Backpropagation
Chain rule, граф вычислений, forward/backward pass, vanishing gradients — как нейросети учатся.
Backpropagation — как нейросети учатся на своих ошибках
Загрузка интерактивного виджета...
Нейросеть — это миллионы настраиваемых чисел (весов). Когда ты создаёшь сеть, её веса случайные — она предсказывает полную ерунду. Как превратить эту случайную конструкцию в полезную модель? Нужен способ понять, какой именно вес виноват в ошибке и в какую сторону его подкрутить.
Backpropagation (обратное распространение ошибки) — это алгоритм, который решает именно эту задачу. Он вычисляет, как каждый из миллионов весов влияет на итоговую ошибку сети. Без backprop глубокое обучение невозможно — именно этот алгоритм сделал нейросети практичными.
Аналогия: представь оркестр из 100 музыкантов. После концерта дирижёр слышит, что звучало фальшиво. Ему нужно понять: кто именно сфальшивил и насколько? Backprop — это «идеальный слух» дирижёра: он разбирает общую ошибку на вклад каждого музыканта и говорит каждому, что исправить.
Большая картина: цикл обучения нейросети
Прежде чем разбирать backprop по частям, посмотрим на весь цикл обучения. Он состоит из четырёх шагов, которые повторяются тысячи раз:
Шаг 1. Forward pass (прямой проход). Данные проходят через сеть слева направо: вход → слой 1 → слой 2 → … → предсказание. Каждый слой применяет свои веса и функцию активации. На выходе — предсказание ŷ. Шаг 2. Вычисление loss (ошибки). Сравниваем предсказание ŷ с правильным ответом y. Функция потерь (loss function) выдаёт одно число — насколько мы ошиблись. Чем меньше loss — тем лучше. Шаг 3. Backward pass (обратный проход). Вот тут работает backpropagation. Градиент ошибки «течёт» обратно: от loss через все слои до первого. Для каждого веса вычисляется ∂L/∂w — как этот конкретный вес влияет на ошибку. Шаг 4. Update weights (обновление весов). Оптимизатор сдвигает каждый вес в направлении, уменьшающем ошибку: w_new = w_old − lr · ∂L/∂w. Маленький шажок по градиенту — и сеть стала чуть лучше.
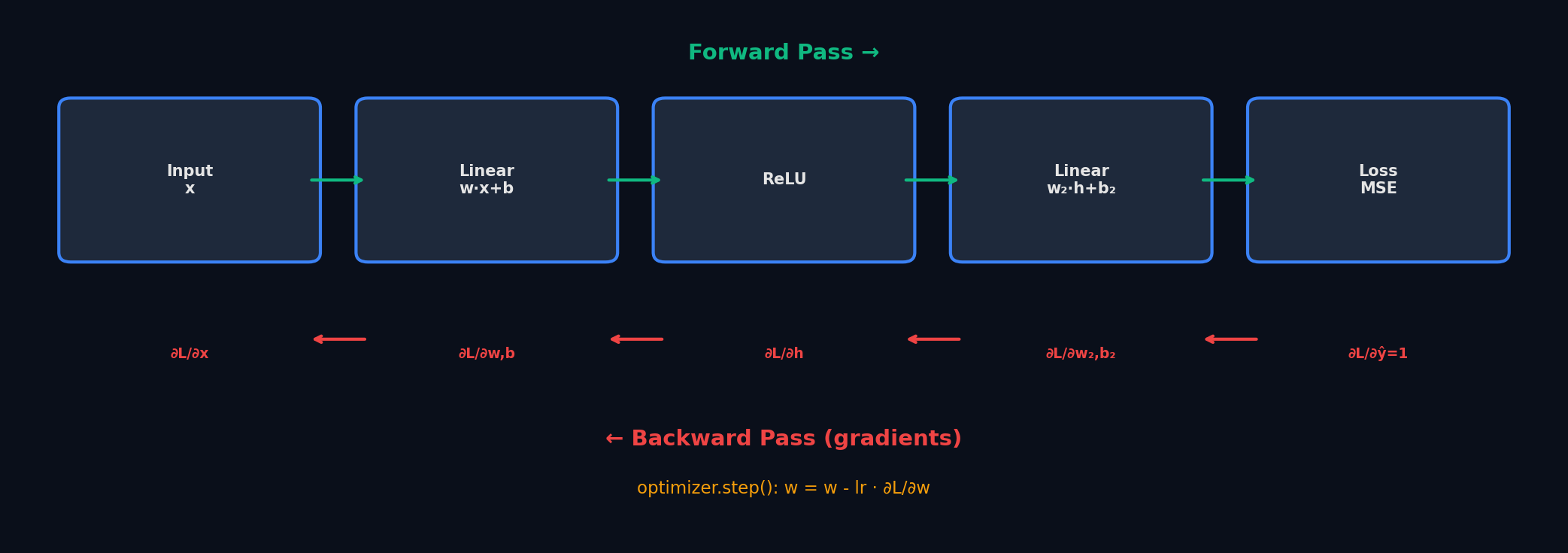
Ключевая идея
Chain Rule — математический фундамент backprop
Нейросеть — это цепочка вложенных функций: вход → слой 1 → слой 2 → loss. Чтобы узнать, как вес первого слоя влияет на loss, нужно «раскрутить» всю цепочку. Для этого используется chain rule (цепное правило дифференцирования) — математическое правило для производной сложной функции.
Аналогия: ты крутишь руль → колёса поворачивают → машина меняет направление. Если хочешь узнать, как поворот руля влияет на направление — перемножь все промежуточные влияния. Повернул руль на 10° → колёса на 5° → машина на 2°. Итого: каждый градус руля = 0.2° направления. Это и есть chain rule — произведение «локальных» влияний вдоль цепочки.
∂L/∂w — градиент loss по весу (то, что мы ищем), ∂L/∂y, ∂y/∂z, ∂z/∂w — локальные градиенты на каждом участке цепочки. Умножаем их все — получаем итоговое влияние
Пример на числах. Пусть z = 3w, y = z + 2, L = y². При w = 1: Forward: z = 3·1 = 3, y = 3 + 2 = 5, L = 5² = 25. Backward (справа налево): ∂L/∂y = 2y = 10, ∂y/∂z = 1, ∂z/∂w = 3. Итого: ∂L/∂w = 10 · 1 · 3 = 30. Значит, если увеличить w на 0.01, loss вырастет примерно на 0.3.
Граф вычислений — как нейросеть видит backprop
Любое вычисление в нейросети можно представить как направленный граф. Узлы — операции (умножение, сложение, ReLU, softmax). Рёбра — данные (тензоры). Forward pass идёт «вперёд» по графу, backward pass — «назад». Каждый узел знает два правила: как вычислить выход из входов (forward) и как вычислить градиент входов из градиента выхода (backward).
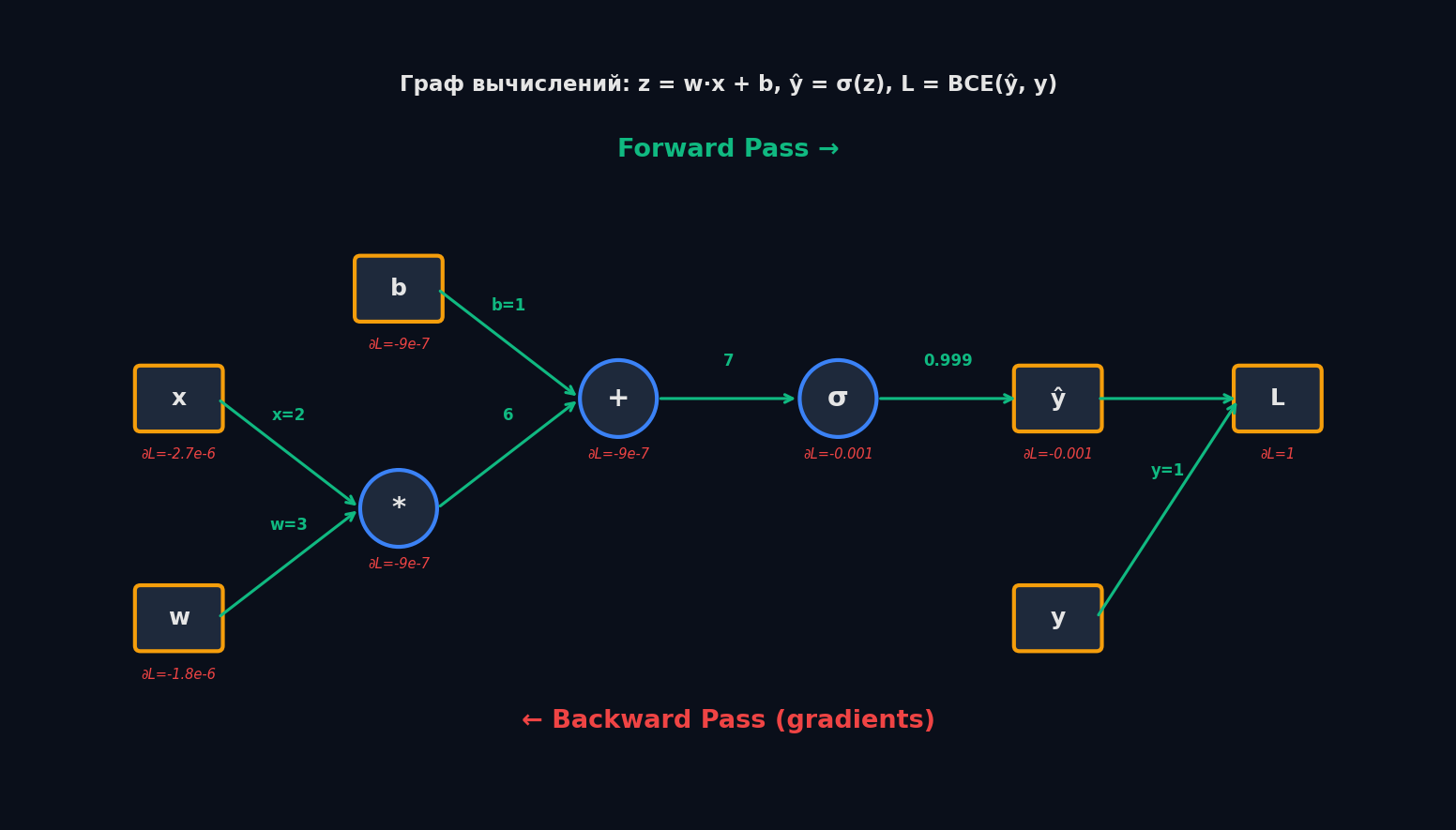
PyTorch строит граф вычислений на лету (dynamic computation graph). Каждая операция с тензором, у которого requires_grad=True, автоматически записывается. При вызове loss.backward() PyTorch проходит по графу в обратном порядке и вычисляет все градиенты — это и есть autograd.
End-to-end пример: сеть из 3 нейронов, все числа
Теория понятнее на конкретных числах. Разберём полностью: сеть, forward, loss, backward, обновление весов.
Архитектура: вход x = 1.0, скрытый слой из 2 нейронов (без bias, активация ReLU), выходной слой из 1 нейрона (без bias, без активации). Веса: • w₁ = 0.5 (вход → скрытый нейрон 1) • w₂ = −0.3 (вход → скрытый нейрон 2) • w₃ = 0.8 (скрытый 1 → выход) • w₄ = 0.2 (скрытый 2 → выход) Цель: target = 1.0. Loss = MSE = (ŷ − target)².
Forward pass (считаем предсказание): 1. Скрытый нейрон 1: z₁ = w₁ · x = 0.5 · 1.0 = 0.5 → ReLU(0.5) = h₁ = 0.5 2. Скрытый нейрон 2: z₂ = w₂ · x = −0.3 · 1.0 = −0.3 → ReLU(−0.3) = h₂ = 0.0 (ReLU обрезал!) 3. Выход: ŷ = w₃ · h₁ + w₄ · h₂ = 0.8 · 0.5 + 0.2 · 0.0 = 0.4 4. Loss: L = (0.4 − 1.0)² = (−0.6)² = 0.36
Backward pass (вычисляем градиенты от loss к весам): 1. ∂L/∂ŷ = 2(ŷ − target) = 2(0.4 − 1.0) = −1.2 (loss падает, если ŷ растёт) 2. Градиенты выходного слоя: — ∂L/∂w₃ = ∂L/∂ŷ · h₁ = −1.2 · 0.5 = −0.6 — ∂L/∂w₄ = ∂L/∂ŷ · h₂ = −1.2 · 0.0 = 0.0 (h₂ = 0, вес w₄ «не виноват») 3. Градиенты скрытого слоя (через chain rule): — ∂L/∂h₁ = ∂L/∂ŷ · w₃ = −1.2 · 0.8 = −0.96 — ∂L/∂z₁ = ∂L/∂h₁ · ReLU'(z₁) = −0.96 · 1 = −0.96 (z₁ > 0, ReLU не обрезает) — ∂L/∂w₁ = ∂L/∂z₁ · x = −0.96 · 1.0 = −0.96 — ∂L/∂h₂ = ∂L/∂ŷ · w₄ = −1.2 · 0.2 = −0.24 — ∂L/∂z₂ = ∂L/∂h₂ · ReLU'(z₂) = −0.24 · 0 = 0.0 (z₂ < 0 → ReLU'=0 → градиент заблокирован!) — ∂L/∂w₂ = 0.0
Update weights (learning rate = 0.1): • w₁ = 0.5 − 0.1·(−0.96) = 0.5 + 0.096 = 0.596 ✅ (увеличили — loss упадёт) • w₂ = −0.3 − 0.1·(0.0) = −0.3 ❌ (не изменился — ReLU заблокировал градиент) • w₃ = 0.8 − 0.1·(−0.6) = 0.8 + 0.06 = 0.86 ✅ • w₄ = 0.2 − 0.1·(0.0) = 0.2 ❌ (h₂ = 0 → вес не обновился) Обрати внимание: w₂ не обновился из-за ReLU (нейрон «мёртв», z₂ < 0). Это dead ReLU problem — мы вернёмся к ней ниже.
Что этот пример показывает
PyTorch Autograd — backprop на автопилоте
На практике никто не вычисляет градиенты вручную. PyTorch делает это автоматически — достаточно вызвать loss.backward(). Проверим наш пример:
import torch
# Наша маленькая сеть
x = torch.tensor([1.0])
target = torch.tensor([1.0])
w1 = torch.tensor([0.5], requires_grad=True)
w2 = torch.tensor([-0.3], requires_grad=True)
w3 = torch.tensor([0.8], requires_grad=True)
w4 = torch.tensor([0.2], requires_grad=True)
# Forward pass
h1 = torch.relu(w1 * x) # 0.5
h2 = torch.relu(w2 * x) # 0.0 (ReLU обрезал)
y_hat = w3 * h1 + w4 * h2 # 0.4
loss = (y_hat - target) ** 2 # 0.36
# Backward pass — одна строка!
loss.backward()
print(f"∂L/∂w1 = {w1.grad.item():.4f}") # -0.9600 ✓
print(f"∂L/∂w2 = {w2.grad.item():.4f}") # 0.0000 ✓ (dead ReLU)
print(f"∂L/∂w3 = {w3.grad.item():.4f}") # -0.6000 ✓
print(f"∂L/∂w4 = {w4.grad.item():.4f}") # 0.0000 ✓ (h2 = 0)# Реальный training loop — как это выглядит на практике
import torch.nn as nn
model = nn.Sequential(nn.Linear(10, 32), nn.ReLU(), nn.Linear(32, 1))
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for x_batch, y_batch in dataloader:
y_hat = model(x_batch) # forward
loss = nn.functional.mse_loss(y_hat, y_batch) # loss
optimizer.zero_grad() # ← обнуляем старые градиенты!
loss.backward() # backward (backprop)
optimizer.step() # update weightsЗачем zero_grad()?
.backward() прибавляет новые градиенты к старым. Это нужно для некоторых трюков (gradient accumulation для больших батчей), но обычно перед каждым backward надо обнулить: optimizer.zero_grad(). Забудешь — градиенты будут расти и модель не сойдётся.Vanishing и Exploding Gradients — почему глубокие сети сложно обучать
Chain rule — это произведение локальных градиентов. Если в сети 50 слоёв, градиент — произведение 50 множителей. Что произойдёт?
Vanishing gradients (затухание). Если локальные градиенты < 1 (а у sigmoid максимальный градиент = 0.25), то при 50 слоях: 0.25^50 ≈ 10⁻³⁰. Градиент первых слоёв — практически ноль. Они не учатся. Это главная причина, почему глубокие сети с sigmoid не работали до 2012 года.
Exploding gradients (взрыв). Обратная ситуация: если множители > 1, при 50 слоях число улетает в бесконечность. Веса начинают «прыгать» хаотично, loss уходит в NaN.
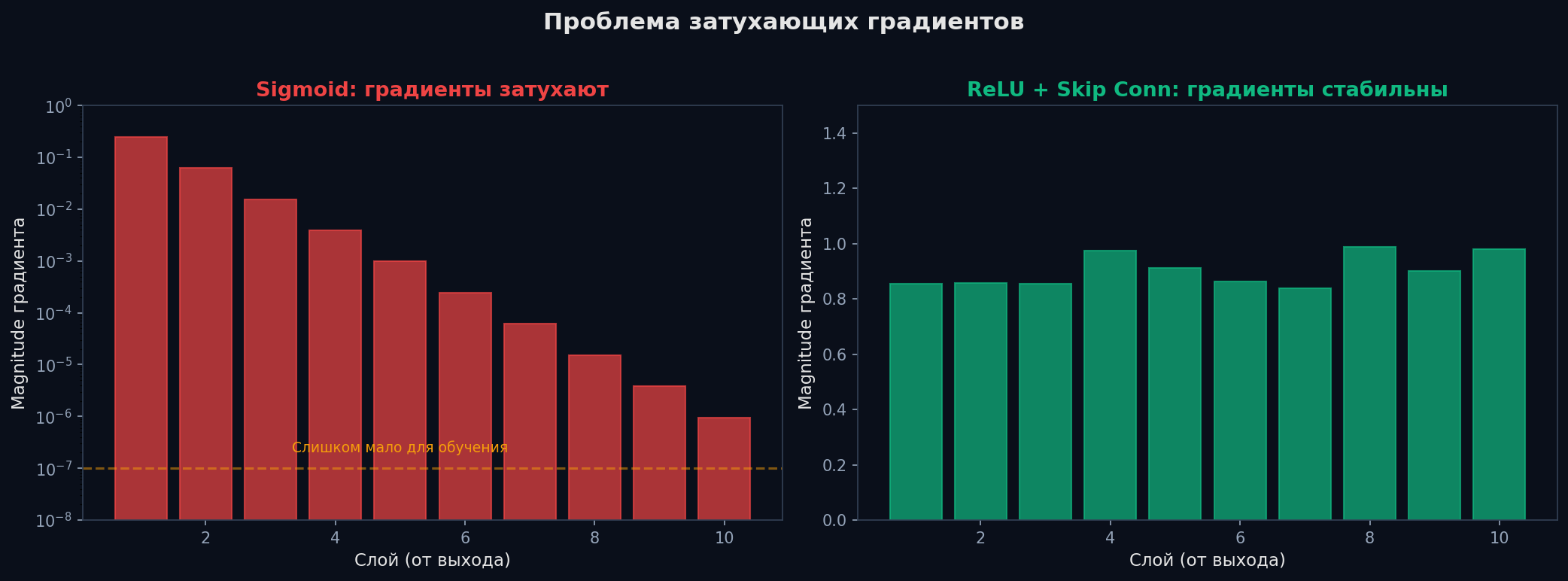
Решения: • ReLU вместо sigmoid/tanh — градиент = 1 при x > 0 (не затухает). Простое изменение, которое «разблокировало» глубокое обучение. • Skip connections (ResNet, 2015) — градиент «пролетает» мимо слоёв напрямую: output = F(x) + x. Даже если F(x) даёт нулевой градиент, через «+x» градиент проходит без потерь. • Proper initialization — He init для ReLU, Xavier для tanh. Правильная дисперсия начальных весов предотвращает затухание/взрыв с первого шага. • Gradient clipping — обрезаем норму градиента: если ||g|| > threshold, масштабируем g. Стандартная защита от взрыва в RNN и LLM. • BatchNorm / LayerNorm — нормализация активаций между слоями стабилизирует распределение и косвенно помогает градиентам.
Dead ReLU problem
Оптимизаторы: SGD → Momentum → Adam
Backprop вычисляет градиенты, но оптимизатор решает, как именно обновлять веса. Эволюция оптимизаторов — от простого к умному:
SGD (Stochastic Gradient Descent) — самый простой: w = w − lr · g. Шаг пропорционален градиенту. Проблема: на «узких оврагах» loss-ландшафта SGD осциллирует (прыгает от стенки к стенке), вместо того чтобы идти по дну оврага к минимуму.
SGD + Momentum — добавляем «инерцию». Вместо чистого градиента используем скользящее среднее: v = β·v + g, затем w = w − lr·v. Аналогия: мяч катится по оврагу. Momentum гасит осцилляции (вертикальные прыжки усредняются до нуля) и ускоряет движение вдоль оврага (горизонтальные компоненты накапливаются).
Adam (Adaptive Moment Estimation) — стандарт индустрии. Совмещает momentum (скользящее среднее градиента, m) с адаптивным learning rate (скользящее среднее квадрата градиента, v). Для каждого веса свой эффективный lr: параметры с большими градиентами получают маленький lr, с маленькими — большой. Это автоматически решает проблему «разных масштабов».
m — скользящее среднее градиента (momentum), v — скользящее среднее квадрата градиента. β₁=0.9, β₂=0.999 — стандартные. m̂, v̂ — с коррекцией bias. ε=10⁻⁸ — для числовой стабильности
- SGD — простой, но медленный. Нужен тщательный подбор lr. Хорош для fine-tuning и когда важна генерализация
- SGD + Momentum — быстрее SGD, гасит осцилляции. β = 0.9 — стандарт
- Adam — стандарт для большинства задач. Менее чувствителен к выбору lr. Дефолт lr=0.001 работает в 80% случаев
- AdamW — Adam + weight decay (L2 регуляризация), правильно разделённая. Стандарт для трансформеров
Learning rate — самый важный гиперпараметр
Learning rate (lr, скорость обучения) определяет размер шага при обновлении весов. Слишком большой — модель «перепрыгивает» минимум, loss скачет или уходит в NaN. Слишком маленький — обучение идёт месяцами и может застрять в локальном минимуме.
Аналогия: ты спускаешься с горы в тумане. Слишком большие шаги — перепрыгнешь долину и начнёшь подниматься на соседнюю гору. Слишком маленькие — застрянешь в первой же ямке, не дойдя до дна.
Как подбирать lr: • Стартовые точки: Adam — 3e-4 (классика), SGD — 0.01-0.1. Для fine-tuning предобученных моделей — 1e-5 – 5e-5. • LR Finder (Leslie Smith): запусти обучение с экспоненциально растущим lr, построй график loss(lr). Оптимальный lr — чуть левее минимума на графике. • Scheduler (расписание lr): lr не должен быть постоянным! Типичные стратегии: — Warmup: начинаем с маленького lr, линейно растим до целевого за первые 5-10% шагов. Стабилизирует начало обучения. — Cosine decay: после warmup lr плавно убывает по косинусу до ~0. Стандарт для LLM. — Step decay: умножаем lr на 0.1 каждые N эпох. Простой, но работает. — ReduceOnPlateau: уменьшаем lr, если val_loss не падает K эпох. Удобно для экспериментов.
# Warmup + Cosine decay — стандарт для трансформеров
from torch.optim.lr_scheduler import CosineAnnealingLR, LinearLR, SequentialLR
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4, weight_decay=0.01)
warmup = LinearLR(optimizer, start_factor=0.01, total_iters=1000)
cosine = CosineAnnealingLR(optimizer, T_max=50000, eta_min=1e-6)
scheduler = SequentialLR(optimizer, [warmup, cosine], milestones=[1000])
# В training loop:
# optimizer.step()
# scheduler.step()🎯 На собеседовании
Junior
Middle
Senior
torch.nn.utils.clip_grad_norm_(params, max_norm). Считает L2-норму всех градиентов; если > max_norm, масштабирует пропорционально. Стандарт для RNN и LLM (max_norm=1.0).
• Warmup — зачем? В начале обучения Adam ещё не накопил статистику (m, v ≈ 0), оценки моментов шумные. Маленький lr на старте стабилизирует. Без warmup бывают NaN.
• Почему AdamW, а не Adam + L2? В Adam L2-регуляризация «поглощается» адаптивным lr — для параметров с малым градиентом штраф огромен. AdamW вынес weight decay из адаптивного шага, что даёт корректную регуляризацию.Собираем всё вместе
Backpropagation — это алгоритм, который вычисляет градиент loss по каждому весу нейросети, используя chain rule по графу вычислений. Forward pass считает предсказание и сохраняет промежуточные значения. Backward pass «раскручивает» граф в обратном порядке, перемножая локальные градиенты. Оптимизатор (SGD, Adam) использует эти градиенты, чтобы сдвинуть веса в сторону меньшей ошибки.
Главные проблемы — затухание и взрыв градиентов — решаются ReLU, skip connections, proper init и gradient clipping. Learning rate — самый важный гиперпараметр; используй scheduler (warmup + cosine decay для трансформеров).
Если запомнить одну вещь: backprop = chain rule по графу вычислений, от loss к весам. Всё остальное — вариации и оптимизации этой идеи.
Дальше на роадмапе: Deep Learning Basics — архитектуры нейросетей (CNN, RNN, Transformer) и практические приёмы обучения. Model Selection — как понять, что модель переобучена, и как с этим бороться.
Материалы
Лучшая визуализация backpropagation — как градиенты текут через сеть. Обязательно к просмотру.
Подробный разбор backprop с графами вычислений и примерами — Stanford.
Практика: тензоры, графы, автоматическое дифференцирование в PyTorch.
Подробный обзор оптимизаторов от SGD до Adam. Математика + интуиция.
Визуальное объяснение gradient descent — как модель «спускается» к минимуму.