Production CV
~30 мин
CV System Design
Production pipeline, edge vs cloud, масштабирование, мониторинг, data/model drift.
CV System Design — проектирование production CV-систем
На senior+ собеседованиях спрашивают не "обучите ResNet", а "спроектируйте систему видеонаблюдения на 10K камер" или "как запустить детекцию на 1M изображений в день?". CV System Design — это архитектура, масштабирование, мониторинг и trade-offs реальных CV-систем.
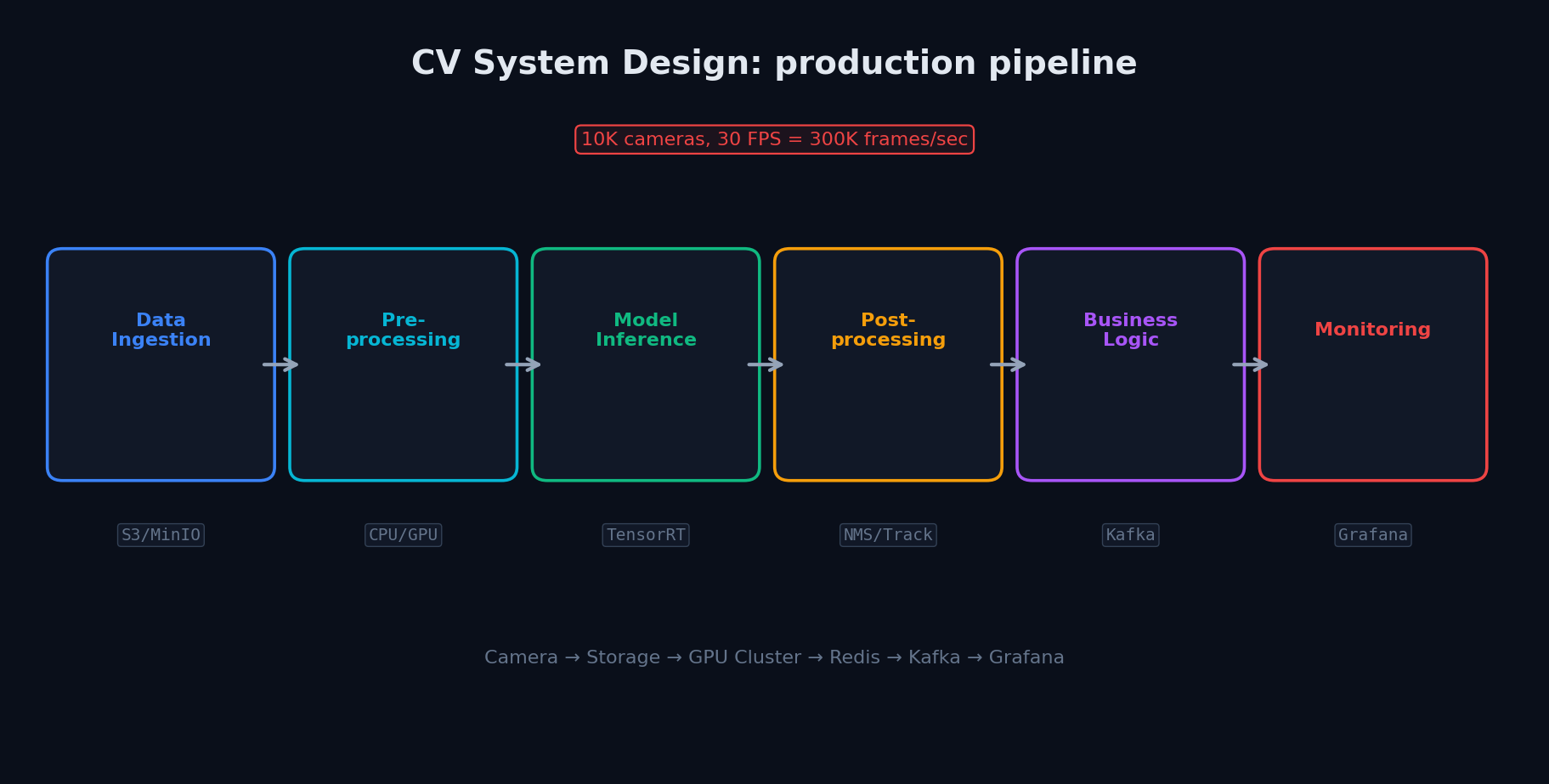
Типичная архитектура CV-пайплайна
Большинство production CV-систем следуют паттерну:
- Data Ingestion — приём изображений/видеопотоков. Kafka/RabbitMQ для очередей. S3/MinIO для хранения.
- Preprocessing — resize, normalization, crop. Часто на CPU. Может быть bottleneck при больших объёмах.
- Model Inference — GPU сервер(ы). TensorRT/ONNX Runtime. Batching для throughput. Triton для multi-model.
- Postprocessing — NMS, threshold filtering, бизнес-логика. CPU.
- Storage & API — результаты в БД (PostgreSQL, Elasticsearch). REST/gRPC API для потребителей.
- Monitoring — latency, throughput, model drift, error rate. Prometheus + Grafana.
Edge vs Cloud deployment
- Cloud — централизованная обработка на мощных GPU. Плюсы: легко масштабировать, обновлять модели. Минусы: latency, bandwidth для видеопотоков, зависимость от сети.
- Edge — инференс на устройстве (NVIDIA Jetson, мобильный телефон, FPGA). Плюсы: низкая latency, работа offline, privacy. Минусы: ограниченные ресурсы, сложное обновление.
- Hybrid — edge для первичной фильтрации ("есть ли объект?"), cloud для сложного анализа. Оптимальный подход для видеонаблюдения.
- Mobile — MobileNet, EfficientNet-Lite, Core ML (Apple), TFLite (Android). INT8 quantization обязательна.
Масштабирование
- Horizontal scaling — больше GPU серверов за load balancer. Kubernetes + GPU operator.
- Batching — собрать несколько запросов в один batch. Dynamic batching в Triton: latency ↑ на 5ms, throughput ↑ в 4x.
- Model parallelism — большая модель на нескольких GPU. Для ViT-Huge и подобных.
- Cascade/Early exit — лёгкая модель фильтрует 90% "простых" случаев, тяжёлая обрабатывает оставшиеся 10%. Пример: MobileNet → ResNet → ViT.
- Caching — если одно изображение обрабатывается несколько раз (например, разными моделями), кеширование features экономит compute.
Типичные задачи на system design
- "Спроектируйте систему visual search" — embedding model → vector DB (Faiss/Milvus) → approximate nearest neighbor. Индексирование offline, поиск online.
- "Видеонаблюдение на 1K камер" — edge detection (YOLO на Jetson) → фильтрация → cloud tracking/ReID. Kafka для потоков. Elasticsearch для поиска.
- "Модерация контента (NSFW/violence)" — classification pipeline. Cascade: lightweight → heavyweight. Human-in-the-loop для пограничных случаев. Latency < 1s.
- "Face recognition в офисе" — embedding model (ArcFace) → enrollment DB → real-time matching. 1:N search через Faiss. Anti-spoofing модуль.
- "Автоматический контроль качества на производстве" — edge camera + detection model. Real-time. False positive rate < 0.1% (иначе забракуют хорошие детали).
Мониторинг CV-моделей
- Data drift — распределение входных изображений меняется (новая камера, сезон, освещение). Мониторинг через embedding distribution shift.
- Model drift — accuracy падает со временем. Периодическая оценка на свежих данных.
- Latency monitoring — P50, P95, P99. Важно для real-time систем. Alerts при P95 > SLA.
- Error analysis — логирование false positives/negatives. Регулярный human review. Active learning для самых "непонятных" примеров.
🎯 На собеседовании
Как отвечать на system design
1) Clarify requirements — QPS, latency SLA, accuracy requirements, budget.
2) High-level architecture — нарисовать блоки: ingestion → preprocessing → inference → postprocessing → storage.
3) Model choice — почему именно этот backbone? Trade-offs speed vs accuracy.
4) Optimization — TensorRT, batching, quantization. Конкретные цифры latency.
5) Scaling — как обработать 10x больше запросов? Horizontal scaling, caching, cascade.
6) Monitoring — как узнать, что модель деградировала? Data drift, periodic evaluation.
Материалы
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNet — depthwise separable convolutions для mobile/edge deployment. Классика efficient CV.
NVIDIA TensorRT — Developer Guide
TensorRT + Triton Inference Server для production CV. Best practices для GPU inference.
TorchServe — PyTorch Model Serving
TorchServe для деплоя PyTorch моделей. REST/gRPC API, multi-model, logging.