grad=True)
y = torch.tensor(1.5)
# Forward pass — граф строится на лету
z = w * x + b
a = torch.relu(z)
loss = (a - y) ** 2
# Backward pass — autograd обходит граф обратно
loss.backward()
print(f"∂L/∂w = {w.grad:.4f}") # -1.6000 ✓
print(f"∂L/∂b = {b.grad:.4f}") # -0.8000 ✓
# Это масштабируется до миллионов параметров без изменения кода!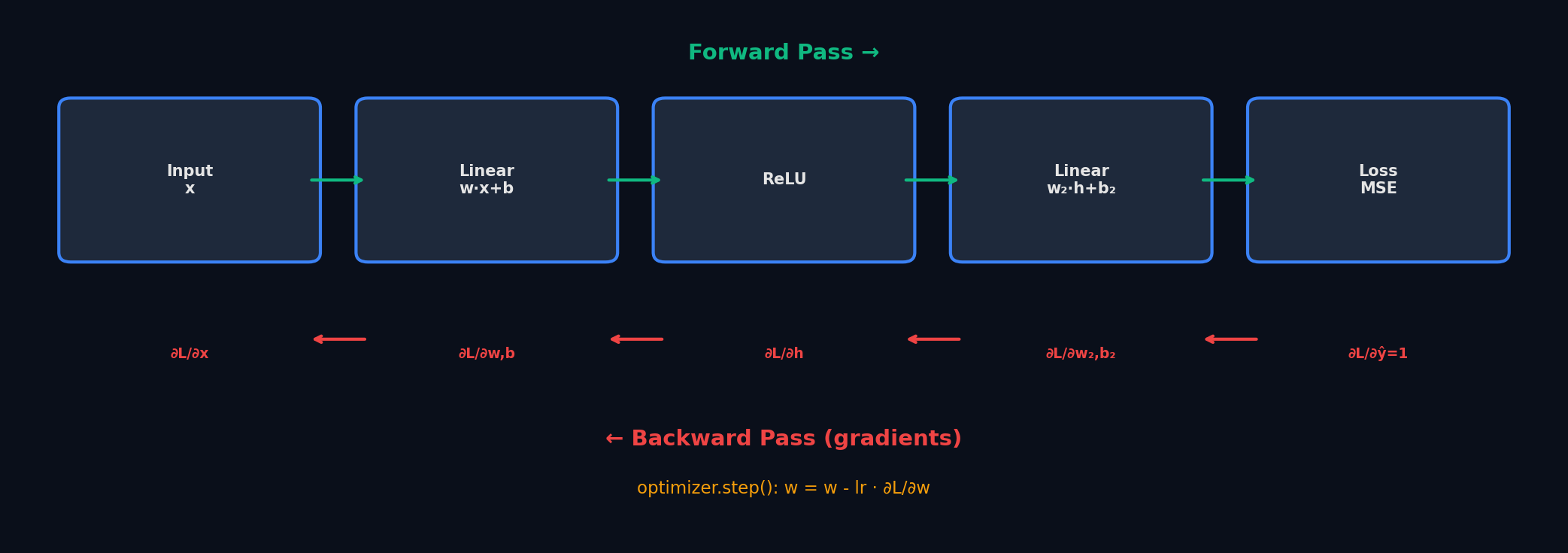

Загрузка интерактивного виджета...
Интерактив ниже — полноценная визуализация backpropagation на сети 2→2→1. Пройдите все 10 шагов: forward pass (weighted sum + activation), вычисление loss, backward pass (chain rule через каждый слой) и обновление весов. Можно менять входы, target и learning rate — числа пересчитаются в реальном времени.
Загрузка интерактивного виджета...
Функции потерь: CE, BCE, MSE, Focal Loss
Loss функция — это то, что сеть реально оптимизирует. Выбор loss определяет поведение модели: какие ошибки она считает критичными, а какие — терпимыми. Неправильно выбранная loss — частая причина «модель обучается, но плохо работает».
Cross-Entropy для C классов (слева) и Binary Cross-Entropy (справа). y — ground truth, ŷ — предсказание.
- MSE = (1/n)Σ(ŷ−y)² — для регрессии. Квадрат сильно штрафует выбросы. Если выбросы — проблема, используй MAE или Huber Loss.
- Cross-Entropy (CE) = −Σ yᵢ·log(ŷᵢ) — для многоклассовой классификации. В PyTorch:
nn.CrossEntropyLoss()ожидает сырые logits (softmax встроен). Интуиция: штрафует сильнее, когда модель уверена в неправильном ответе. - Binary CE (BCE) — для бинарной классификации или multilabel. Последний слой — sigmoid. В PyTorch:
nn.BCEWithLogitsLoss()(sigmoid + BCE в одном — численно стабильнее). - Focal Loss = −αₜ(1−pₜ)ᵞ · log(pₜ) — модификация CE для дисбалансированных данных. Параметр γ (обычно 2) понижает вклад «лёгких» примеров и фокусирует обучение на «сложных». Стандарт в object detection (RetinaNet).
import torch
import torch.nn as nn
import torch.nn.functional as F
# MSE — регрессия
loss_mse = nn.MSELoss()
pred = torch.tensor([2.5, 0.3])
target = torch.tensor([3.0, 0.5])
print(f"MSE: {loss_mse(pred, target):.4f}") # 0.1450
# Cross-Entropy — многоклассовая классификация
loss_ce = nn.CrossEntropyLoss()
logits = torch.tensor([[2.0, 1.0, 0.1]]) # 3 класса, сырые logits
label = torch.tensor([0]) # правильный класс = 0
print(f"CE: {loss_ce(logits, label):.4f}") # 0.4170
# BCE — бинарная / multilabel
loss_bce = nn.BCEWithLogitsLoss()
logit = torch.tensor([1.5]) # до sigmoid
label_bin = torch.tensor([1.0])
print(f"BCE: {loss_bce(logit, label_bin):.4f}") # 0.2014
# Focal Loss — для дисбалансированных данных
def focal_loss(logits: torch.Tensor, targets: torch.Tensor,
gamma: float = 2.0, alpha: float = 0.25) -> torch.Tensor:
bce = F.binary_cross_entropy_with_logits(logits, targets, reduction='none')
p_t = torch.exp(-bce)
return (alpha * (1 - p_t) ** gamma * bce).mean()Vanishing и Exploding Gradients
Chain rule для L слоёв — это произведение L множителей. Если каждый множитель < 1 (sigmoid: max 0.25), градиент экспоненциально убывает: 0.25¹⁰ ≈ 10⁻⁶. Первые слои не обучаются — это vanishing gradients. Если множители > 1, градиент экспоненциально растёт — exploding gradients (веса «разлетаются» в NaN).
Vanishing gradients — главная причина, почему глубокие сети с sigmoid/tanh не обучались десятилетиями. Решения: • ReLU — производная = 1 при x > 0, градиент не затухает. • Residual connections (ResNet) — skip connections обходят слои: x + F(x). Градиент течёт по «короткому пути» в обход проблемных слоёв. • Нормализация — BatchNorm / LayerNorm удерживают активации в «здоровом» диапазоне. • Правильная инициализация — Xavier или Kaiming (подробнее ниже).
Exploding gradients — частая проблема в RNN. Решения:
• Gradient clipping — если норма градиента > threshold, масштабируем его: torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0). Простой и эффективный хак.
• Правильная инициализация и нормализация тоже помогают.
Как диагностировать
for name, p in model.named_parameters(): print(name, p.grad.norm()). Если градиенты первых слоёв на порядки меньше последних — vanishing. Если NaN/Inf в loss — exploding. Логируй градиенты в TensorBoard/W&B.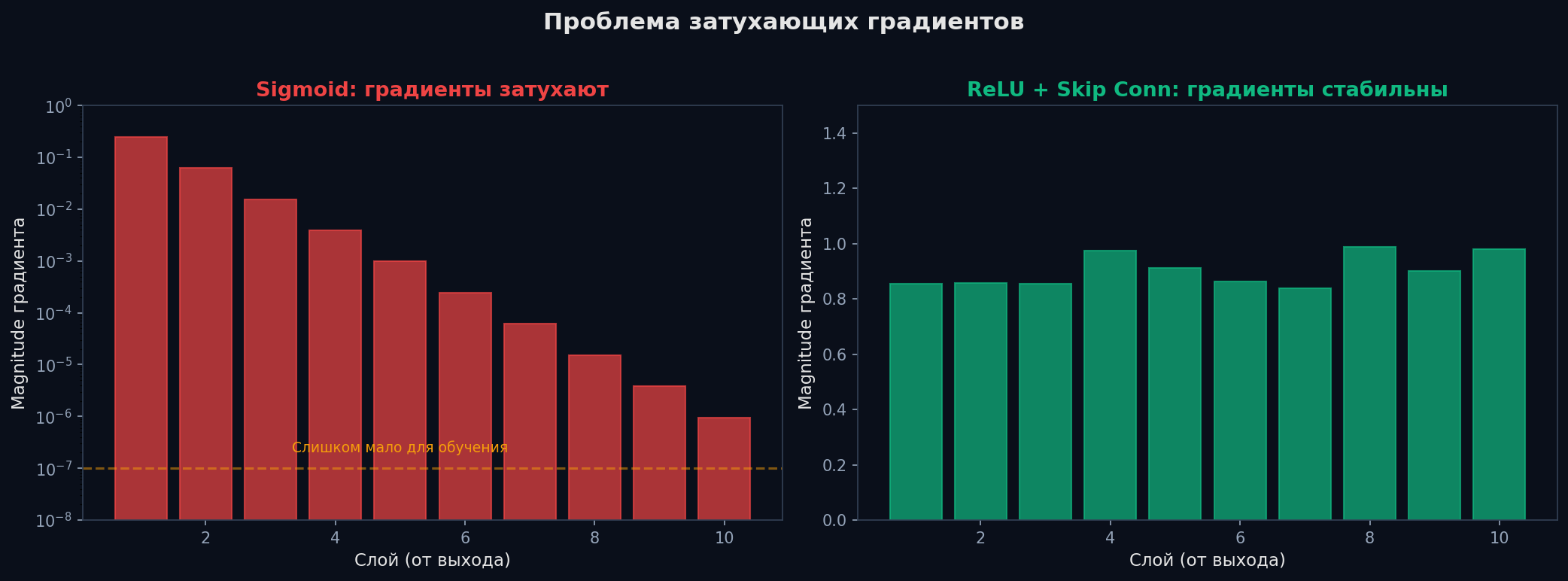
Инициализация весов: Xavier и Kaiming
Аналогия: представь оркестр из 100 музыкантов. Если все начнут играть слишком громко — какофония, звук зашкаливает (exploding). Слишком тихо — зал ничего не услышит (vanishing). Нужна правильная начальная громкость каждого инструмента, чтобы звук проходил через все секции оркестра без искажений. Xavier и Kaiming — это формулы для этой «стартовой громкости».
Если инициализировать веса нулями — все нейроны в слое будут вычислять одно и то же (symmetry problem). Если слишком большими — exploding gradients. Если слишком маленькими — vanishing. Нужна «золотая середина», при которой дисперсия активаций сохраняется от слоя к слою.
- Xavier (Glorot) init — для sigmoid/tanh: W ~ N(0, 2/(nᵢₙ + nₒᵤₜ)). Уравновешивает дисперсию при прямом и обратном проходе. Предполагает линейную активацию вокруг нуля.
- Kaiming (He) init — для ReLU: W ~ N(0, 2/nᵢₙ). Учитывает, что ReLU зануляет половину нейронов, поэтому дисперсия должна быть в 2 раза больше. Стандарт для CNN и MLP с ReLU.
- Constant / Zeros — для bias (обычно инициализируют нулями, это нормально).
- В PyTorch Linear слои по умолчанию используют Kaiming uniform — для большинства задач менять не нужно.
nᵢₙ — число входов нейрона, nₒᵤₜ — число выходов. Kaiming — стандарт для ReLU-сетей.
import torch.nn as nn
# PyTorch автоматически использует Kaiming для nn.Linear
model = nn.Sequential(
nn.Linear(784, 256), # kaiming_uniform_ по умолчанию
nn.ReLU(),
nn.Linear(256, 10),
)
# Ручная инициализация (если нужно)
def init_weights(m: nn.Module):
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, nonlinearity='relu')
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
model.apply(init_weights) # рекурсивно ко всем слоям
# Проверка дисперсии активаций (должна быть ~1 на каждом слое)
x = torch.randn(64, 784)
for layer in model:
x = layer(x)
if isinstance(layer, nn.Linear):
print(f"{layer}: mean={x.mean():.3f}, std={x.std():.3f}")Полный пример: nn.Module с training loop
Соберём всё вместе: MLP как nn.Module, Kaiming init, Cross-Entropy loss, Adam optimizer, gradient clipping.
import torch
import torch.nn as nn
class Classifier(nn.Module):
def __init__(self, input_dim: int, hidden_dim: int, num_classes: int,
dropout: float = 0.2):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, hidden_dim // 2),
nn.BatchNorm1d(hidden_dim // 2),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim // 2, num_classes),
)
self._init_weights()
def _init_weights(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, nonlinearity='relu')
nn.init.zeros_(m.bias)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.layers(x)
# Training loop с gradient clipping
model = Classifier(input_dim=784, hidden_dim=256, num_classes=10)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss()
for epoch in range(10):
model.train()
for x_batch, y_batch in train_loader: # предполагаем DataLoader
logits = model(x_batch) # forward
loss = criterion(logits, y_batch) # loss
optimizer.zero_grad() # обнуляем градиенты
loss.backward() # backprop
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # clipping
optimizer.step() # update weights🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Backpropagation (chain rule по computation graph) — единственный способ обучать глубокие сети. Loss функция определяет что оптимизируем (CE для классификации, MSE для регрессии, Focal для дисбаланса). Активация определяет выразительность сети (ReLU — стандарт, GELU — для трансформеров). Инициализация (Kaiming/Xavier) и нормализация (BatchNorm/LayerNorm) решают проблему vanishing/exploding gradients и делают глубокие сети обучаемыми.
Дальше: Архитектуры нейросетей — CNN для изображений, RNN для последовательностей, и краткий обзор трансформеров, которые захватили мир.
Материалы
Лучшая визуализация backpropagation: как градиенты текут через сеть. Обязательно к просмотру.
Конспекты Андрея Карпати: computation graph, backprop, weight initialization. Золотой стандарт.
Фундаментальный учебник: глубокие сети, регуляризация, оптимизация. Главы 6-8 покрывают все темы этой ноды.
Практический старт: тензоры, autograd, backprop — всё на реальном коде.