SQL
Запросы, джоины, оконные функции — must have для любого DS/ML.
SQL — первое, что спросят на собесе
Загрузка интерактивного виджета...
Загрузка интерактивного виджета...
Данные живут в базах. Прежде чем обучать модель, ты достаёшь нужные срезы именно SQL-запросами. На собеседованиях SQL-задачи дают почти всегда: от простых выборок до оконных функций и расчёта удержания пользователей.
Любимые задачи на собесах
Порядок выполнения — не как пишешь
Пишешь SELECT ... FROM ... WHERE, а база выполняет в другом порядке: FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT. Понимание этого порядка — ключ к тому, почему нельзя использовать алиас из SELECT в WHERE.

-- Активные пользователи за последний месяц
SELECT user_id, email, last_login
FROM users
WHERE last_login >= CURRENT_DATE - INTERVAL '30 days'
ORDER BY last_login DESC LIMIT 100;JOIN — соединяем таблицы

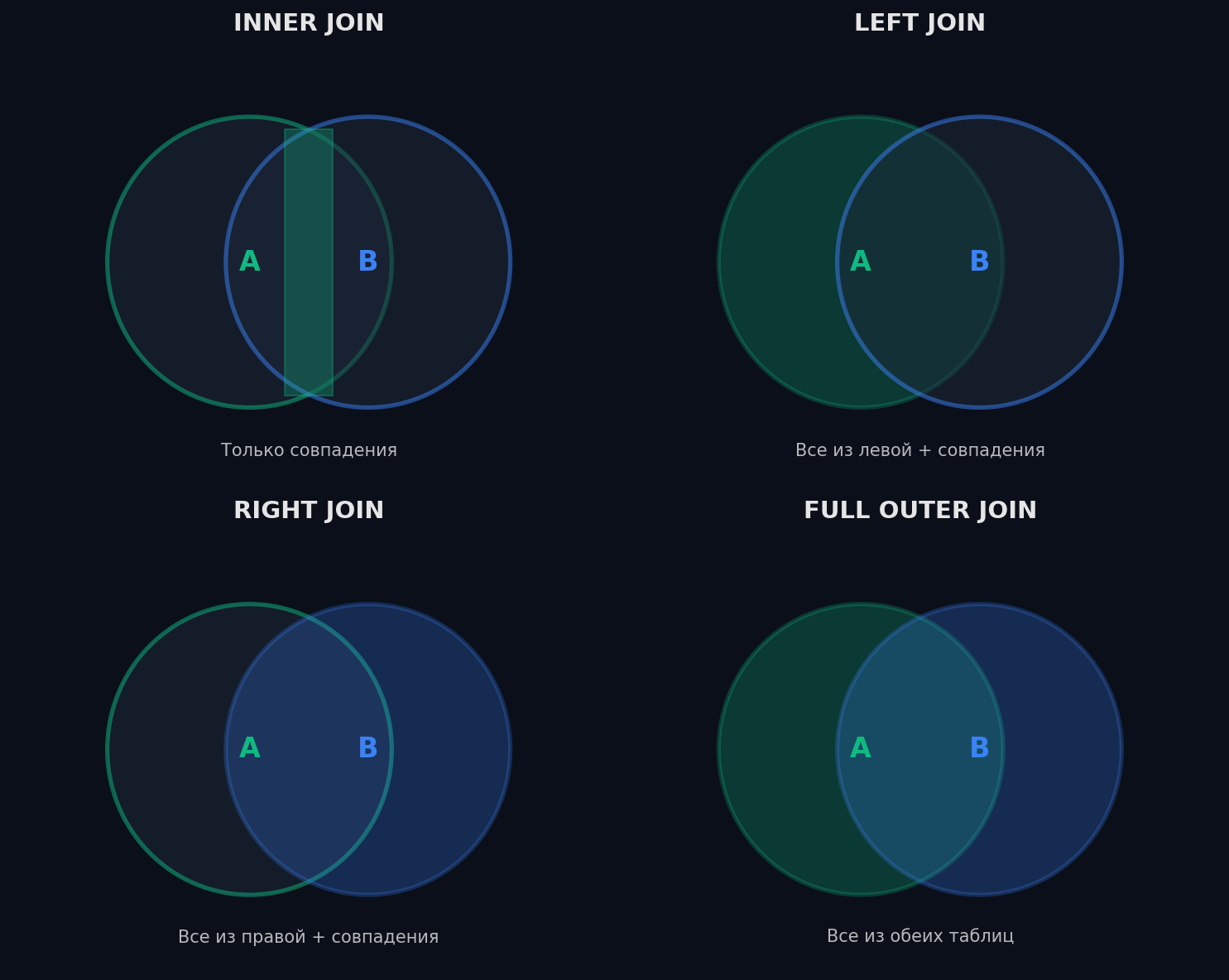
Представь два списка: пользователи и заказы. INNER JOIN — только те, у кого есть заказы. LEFT JOIN — все пользователи, даже без заказов (у них NULL в столбцах заказов). Anti-join — пользователи БЕЗ заказов.
-- Anti-join: кто ни разу не заказывал?
SELECT u.user_id, u.name
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
WHERE o.order_id IS NULL;GROUP BY — агрегируем данные
GROUP BY схлопывает строки в группы. Вместе с COUNT, SUM, AVG получаешь аналитику. HAVING — это WHERE, но после агрегации. Правило: всё в SELECT, что не агрегат, должно быть в GROUP BY.
-- Средний чек по категориям (только где >= 10 покупателей)
SELECT category, COUNT(DISTINCT user_id) AS buyers,
ROUND(AVG(amount), 2) AS avg_check
FROM orders JOIN products USING(product_id)
GROUP BY category HAVING COUNT(DISTINCT user_id) >= 10;Оконные функции — мощь аналитика
В отличие от GROUP BY, оконные функции не схлопывают строки — они добавляют вычисления «сбоку». Это как если бы к каждой строке Excel ты добавил формулу, которая считает что-то по группе, но строки остаются на месте.
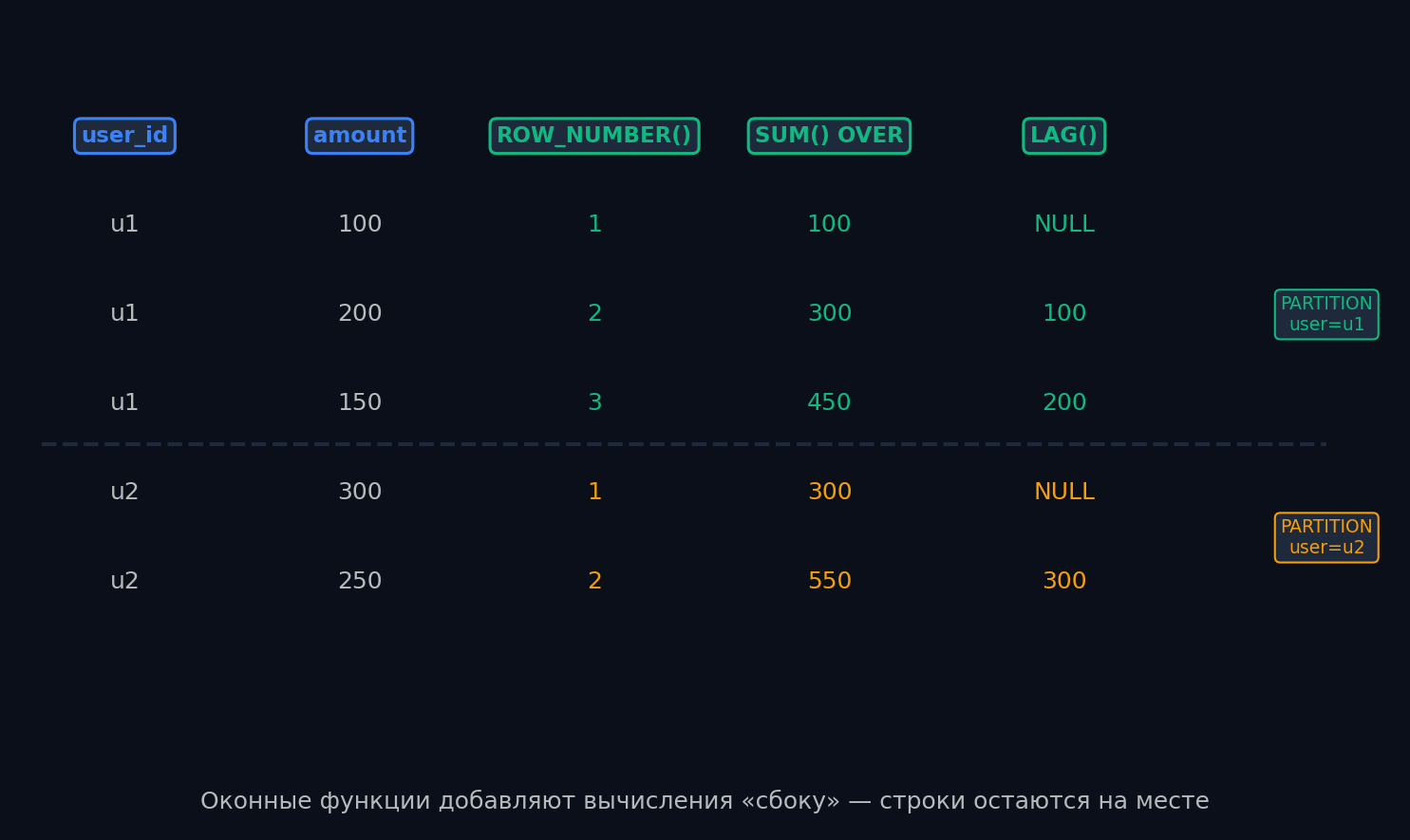
- ROW_NUMBER() — уникальный номер в группе (для дедупликации)
- LAG()/LEAD() — значение из предыдущей/следующей строки
- SUM() OVER — кумулятивная сумма (нарастающий итог)
- RANK()/DENSE_RANK() — ранг с пропусками / без
-- Разница с предыдущим заказом для каждого юзера
SELECT user_id, amount,
amount - LAG(amount) OVER (
PARTITION BY user_id ORDER BY created_at
) AS diff_prev
FROM orders;CTE — читаемые подзапросы
CTE (WITH ... AS) — это именованные подзапросы. Вместо вложенных скобок — читаемые блоки. Классический пример на собесе — расчёт retention по когортам:
WITH cohort AS (
SELECT user_id, MIN(DATE(event_time)) AS first_day
FROM events GROUP BY user_id
)
SELECT first_day, COUNT(*) AS size,
COUNT(CASE WHEN d.event_time::date = first_day + 7
THEN 1 END) AS retained_d7
FROM cohort c LEFT JOIN events d USING(user_id)
GROUP BY first_day;SQL vs pandas — знай оба
🎯 Суть для собеса
Почему PostgreSQL — стандарт индустрии
PostgreSQL — open-source реляционная СУБД, ставшая стандартом. Клиент-серверная архитектура: ты пишешь SQL-запрос, отправляешь серверу, получаешь результат. SQL — декларативный язык: ты описываешь ЧТО хочешь получить, а не КАК это сделать. Как заказать гамбургер в окне McDonald's — тебя не волнует рецепт.
EXPLAIN ANALYZE — смотрим что делает БД
Запрос тормозит? EXPLAIN ANALYZE покажет, что именно БД делает под капотом: сканирует всю таблицу (Seq Scan) или использует индекс (Index Scan). Seq Scan на таблице с миллионом строк — это перебор всех записей. Index Scan — прыжок к нужной записи через B-tree. Разница может быть в 10,000 раз.
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'test@mail.ru';
-- Seq Scan on users (cost=0.00..25000.00 rows=1 width=64) (actual time=850.123..850.123 rows=1)
-- С индексом:
-- Index Scan using idx_users_email on users (cost=0.42..8.44 rows=1 width=64) (actual time=0.05..0.05 rows=1)💡 Правило
Индексы — ускоряем запросы
Индекс — это как оглавление в книге. Без него БД читает все страницы подряд (O(n)). С индексом — открывает нужную страницу сразу (O(log n)). Основные типы: B-tree (по умолчанию, для =, <, >), GIN (для массивов и JSONB), GiST (для геоданных и полнотекстового поиска).
⚠️ Когда НЕ создавать индекс
Материалы
Практический курс с задачами на реальных данных.
Подробный разбор оконных функций с примерами.
50 задач от простых до сложных — идеально для подготовки.
Курс PostgreSQL с практическими примерами.
Видеокурс PostgreSQL для начинающих.
Интерактивные задачи по SQL.