Нейросети и Deep Learning
Перцептроны, backprop, CNN, RNN — понимание основ нейросетей на PyTorch.
Нейросети — от одного нейрона до глубокого обучения
Градиентный бустинг отлично работает на таблицах, но попробуй скормить ему картинку 224×224 — это 150 тысяч признаков, и ни один из них сам по себе не значит ничего. Пиксель [112, 54] = 0.73 — это кусочек уха? Часть фона? Без контекста непонятно. Нейросети умеют сами находить структуру: первый слой выучивает рёбра, второй — текстуры, третий — части объектов. Никто не задаёт эти признаки вручную — сеть извлекает их из данных.
Ключевое отличие от классического ML: в классическом ML ты придумываешь признаки (feature engineering), а модель учит веса. В глубоком обучении сеть учит и признаки, и веса — это называется representation learning. Чем больше данных и слоёв, тем более абстрактные признаки сеть находит.
Большая картина: как работает нейросеть
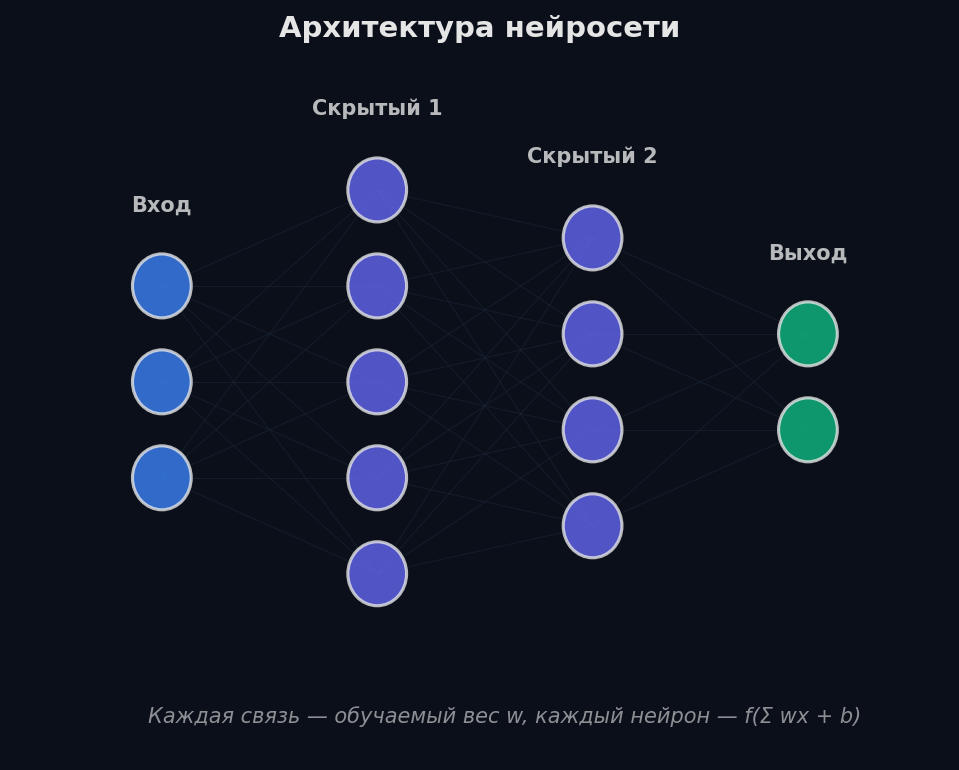
Любая нейросеть — это функция, которая принимает числа на входе и выдаёт числа на выходе. Между входом и выходом — слои (layers). Каждый слой берёт вектор чисел, умножает на матрицу весов, прибавляет смещение (bias) и пропускает через нелинейную функцию (активацию). Результат передаётся следующему слою.
Весь процесс в 5 шагов: 1. Вход — числовое представление данных (пиксели, эмбеддинги слов, признаки). 2. Forward pass — данные проходят через слои: каждый слой трансформирует представление. Первые слои ловят простые паттерны, глубокие — сложные. 3. Предсказание — последний слой выдаёт ответ (число для регрессии, вероятности для классификации). 4. Loss — функция потерь сравнивает предсказание с правильным ответом и выдаёт одно число: насколько мы ошиблись. 5. Backprop + Update — градиенты ошибки «текут» обратно, оптимизатор подкручивает веса. Повторяем тысячи раз.
Загрузка интерактивного виджета...
Ключевая идея
Перцептрон — один нейрон, основа всего
Самый простой элемент нейросети — один нейрон (перцептрон). Он берёт входы, умножает каждый на свой вес, складывает, прибавляет bias и пропускает через функцию активации. По сути — это линейная регрессия + нелинейность.
w — веса (какой вход насколько важен), b — bias (смещение), σ — функция активации (добавляет нелинейность)
Пример на числах. Нейрон решает: «давать ли кредит?». Входы: x₁ = 0.7 (доход, нормализован), x₂ = 0.3 (кредитная история). Веса: w₁ = 0.6, w₂ = 0.8, bias b = −0.5. 1. Линейная комбинация: z = 0.6·0.7 + 0.8·0.3 + (−0.5) = 0.42 + 0.24 − 0.5 = 0.16 2. Активация (sigmoid): σ(0.16) = 1/(1 + e⁻⁰·¹⁶) ≈ 0.54 3. Решение: вероятность одобрения 54% — пограничный случай. Если бы доход был выше (x₁ = 0.9): z = 0.54 + 0.24 − 0.5 = 0.28, σ(0.28) ≈ 0.57. Вес w₁ = 0.6 «тянет» предсказание вверх при росте дохода — нейрон выучил, что доход важен.
Зачем bias?
Полносвязная сеть (MLP) — слои нейронов
Один нейрон может разделить данные только прямой линией (гиперплоскостью). Для сложных задач нужно больше нейронов. MLP (Multi-Layer Perceptron, полносвязная сеть) — это слои нейронов, соединённые «каждый с каждым». Каждый слой — матричное умножение + активация.
Forward pass пошагово (сеть: 2 входа → 3 скрытых нейрона → 1 выход): 1. Вход: x = [0.5, 0.8] (2 признака) 2. Скрытый слой: z₁ = W₁·x + b₁ — матрица W₁ размера [3×2] умножается на вектор x [2×1], получаем [3×1]. Активация: h = ReLU(z₁) — три числа. 3. Выходной слой: z₂ = W₂·h + b₂ — матрица W₂ [1×3] × вектор h [3×1] = скаляр. Активация: σ(z₂) — вероятность.
Каждый слой увеличивает выразительную силу сети. Один скрытый слой с достаточным числом нейронов может аппроксимировать любую непрерывную функцию — это Universal Approximation Theorem. Но на практике глубокие сети (много слоёв) эффективнее широких (много нейронов в одном слое): они строят иерархию признаков.
import torch.nn as nn
# MLP для бинарной классификации
model = nn.Sequential(
nn.Linear(2, 3), # 2 входа → 3 скрытых нейрона (6 весов + 3 bias)
nn.ReLU(), # нелинейность
nn.Linear(3, 1), # 3 скрытых → 1 выход (3 веса + 1 bias)
nn.Sigmoid() # вероятность [0, 1]
)
# Итого параметров: 6 + 3 + 3 + 1 = 13. Маленькая сеть!Функции активации — почему нелинейность критична
Без активации нейросеть — это цепочка матричных умножений: W₂·(W₁·x) = (W₂·W₁)·x = W·x. Сколько бы слоёв ни было, результат — одна линейная функция. Нейросеть из 100 слоёв без активации = линейная регрессия. Активация ломает линейность и даёт сети способность моделировать сложные зависимости.
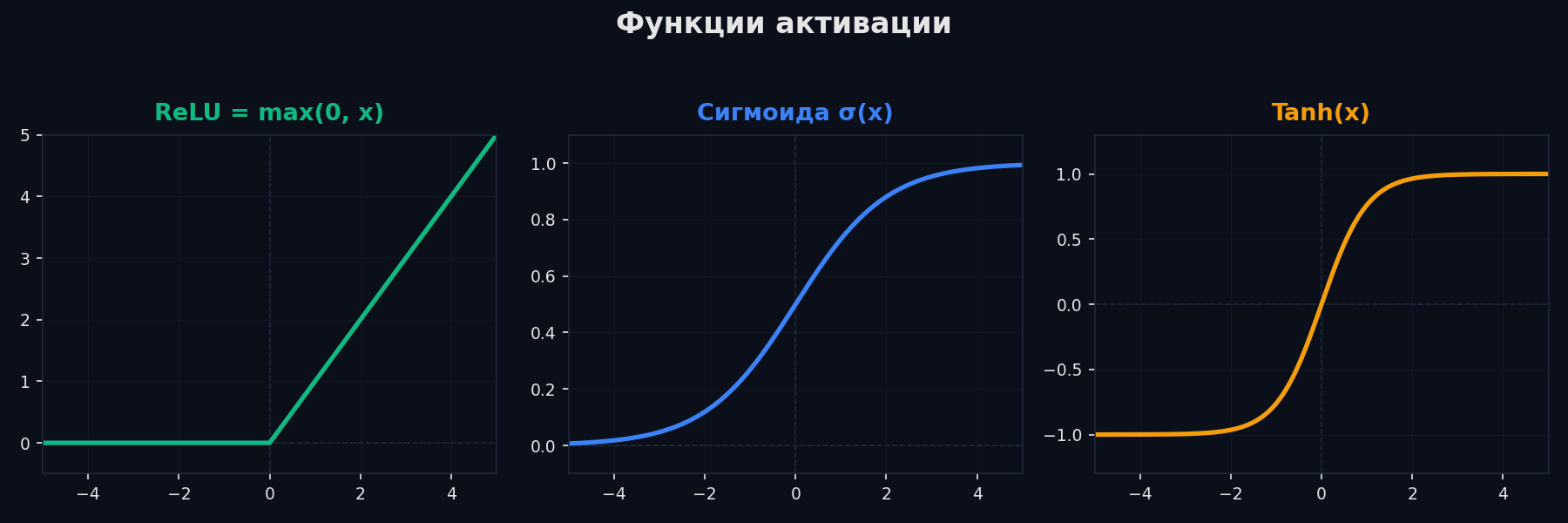
Sigmoid σ(x) = 1/(1+e⁻ˣ) — исторически первая. Выход от 0 до 1, удобна для вероятностей. Проблема: при |x| > 5 градиент почти нулевой (насыщение) → vanishing gradients. Максимальный градиент σ'(x) = 0.25 — при 10 слоях: 0.25¹⁰ ≈ 10⁻⁶. Первые слои не учатся.
ReLU (Rectified Linear Unit): f(x) = max(0, x). Революция 2012 года. Градиент = 1 при x > 0 — не затухает. Вычисляется мгновенно (одно сравнение). Минус: при x < 0 градиент = 0 — нейрон «мёртв» (dead ReLU). Решение: Leaky ReLU — f(x) = max(0.01x, x).
GELU (Gaussian Error Linear Unit): x · Φ(x), где Φ — функция распределения нормального закона. Гладкая версия ReLU: вместо жёсткого обрезания в нуле — плавный переход. Используется в BERT, GPT, современных трансформерах. На практике: ReLU для CNN и простых сетей, GELU для трансформеров.
Softmax — не для скрытых слоёв, а для выхода при многоклассовой классификации. Превращает вектор чисел в вероятности (все положительные, сумма = 1). Формула: softmax(zᵢ) = eᶻⁱ / Σeᶻʲ.
Loss функции — как измерить ошибку
Loss (функция потерь) — единственный сигнал, по которому сеть учится. Она берёт предсказание и правильный ответ и выдаёт число: насколько плохо предсказание. Выбор loss определяет, что именно сеть оптимизирует.
MSE (Mean Squared Error) = (1/n) Σ(ŷᵢ − yᵢ)² — для регрессии. Предсказываешь число (цена, температура) — используй MSE. Квадрат сильно штрафует большие ошибки: ошибка 10 «стоит» в 100 раз больше, чем ошибка 1. Если выбросы — проблема, бери MAE (|ŷ − y|) или Huber loss (комбинация MSE и MAE).
Cross-Entropy = −Σ yᵢ log(ŷᵢ) — для классификации. Мера расхождения между реальным распределением (one-hot вектор) и предсказанными вероятностями. Интуиция: если правильный класс 3, а модель предсказала P(класс 3) = 0.01 — cross-entropy огромная (−log(0.01) = 4.6). Если P(класс 3) = 0.99 — маленькая (−log(0.99) = 0.01).
Бинарная Cross-Entropy (BCE): для 2 классов. Последний слой — sigmoid, loss = −[y·log(ŷ) + (1−y)·log(1−ŷ)]. Categorical Cross-Entropy: для N классов. Последний слой — softmax, loss = −Σ yᵢ·log(ŷᵢ). Запомни: регрессия → MSE, классификация → Cross-Entropy. Это покрывает 90% задач.
import torch.nn as nn
# Регрессия — MSE
loss_fn = nn.MSELoss()
loss = loss_fn(predicted, target) # оба — тензоры float
# Бинарная классификация — BCE (sigmoid на последнем слое)
loss_fn = nn.BCEWithLogitsLoss() # sigmoid + BCE в одном (численно стабильнее)
loss = loss_fn(logits, labels) # logits — до sigmoid, labels — 0/1
# Многоклассовая — CrossEntropy (softmax + NLL в одном)
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(logits, class_indices) # logits [B, C], indices [B] (не one-hot!)Как устроено обучение: epoch, batch, iteration
Обучать сеть на одном примере за раз (SGD) — шумно, на всём датасете сразу (batch GD) — медленно и не помещается в GPU. Компромисс — mini-batch gradient descent: берём порцию данных (батч), считаем loss и градиенты по нему, обновляем веса. Потом берём следующую порцию.
Терминология: • Batch size — сколько примеров в одной порции. Типичные значения: 32, 64, 128, 256. Больше — стабильнее градиенты, но больше GPU-памяти. • Iteration (шаг) — одно обновление весов (один батч прошёл через forward + backward + update). • Epoch (эпоха) — один полный проход по всему датасету. Если в датасете 10 000 примеров и batch size = 100, то 1 эпоха = 100 итераций. • Обучение обычно занимает 3–100 эпох. Правило: если val_loss перестал падать — хватит.
Как batch size влияет на обучение: • Маленький batch (32-64) — шумные градиенты, сеть «прыгает». Но шум действует как регуляризатор — модель лучше обобщает. Больше итераций за эпоху. • Большой batch (512-4096) — гладкие градиенты, стабильное обучение. Но нужен больший learning rate (линейное масштабирование + warmup). Риск застрять в «острых» минимумах с плохой генерализацией. • На практике: начинай с batch_size = 64 или 128. Увеличивай, если GPU позволяет.
Переобучение — главный враг нейросетей
Нейросеть с миллионами параметров может запомнить обучающую выборку вместо того, чтобы выучить закономерности. Это переобучение (overfitting): train loss падает, а val loss (на данных, которых сеть не видела) — растёт. Модель выучила шум в данных.
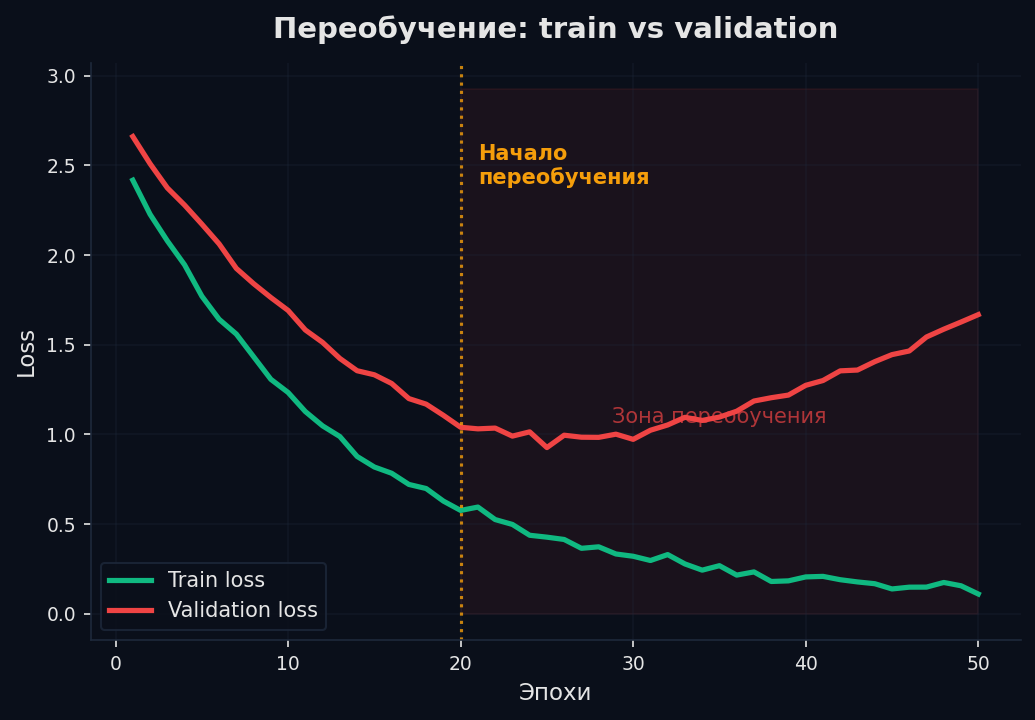
Методы борьбы: • Dropout (p = 0.1–0.5) — при обучении случайно «выключаем» нейроны. Каждый нейрон вынужден быть полезным сам по себе, а не полагаться на соседей. Математически — ансамбль 2ⁿ подсетей. При инференсе dropout выключается, выходы масштабируются. • Early Stopping — следим за val_loss. Если он не улучшается K эпох подряд (patience) — останавливаем обучение и берём веса с лучшей эпохи. Самый простой и надёжный метод. • Weight Decay (L2) — штраф за большие веса: loss = loss_original + λ·Σwᵢ². Заставляет сеть использовать маленькие веса → более гладкие функции → лучшая генерализация. В AdamW weight decay реализован корректно. • Data Augmentation — искусственно увеличиваем датасет. Для картинок: повороты, отражения, кропы, цветовые искажения. Для текста: back-translation, synonym replacement, random deletion. • Больше данных — лучшая регуляризация. Если можешь собрать больше данных — делай это прежде, чем крутить гиперпараметры.

Практика: классификация MNIST — полный пример
Соберём всё вместе: MLP, ReLU, Cross-Entropy, Adam, Dropout — и обучим модель распознавать рукописные цифры (MNIST: 28×28 пикселей → одна из 10 цифр).
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 1. Данные — MNIST, 60K train + 10K test
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_data = datasets.MNIST('data', train=True, download=True, transform=transform)
test_data = datasets.MNIST('data', train=False, transform=transform)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=256)
# 2. Модель — MLP: 784 → 256 → 128 → 10
model = nn.Sequential(
nn.Flatten(), # 28×28 → 784
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.2), # регуляризация
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(128, 10) # 10 классов (logits, без softmax!)
)
# 3. Loss + Optimizer
criterion = nn.CrossEntropyLoss() # внутри softmax + NLL
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 4. Training loop
for epoch in range(10):
model.train() # включаем dropout
for x_batch, y_batch in train_loader:
logits = model(x_batch) # forward
loss = criterion(logits, y_batch) # loss
optimizer.zero_grad() # обнуляем градиенты
loss.backward() # backward (backprop)
optimizer.step() # update weights
# Validation
model.eval() # выключаем dropout
correct = 0
with torch.no_grad():
for x, y in test_loader:
correct += (model(x).argmax(1) == y).sum().item()
print(f"Epoch {epoch+1}: accuracy = {correct / len(test_data):.2%}")
# → ~98% accuracy за 10 эпох. CNN даст 99.5%+, но MLP — отличный стартЧто важно в этом коде
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Нейросеть — это параметрическая функция, которая учит представления данных (а не работает с ручными признаками). Один нейрон = линейная комбинация + нелинейная активация. Много нейронов в слоях = MLP, способный аппроксимировать что угодно. Обучение: forward pass → loss → backprop → update weights, повторить тысячи раз на mini-batch'ах.
Критичные решения при проектировании: активация (ReLU для скрытых, softmax для классификации), loss (MSE для регрессии, CE для классификации), регуляризация (dropout + early stopping + weight decay). Если запомнить одну вещь — нейросеть без нелинейной активации = линейная регрессия, сколько бы слоёв ни было.
Дальше: Backpropagation — как именно вычисляются градиенты (chain rule, граф вычислений, полный числовой пример). Model Selection — как выбирать гиперпараметры и бороться с переобучением систематически.
Материалы
Лучшая визуализация: что делает каждый нейрон, как сеть учится. Обязательно к просмотру.
Быстрый старт: тензоры, autograd, первая нейросеть на PyTorch.
Практический курс на русском: от перцептрона до свёрточных сетей.
Конспекты Андрея Карпати: backprop, optimization, CNN. Золотой стандарт объяснений.
Фундаментальный учебник. Главы 6-8 — полносвязные сети, регуляризация, оптимизация.