Валидация и подбор моделей
Cross-validation, гиперпараметры, bias-variance trade-off, Optuna.
Выбор модели — не по хайпу, а по задаче
Загрузка интерактивного виджета...
Ты обучил модель, accuracy на тренировочных данных — 0.99. Радоваться? Нет. Модель могла просто запомнить данные вместо того, чтобы научиться обобщать. Вопрос «какую модель выбрать?» — это не про «что сейчас модно», а про системный процесс: как честно оценить качество, как не обмануть себя, и как выжать максимум из данных.
В этой ноде — полный путь от «у меня есть данные и задача» до «я уверен, что выбрал лучшую модель». Кросс-валидация, bias-variance tradeoff, подбор гиперпараметров, метрики, ансамбли — всё это звенья одной цепи. Разберём каждое.
Большая картина: от задачи к финальной модели
Выбор модели — это не «попробовал три алгоритма, взял лучший». Это итеративный процесс из пяти шагов:
Шаг 1. Пойми задачу. Что предсказываем? Какая метрика важна бизнесу? Классификация (спам/не спам) или регрессия (цена)? Есть ли дисбаланс классов? Сколько данных? Какие ограничения по latency? Шаг 2. Подготовь данные. Разбей на train/val/test. Сделай feature engineering. Проверь утечки данных (data leakage). Шаг 3. Baseline. Начни с простой модели: логистическая регрессия или Random Forest. Это твоя нижняя планка — если сложная модель не лучше baseline, она не нужна. Шаг 4. Эксперименты. Пробуй разные алгоритмы (бустинг, SVM, нейросети). Подбирай гиперпараметры. Оценивай через кросс-валидацию. Сравнивай не одну цифру, а среднее ± std. Шаг 5. Финальная оценка. Лучшую модель оцени на тестовом наборе ровно один раз. Это твоя честная оценка качества в продакшне.
Главное правило
Train / Validation / Test — зачем три набора
Аналогия: подготовка к экзамену. Train — задачи из учебника, по которым ты учишься. Validation — пробный экзамен для самопроверки (можно решать многократно, менять стратегию подготовки). Test — настоящий экзамен, который ты видишь только один раз.
- Train (60–80%) — модель учится на этих данных. Подбирает веса, пороги, коэффициенты.
- Validation (10–20%) — сравниваешь модели, подбираешь гиперпараметры. Можно смотреть многократно.
- Test (10–20%) — финальная оценка. Смотришь ОДИН раз в самом конце. Никаких решений на его основе.
from sklearn.model_selection import train_test_split
# Сначала отделяем тест (20%) — и забываем про него
X_trainval, X_test, y_trainval, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Из оставшегося — train (75%) и val (25%) → итого 60/20/20
X_train, X_val, y_train, y_val = train_test_split(
X_trainval, y_trainval, test_size=0.25, random_state=42, stratify=y_trainval
)Data leakage — главный враг честной оценки
Data leakage (утечка данных) — когда информация из валидации/теста «просачивается» в обучение. Модель показывает отличные метрики, но в продакшне разваливается. Типичные утечки:
• Нормализация до split: посчитал mean/std на всех данных, включая тест → модель «знает» статистики тестовых данных. Правильно: fit scaler только на train, transform на val/test. • Target encoding до split: закодировал категории средним y по всему датасету → утечка целевой переменной. • Временные данные в перемешке: обучил на данных за декабрь, тестируешь на ноябре → модель «видела будущее». • Дубликаты в разных наборах: один и тот же пользователь попал и в train, и в test → модель его просто запомнила.
Кросс-валидация — надёжная оценка без потери данных
Один split на train/val — это одна случайная выборка. Метрика зависит от того, какие объекты попали в val. Повезло — высокая, не повезло — низкая. Кросс-валидация решает эту проблему: каждый объект побывает и в обучении, и в проверке.

K-Fold: базовый подход
Делишь данные на K равных частей (фолдов). K раз обучаешь модель — каждый раз один фолд тестовый, остальные K−1 обучающие. Итог — K значений метрики. Отчитываешься средним ± стандартным отклонением. Обычно K = 5 или K = 10.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5, scoring='roc_auc')
print(f"AUC: {scores.mean():.3f} ± {scores.std():.3f}")
# AUC: 0.847 ± 0.023 ← среднее и разброс по 5 фолдамМаленький std (0.02) — модель стабильна. Большой std (0.10) — результат сильно зависит от разбиения, нужно разбираться (мало данных? выбросы? нестабильный алгоритм?).
Stratified K-Fold: для несбалансированных классов
Если классы несбалансированы (например, 5% мошеннических транзакций), обычный K-Fold может случайно создать фолд вообще без положительных примеров. StratifiedKFold сохраняет пропорцию классов в каждом фолде. Для задач классификации — используй всегда.
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=skf, scoring='f1')
print(f"F1: {scores.mean():.3f} ± {scores.std():.3f}")Time Series Split: нельзя заглядывать в будущее
Для временных рядов обычный K-Fold запрещён. Если перемешать данные, модель «увидит» будущее через фолды. TimeSeriesSplit гарантирует: обучение всегда на прошлом, валидация — на будущем.
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=5)
# Фолд 1: train=[янв-мар], val=[апр]
# Фолд 2: train=[янв-апр], val=[май]
# Фолд 3: train=[янв-май], val=[июн] ...и так далее
scores = cross_val_score(model, X, y, cv=tscv, scoring='neg_mean_squared_error')Bias-Variance Tradeoff — почему модель ошибается
Любая ошибка модели раскладывается на три компонента: bias (смещение), variance (разброс) и irreducible error (шум в данных, который не убрать). Понимание этого — ключ к тому, что именно чинить.
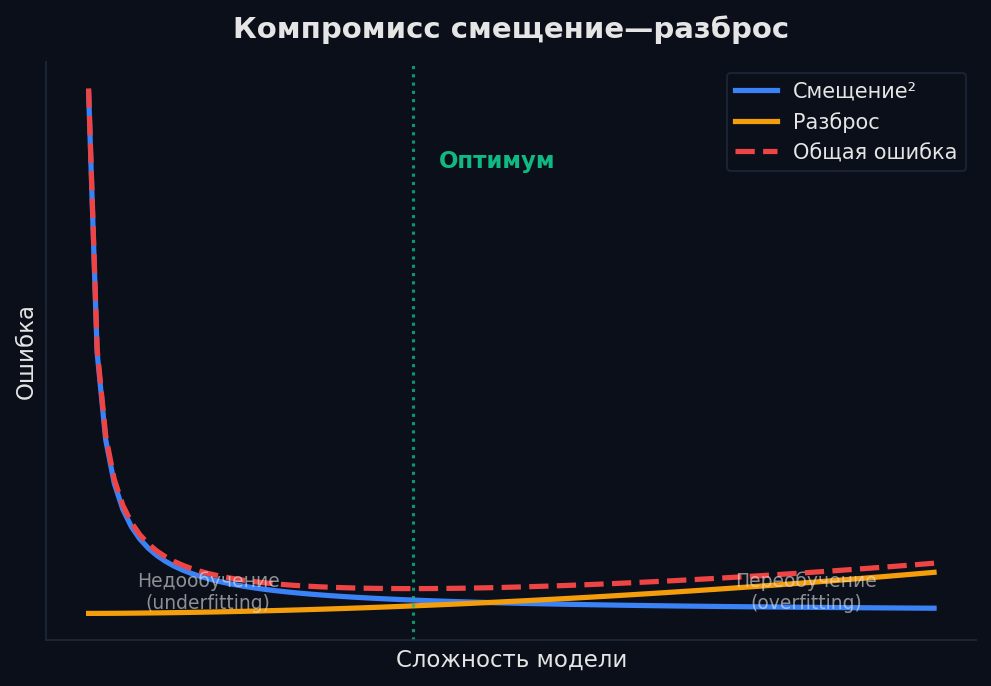
High bias (недообучение): модель слишком простая, не улавливает закономерности. Линейная регрессия на нелинейных данных. Train loss высокий, val loss высокий — обе метрики плохие. High variance (переобучение): модель слишком сложная, запоминает шум. Дерево глубиной 100 на 50 объектах. Train loss низкий, val loss высокий — огромный разрыв.
Аналогия с мишенью: bias — это когда ты стабильно стреляешь мимо центра (систематическая ошибка). Variance — когда попадания разбросаны по всей мишени (нестабильность). Идеал — кучно и в центре.
Кривые обучения — диагностика на глаз
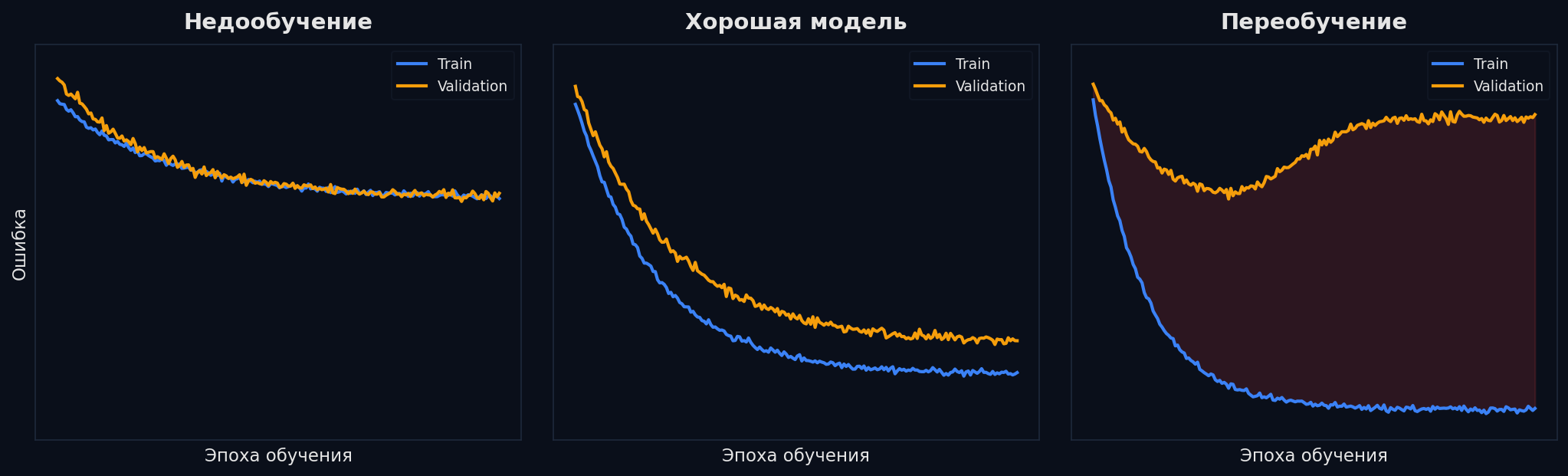
Кривые обучения — графики loss на train и validation по эпохам. Три паттерна: 1. Обе кривые высоко и рядом → underfitting. Модель слишком простая. Решение: усложни модель, добавь фичи, уменьши регуляризацию. 2. Обе низко и рядом → всё хорошо, модель обобщает. 3. Train падает, val растёт → overfitting. Модель запоминает шум. Решение: регуляризация, early stopping, больше данных, dropout.
Как бороться с переобучением
• Регуляризация — штраф за сложность модели. L1 (Lasso): зануляет «лишние» веса. L2 (Ridge): уменьшает все веса. Для бустинга: ограничение глубины, min_samples_leaf, L1/L2 на листья. • Early stopping — следишь за val loss и останавливаешь обучение, когда он перестаёт падать. Просто и эффективно. • Dropout (для нейросетей) — случайно «выключаешь» нейроны при обучении, заставляя сеть не полагаться на одну фичу. • Больше данных — самый надёжный способ. Модель не может запомнить миллион объектов так же легко, как тысячу. • Data augmentation — искусственное увеличение выборки (повороты/обрезки для картинок, парафразы для текста).
Подбор гиперпараметров — Grid, Random, Bayesian
Гиперпараметры — это настройки, которые ты задаёшь до обучения: глубина дерева, learning rate, число деревьев, коэффициент регуляризации. Модель не учит их сама — их подбираешь ты. Вручную — долго и ненадёжно. Автоматически — три подхода:
Grid Search — перебор всех комбинаций значений. Задаёшь сетку: depth ∈ {3, 5, 7}, lr ∈ {0.01, 0.05, 0.1} → 3 × 3 = 9 экспериментов. Плюс: гарантированно найдёт лучшую из сетки. Минус: экспоненциальный рост при добавлении параметров. 5 параметров по 5 значений = 3125 экспериментов. Random Search — случайно выбирает комбинации из заданных диапазонов. При 60 случайных итерациях с высокой вероятностью попадёшь близко к оптимуму. Исследование Bergstra & Bengio (2012) показало: Random Search за то же время часто находит лучшие параметры, чем Grid, потому что «исследует» каждое измерение более плотно. Bayesian Optimization (Optuna) — умный поиск. Строит вероятностную модель «какие параметры дают хорошие результаты» и выбирает следующую точку осознанно. Не тратит время на заведомо плохие области. Лучший выбор, когда одна итерация дорогая (минуты обучения).
import optuna
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
def objective(trial):
params = {
'n_estimators': trial.suggest_int('n_estimators', 50, 500),
'max_depth': trial.suggest_int('max_depth', 3, 10),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.3, log=True),
'subsample': trial.suggest_float('subsample', 0.5, 1.0),
}
model = GradientBoostingClassifier(**params, random_state=42)
scores = cross_val_score(model, X_train, y_train, cv=5, scoring='roc_auc')
return scores.mean()
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
print(f"Лучший AUC: {study.best_value:.3f}")
print(f"Лучшие параметры: {study.best_params}")Nested CV — честная оценка с подбором
Метрики — что именно оптимизировать
Выбор метрики — это бизнес-решение, а не техническое. Одна и та же модель может быть лучшей по accuracy и худшей по recall. Какую метрику оптимизировать — зависит от цены ошибки.
Accuracy — доля правильных ответов. Проста и понятна, но обманчива на несбалансированных данных. При 99% негативных и 1% позитивных модель, предсказывающая «всегда нет», имеет accuracy = 99%. Precision — из тех, кого модель назвала положительными, какая доля реально положительные? Важна, когда false positive дорого стоит (спам-фильтр: лучше пропустить спам, чем удалить важное письмо). Recall — из всех реально положительных, какую долю модель нашла? Важен, когда false negative опасен (диагностика рака: пропустить больного хуже, чем направить здорового на доп. обследование). F1-score — гармоническое среднее precision и recall. Компромисс, когда оба важны. ROC-AUC — площадь под ROC-кривой. Оценивает способность модели ранжировать (отделять положительные от отрицательных). Не зависит от порога. Хорош для сравнения моделей.
Метрики регрессии: • MSE — средний квадрат ошибки. Штрафует большие ошибки сильнее. Чувствителен к выбросам. • MAE — средний модуль ошибки. Устойчив к выбросам, но не дифференцируем в нуле. • R² — доля объяснённой дисперсии. 1.0 = идеально, 0.0 = модель не лучше среднего. • MAPE — средняя процентная ошибка. Удобен, когда масштаб данных варьируется.
Бизнес-контекст решает
Ансамбли — когда одна модель недостаточно
Ансамбль — это комбинация нескольких моделей, которая обычно работает лучше любой из них по отдельности. Три главных подхода:
Bagging: снижаем variance
Обучаем независимые модели на разных подвыборках данных (bootstrap), усредняем ответы. Ошибки отдельных моделей «гасят» друг друга. Классический пример — Random Forest (бэггинг деревьев). Снижает variance, не трогая bias. Работает, когда базовая модель нестабильна (глубокие деревья).
Boosting: снижаем bias
Обучаем модели последовательно: каждая следующая фокусируется на ошибках предыдущих. Начинаем с простой модели (high bias), пошагово уменьшаем ошибку. XGBoost, LightGBM, CatBoost — всё это бустинг. Доминирует на табличных данных. Подробнее — в ноде Классический ML.
Stacking: учимся комбинировать
Обучаем несколько разнородных моделей (логрег, бустинг, kNN, SVM). Их предсказания подаём как фичи в метамодель (обычно логистическую регрессию), которая учится оптимально комбинировать ответы. Stacking даёт +0.5–1% к качеству поверх лучшей модели — немного, но на Kaggle это разница между золотом и серебром.
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
stack = StackingClassifier(
estimators=[
('rf', RandomForestClassifier(n_estimators=100)),
('gb', GradientBoostingClassifier(n_estimators=200)),
('svm', SVC(probability=True)),
],
final_estimator=LogisticRegression(),
cv=5, # предсказания базовых моделей через CV (без утечки)
)
stack.fit(X_train, y_train)
print(f"Stacking AUC: {stack.score(X_test, y_test):.3f}")Когда что использовать: • Bagging (RF): нестабильные модели, нужна устойчивость, данные шумные. • Boosting (XGBoost/CatBoost): таблицы, нужно максимальное качество, готов тюнить гиперпараметры. • Stacking: соревнования, когда 0.1% имеет значение. В продакшне — редко (сложность поддержки). • Простое голосование / усреднение: когда есть 2–3 готовые модели и нет времени на stacking.
Собираем всё вместе
Выбор модели — это не про «XGBoost или LightGBM?». Это системный процесс: разбей данные честно (train/val/test, stratify, без утечек) → оцени надёжно (кросс-валидация, среднее ± std) → пойми, что чинить (bias-variance, learning curves) → подбери параметры (Optuna > Random > Grid) → выбери метрику по бизнесу (не accuracy по умолчанию).
Если запомнить одну вещь: не доверяй одной цифре. Модель с AUC 0.85 ± 0.02 надёжнее, чем модель с AUC 0.87 ± 0.10. Стабильность важнее пикового результата.
🎯 На собеседовании
Junior
Middle
Senior
Материалы
Подробный разбор всех видов кросс-валидации с примерами на Python.
Официальная документация: K-Fold, Stratified, TimeSeriesSplit, GroupKFold.
Быстрый старт с Optuna: от define-by-run до pruning неудачных экспериментов.
Визуальное объяснение bias-variance tradeoff — одно из лучших на YouTube.
K-Fold, Leave-One-Out и зачем это нужно — просто и наглядно.
Cross-validation, hyperparameter tuning, bias-variance — с математикой и кодом.