Метрики классификации
Precision, Recall, F1, ROC-AUC, PR-AUC — как оценивать качество моделей.
Метрики классификации — как понять, что модель действительно работает
Загрузка интерактивного виджета...
Ты обучил модель, accuracy = 99%. Хочется праздновать — но подожди. В твоих данных 99% здоровых пациентов и 1% больных. Модель, которая всем говорит «здоров», получает accuracy 99% — и при этом она абсолютно бесполезна. Ни одного больного не нашла.
Это не искусственный пример — дисбаланс классов встречается повсюду: мошеннические транзакции (0.1%), дефекты на производстве (2%), клики по рекламе (1-3%). И accuracy во всех этих случаях врёт: показывает высокое число, скрывая, что модель не справляется с главной задачей.
Вот почему одной метрики мало. Нужен набор инструментов, каждый из которых отвечает на свой вопрос: «Много ли ложных тревог?» (precision), «Не пропускаем ли мы важные случаи?» (recall), «Как модель ведёт себя при разных порогах?» (ROC-AUC). Разберём их все — от фундамента (confusion matrix) до выбора порога под конкретный бизнес.
Confusion Matrix — фундамент всех метрик
Любая метрика классификации начинается с одной таблицы 2×2 — матрицы ошибок (confusion matrix). Она разбивает все предсказания модели на четыре категории по двум осям: «что предсказала модель» и «что было на самом деле».

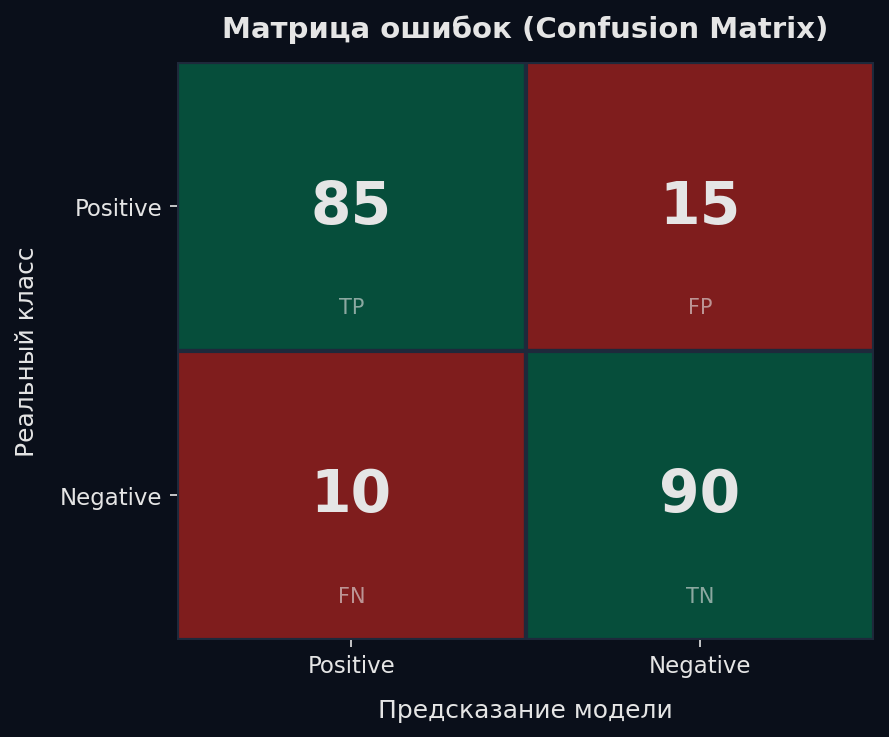
Аналогия: ты охранник на проходной, ищешь воров среди посетителей. • TP (True Positive) — поймал вора. Модель сказала «положительный», и это правда. • TN (True Negative) — пропустил честного. Модель сказала «отрицательный», и это правда. • FP (False Positive) — задержал невиновного. Ложная тревога. Модель ошиблась, назвав здорового больным. • FN (False Negative) — пропустил вора. Самая опасная ошибка. Модель не заметила больного.
Ключевая идея: FP и FN — это два разных типа ошибок, и их цена почти никогда не равна. В медицине пропустить рак (FN) — катастрофа. В спам-фильтре потерять важное письмо (FP) — неприятно. В антифроде обе ошибки стоят денег, но разных. Все метрики ниже — это способы по-разному «взвешивать» эти четыре ячейки.
from sklearn.metrics import confusion_matrix
import numpy as np
y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0]
y_pred = [1, 0, 1, 0, 0, 1, 1, 0, 1, 0]
cm = confusion_matrix(y_true, y_pred)
tn, fp, fn, tp = cm.ravel()
print(f"TP={tp}, TN={tn}, FP={fp}, FN={fn}")
# TP=4, TN=4, FP=1, FN=1Accuracy — простая, но коварная метрика
Accuracy — доля правильных ответов среди всех предсказаний
Accuracy отвечает на вопрос: «Какую долю объектов модель классифицировала правильно?». Самая интуитивная метрика — и самая обманчивая при дисбалансе.
Когда accuracy работает: классы сбалансированы (50/50 или хотя бы 70/30), и оба типа ошибок одинаково важны. Пример: определение пола по фото, классификация отзывов на положительные/отрицательные.
Когда accuracy врёт: дисбаланс классов. Вернёмся к примеру: 10 000 пациентов, 9 900 здоровых и 100 больных. Модель-«оптимист», которая всем ставит «здоров», получает accuracy = 9900/10000 = 99%. При этом recall по больным = 0% — она не нашла ни одного.
Правило большого пальца
Precision и Recall — два взгляда на ошибки
Precision (точность) — из тех, кого модель назвала положительными, сколько действительно положительных? Recall (полнота) — из всех реальных положительных, сколько модель нашла?
Precision и Recall смотрят на ошибки с разных сторон: • Precision штрафует за ложные срабатывания (FP). Высокая precision = мало ложных тревог. • Recall штрафует за пропуски (FN). Высокий recall = мало пропущенных случаев.
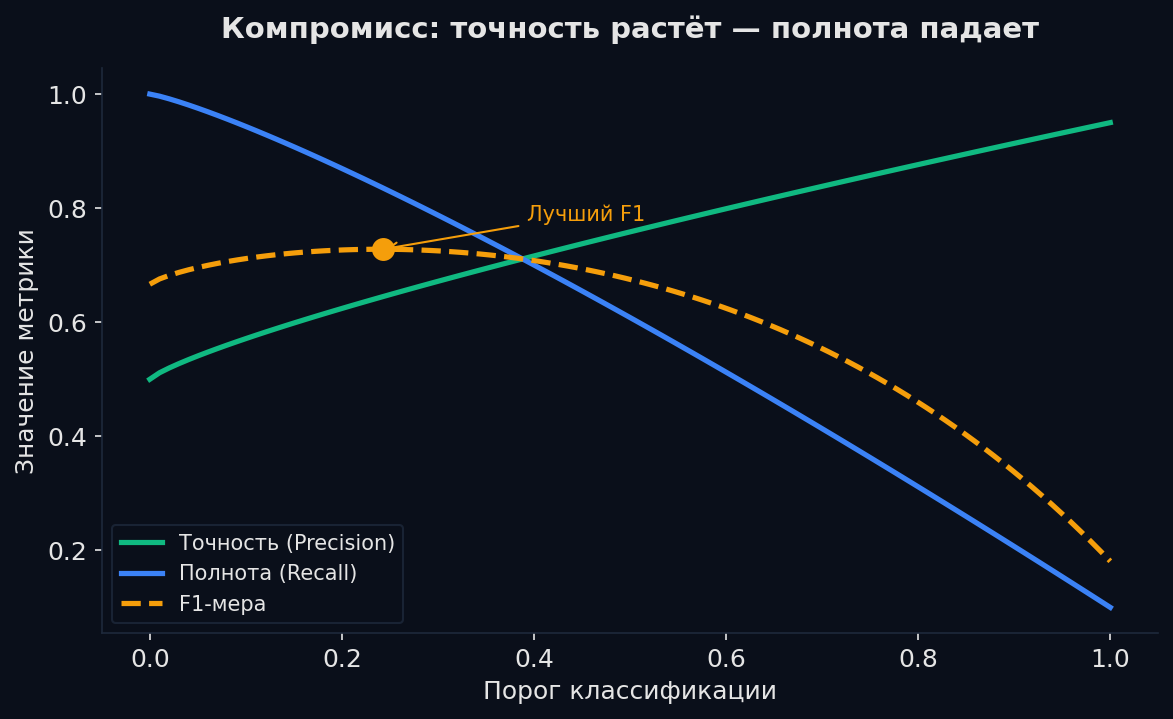
Между ними всегда trade-off через порог (threshold). Модель выдаёт вероятность: P(positive). Если порог 0.5, всё что выше — «положительный». Повышаем порог до 0.9 — модель говорит «положительный» только когда очень уверена → FP падает (precision растёт), но больше случаев пропускает → FN растёт (recall падает). Понижаем порог до 0.1 — наоборот.
Какая метрика важнее — зависит от цены ошибок:
- Спам-фильтр → precision. Отправить важное письмо в спам (FP) — хуже, чем пропустить спам (FN). Пользователь не простит потерянное письмо.
- Диагностика рака → recall. Пропустить больного (FN) — потенциально фатально. Лучше отправить на дополнительное обследование лишних 10 человек (FP), чем пропустить 1 больного.
- Антифрод → баланс. Заблокировать легитимную транзакцию (FP) — потеря клиента. Пропустить мошенника (FN) — финансовые потери. Нужен компромисс.
- Рекомендации → precision@k. Показать неинтересный контент (FP) — раздражает пользователя. Не показать что-то интересное (FN) — менее критично, есть ещё предложения.
from sklearn.metrics import precision_score, recall_score
y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0]
y_pred = [1, 0, 1, 0, 0, 1, 1, 0, 1, 0]
print(f"Precision: {precision_score(y_true, y_pred):.2f}") # 0.80
print(f"Recall: {recall_score(y_true, y_pred):.2f}") # 0.80F1-Score и F-beta — баланс precision и recall
Когда нужна одна метрика, объединяющая precision и recall, используют F1-score — их гармоническое среднее.
F1 — гармоническое среднее precision и recall. Выражается и через TP/FP/FN напрямую
Почему гармоническое, а не арифметическое? Гармоническое среднее сильно штрафует за дисбаланс. Пример: precision = 0.9, recall = 0.1. Арифметическое среднее = 0.5 — звучит нормально. Гармоническое = 0.18 — честно показывает, что одна метрика провалена. F1 высокое только когда обе метрики высокие.
Иногда precision и recall неравнозначны. Для этого есть обобщение — F-beta:
β > 1 — recall важнее (F2 для медицины). β < 1 — precision важнее (F0.5 для спам-фильтров)
- F0.5 — precision вдвое важнее recall. Спам-фильтр: лучше пропустить спам, чем потерять письмо.
- F1 — precision и recall одинаково важны. Дефолтный выбор, когда нет явных предпочтений.
- F2 — recall вдвое важнее precision. Медицинская диагностика: лучше лишнее обследование, чем пропущенная болезнь.
ROC-AUC — как модель разделяет классы при всех порогах
Все предыдущие метрики зависят от выбранного порога. Но что если ты хочешь оценить качество модели в целом, не привязываясь к конкретному threshold? Для этого — ROC-кривая и её площадь AUC.
ROC-кривая (Receiver Operating Characteristic) строится так: 1. Модель выдаёт вероятности для каждого объекта. 2. Перебираем порог от 1 до 0 (от самого строгого к самому мягкому). 3. Для каждого порога вычисляем две величины: — TPR (True Positive Rate) = Recall = TP / (TP + FN) — доля пойманных положительных — FPR (False Positive Rate) = FP / (FP + TN) — доля ошибочно «обвинённых» отрицательных 4. Строим график: по оси X — FPR, по оси Y — TPR.
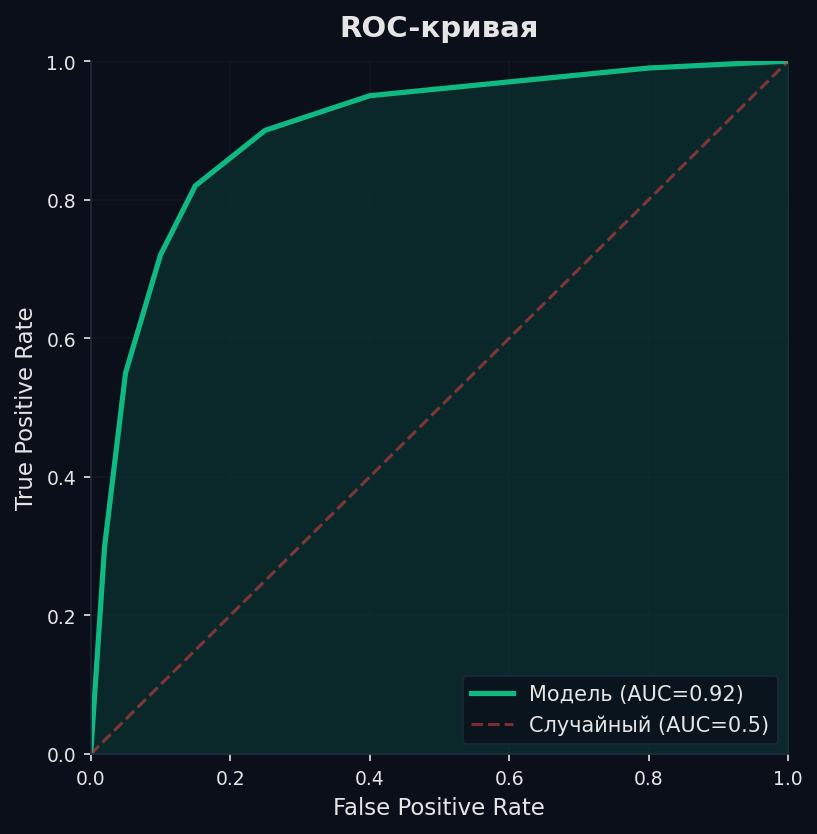
Как читать ROC: • Идеальный классификатор — точка (0, 1): TPR = 1, FPR = 0. Кривая проходит через верхний левый угол. AUC = 1.0. • Случайный классификатор — диагональ из (0,0) в (1,1). AUC = 0.5. Модель не лучше монетки. • Реальная модель — кривая между диагональю и идеалом. Чем выше кривая — тем лучше. • AUC < 0.5 — модель хуже случайного угадывания. Обычно значит, что перепутаны классы.
Интуиция за AUC: ROC-AUC = вероятность того, что модель присвоит случайному положительному объекту более высокий скор, чем случайному отрицательному. AUC = 0.85 означает: в 85% случаев модель корректно ранжирует пару «положительный выше отрицательного».
from sklearn.metrics import roc_auc_score, roc_curve
import numpy as np
# Вероятности (не бинарные предсказания!)
y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0]
y_score = [0.9, 0.2, 0.8, 0.6, 0.3, 0.75, 0.4, 0.1, 0.95, 0.15]
auc = roc_auc_score(y_true, y_score)
print(f"ROC-AUC: {auc:.2f}") # 0.96
# Для построения кривой:
fpr, tpr, thresholds = roc_curve(y_true, y_score)PR-AUC — метрика для несбалансированных данных
ROC-AUC — отличная метрика, но у неё есть слабость: на сильно несбалансированных данных она может быть завышена.
Почему? FPR = FP / (FP + TN). Если отрицательных объектов 99 000, а положительных 1 000, даже 100 ложных срабатываний дают FPR = 100/99000 ≈ 0.001 — почти ноль. ROC-кривая «прижимается» к верхнему левому углу, AUC выглядит отлично, хотя 100 ложных тревог — это 10% от положительного класса.
PR-кривая (Precision-Recall curve) строится аналогично ROC, но по осям Precision (Y) и Recall (X). Она не содержит TN — а именно TN при дисбалансе «размывает» FPR.
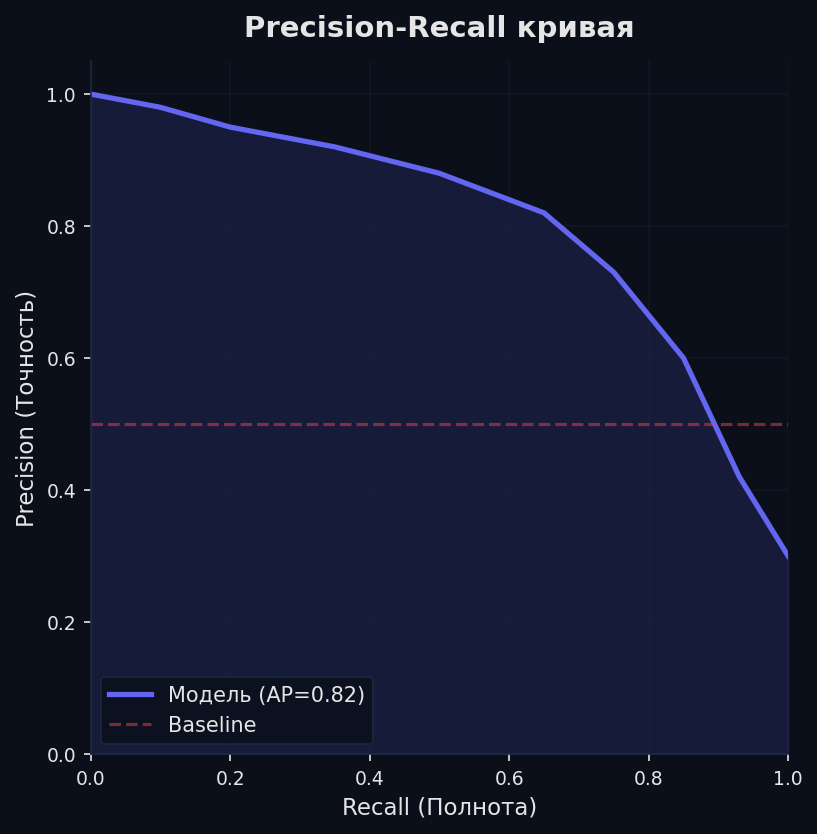
ROC-AUC vs PR-AUC — когда что
Log Loss — оцениваем качество вероятностей
Все предыдущие метрики работают с бинарными предсказаниями или рангами. Но модель выдаёт вероятности — и их качество тоже можно оценить. Если модель говорит «вероятность рака 80%», то из 100 таких пациентов ~80 действительно должны быть больны. Это называется калибровка.
y_i — истинная метка (0 или 1), p_i — предсказанная вероятность положительного класса. Чем ниже — тем лучше
Как работает Log Loss: если объект положительный (y=1) и модель дала p=0.99 — штраф почти нулевой: −log(0.99) ≈ 0.01. Если модель дала p=0.01 — штраф огромный: −log(0.01) ≈ 4.6. Log Loss экспоненциально наказывает за уверенные неправильные ответы.
Когда использовать: когда важны именно вероятности, а не бинарные решения — ранжирование рекламы (bid = f(p·value)), калибровка медицинских моделей, ансамблирование. Идеальный Log Loss = 0 (все вероятности равны 0 или 1 и все верные).
from sklearn.metrics import log_loss
y_true = [1, 0, 1, 1, 0]
y_prob = [0.9, 0.1, 0.8, 0.7, 0.2]
print(f"Log Loss: {log_loss(y_true, y_prob):.4f}") # 0.1998
# Плохая калибровка:
y_prob_bad = [0.6, 0.4, 0.6, 0.55, 0.45]
print(f"Log Loss (плохая): {log_loss(y_true, y_prob_bad):.4f}") # 0.5765Выбор порога — где провести границу
Модель выдаёт вероятность P(positive). Чтобы получить бинарное решение, нужен порог (threshold): если P ≥ t → «положительный». Дефолт — 0.5, но это почти всегда не оптимально.
Как выбрать правильный порог:
- По F1 на валидации. Перебери пороги от 0.01 до 0.99 с шагом 0.01, посчитай F1 для каждого. Выбери максимум. Простой и универсальный способ.
- По бизнес-метрике. Посчитай стоимость FP и FN. Если FN стоит $10 000 (пропущенный фрод), а FP стоит $10 (проверка транзакции) — оптимальный порог будет низким (ловим всех подозрительных).
- По точке на ROC/PR-кривой. Ближайшая точка к идеалу (0, 1) на ROC или (1, 1) на PR. Геометрически — нормаль из идеальной точки к кривой.
- По Youden's J statistic. J = TPR − FPR. Максимум J = оптимальный баланс TPR и FPR. Быстрый способ, не требующий знания стоимостей.
from sklearn.metrics import f1_score
import numpy as np
y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0]
y_score = [0.9, 0.2, 0.8, 0.6, 0.3, 0.75, 0.4, 0.1, 0.95, 0.15]
# Перебор порогов для максимизации F1
best_t, best_f1 = 0.5, 0
for t in np.arange(0.01, 1.0, 0.01):
y_pred = [1 if s >= t else 0 for s in y_score]
f1 = f1_score(y_true, y_pred)
if f1 > best_f1:
best_t, best_f1 = t, f1
print(f"Лучший порог: {best_t:.2f}, F1: {best_f1:.2f}")
# Лучший порог: 0.60, F1: 0.91Частая ошибка
Multi-class: как считать метрики для нескольких классов
Все метрики выше определены для бинарной классификации. Когда классов больше двух (кошка/собака/птица, тональность позитивная/нейтральная/негативная), метрики нужно агрегировать.
Идея: для каждого класса отдельно считаем precision, recall, F1 (по схеме «этот класс vs остальные»). Получаем K значений. Как свести к одному числу? Три стратегии:
- Macro — среднее по классам: (F1_class1 + F1_class2 + F1_class3) / 3. Каждый класс одинаково важен, независимо от размера. Малый класс (100 объектов) весит столько же, сколько большой (10 000).
- Micro — считаем глобальные TP, FP, FN по всем классам, потом вычисляем одну метрику. Эквивалентно accuracy для мультиклассовой задачи. Больше внимания крупным классам.
- Weighted — среднее, взвешенное по числу объектов в каждом классе. Компромисс: учитывает дисбаланс, но крупные классы доминируют.
from sklearn.metrics import classification_report
y_true = [0, 0, 0, 1, 1, 1, 2, 2, 2, 2]
y_pred = [0, 0, 1, 1, 1, 0, 2, 2, 2, 1]
print(classification_report(y_true, y_pred, target_names=["кот", "собака", "птица"]))
# precision recall f1-score support
# кот 0.50 0.67 0.57 3
# собака 0.50 0.67 0.57 3
# птица 1.00 0.75 0.86 4
# accuracy 0.70 10
# macro avg 0.67 0.69 0.67 10
# weighted avg 0.72 0.70 0.70 10Какую агрегацию выбрать
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Все метрики классификации растут из одной таблички 2×2 — confusion matrix. Accuracy считает общую долю правильных ответов, но врёт при дисбалансе. Precision и recall смотрят на разные типы ошибок, а F1 объединяет их в одно число. ROC-AUC оценивает модель при всех порогах, PR-AUC делает то же, но честнее при дисбалансе. Log Loss оценивает качество вероятностей. А порог — это бизнес-решение, а не свойство модели.
Если запомнить одну вещь из этой ноды: не бывает «лучшей» метрики — бывает метрика, подходящая под задачу. Сначала пойми цену FP и FN, потом выбирай метрику и порог.
Дальше на роадмапе: выбор модели и валидация научат тебя оценивать метрики честно (кросс-валидация, переобучение), а ранжирование и рекомендации покажут метрики за пределами классификации — NDCG, MRR, MAP.
Материалы
Полный обзор метрик с примерами на Python. Обязательна к прочтению.
Визуальное объяснение ROC-кривой от StatQuest — лучшее на YouTube.
Чёткое визуальное объяснение precision и recall с примерами.
Официальная документация sklearn по метрикам — все формулы и параметры.
Практическое руководство по выбору порога при дисбалансе классов.