Оптимизация инференса
Quantization (FP16/INT8), ONNX Runtime, TensorRT, Triton, pruning, distillation, torch.compile.
Оптимизация инференса — от модели к production
Обучить модель — полдела. В production важна скорость, стоимость и ресурсы. ViT-Large дает 87% accuracy, но 300ms на GPU. Заказчику нужно < 50ms. Оптимизация инференса — это мост между research и production. На собеседовании CV-инженера обязательно спросят: "как ускорить модель в 5 раз?".
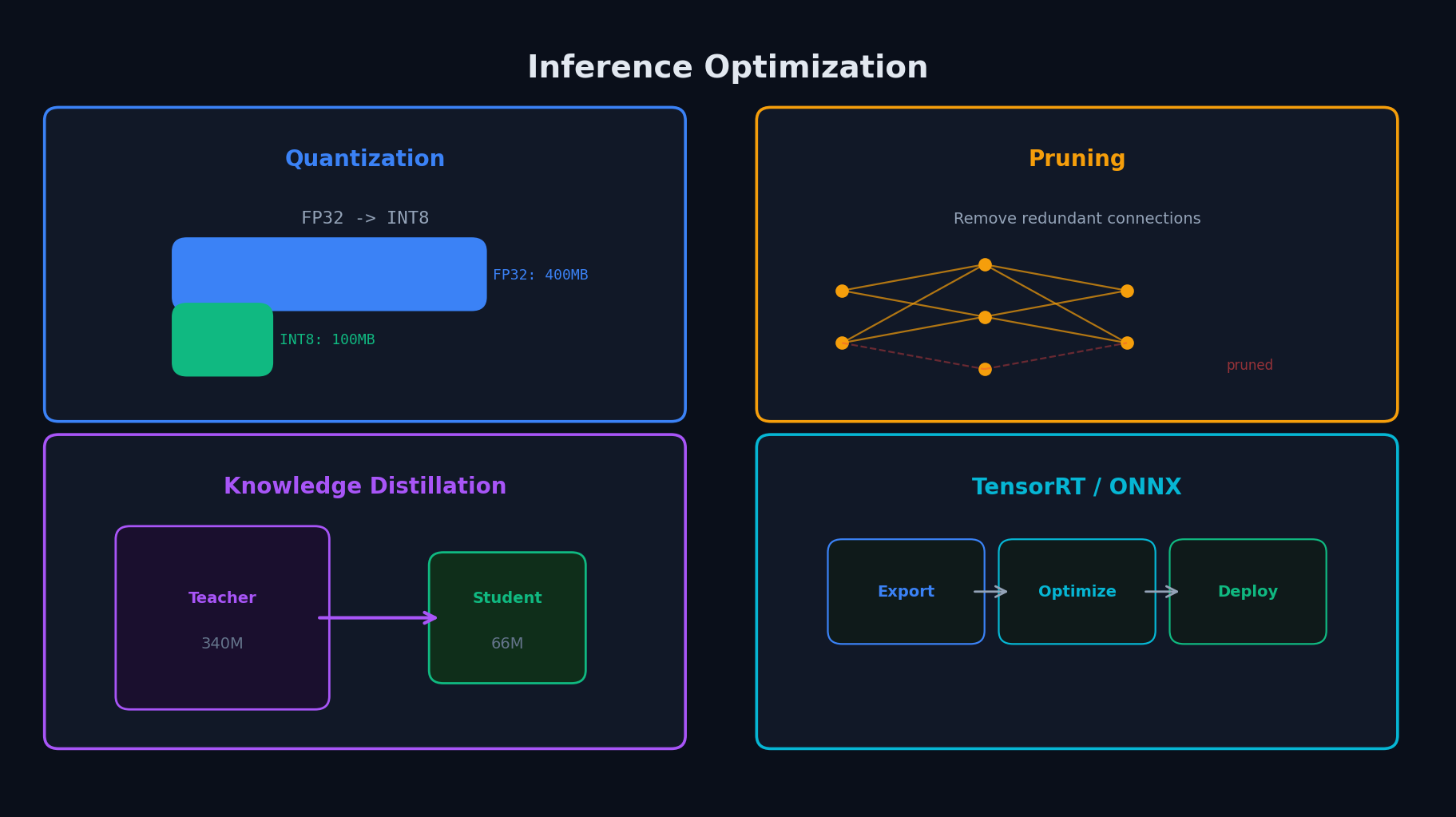
Quantization — меньше бит, быстрее инференс
Квантизация — уменьшение точности весов и активаций: FP32 → FP16 → INT8 → INT4.
- FP16 (half precision) — самый простой шаг. В PyTorch:
model.half()илиtorch.autocast. Ускорение ~2x на GPU, минимальная потеря качества. - INT8 quantization — веса и активации в 8-bit integer. Ускорение ~2-4x. Два подхода:
- • Post-training quantization (PTQ) — квантизуем готовую модель. Быстро, но может терять 1-2% accuracy.
- • Quantization-aware training (QAT) — обучение с "симуляцией" квантизации. Точнее, но дольше.
- INT4 / GPTQ / AWQ — агрессивная квантизация для LLM и больших ViT. 4-bit веса + FP16 активации. Потери 0.5-1% accuracy.
- Dynamic vs Static — dynamic: диапазоны активаций определяются в runtime. Static: калибруются на representative dataset.
ONNX Runtime — универсальный оптимизатор
- ONNX формат — Open Neural Network Exchange. Граф вычислений, не привязанный к фреймворку. PyTorch/TF → ONNX → любой runtime.
- torch.onnx.export() — экспорт модели из PyTorch. Tracing-based: нужен пример входа.
- ONNX Runtime — оптимизированный движок инференса: graph optimization (fusion, constant folding), kernel selection, memory planning.
- Execution Providers — CPU (OpenMP), CUDA, TensorRT, OpenVINO, DirectML. Один ONNX — много платформ.
- Типичное ускорение — 1.5-3x vs чистый PyTorch без квантизации. С INT8: 3-6x.
TensorRT — максимум из NVIDIA GPU
- TensorRT — SDK от NVIDIA для оптимизации инференса на их GPU. Layer fusion, kernel auto-tuning, INT8/FP16 calibration.
- Процесс — PyTorch → ONNX → TensorRT engine (platform-specific). Engine оптимизирован под конкретный GPU.
- Ускорение — 2-10x vs PyTorch. Для YOLO: PyTorch ~15ms → TensorRT ~3ms на RTX 4090.
- Ограничения — engine не переносим между GPU поколениями. Не все операции поддержаны (custom plugins).
- Triton Inference Server — серверная обёртка от NVIDIA. Batching, model versioning, multi-model. Поддерживает TensorRT, ONNX, PyTorch.
Другие техники оптимизации
- Pruning — удаление малозначимых весов/нейронов. Structured pruning (целые каналы) → реальное ускорение. Unstructured → только compression.
- Knowledge Distillation — обучение маленькой модели (student) на soft targets большой (teacher). ViT-L → ViT-S с минимальной потерей.
- Model architecture — MobileNet, EfficientNet-Lite, FastViT. Специально спроектированы для скорости.
- Torch.compile — JIT-компиляция PyTorch 2.0.
model = torch.compile(model). Fusion + codegen. 1.5-3x ускорение "бесплатно". - Batching — больший batch size → лучшая утилизация GPU. Dynamic batching в Triton Server.
- Precision per layer — mixed precision: критичные слои в FP16, остальные в INT8. Fine-grained контроль.
Типичный пайплайн оптимизации
1) FP16 (бесплатно, ~2x) → 2) torch.compile (бесплатно, ~1.5x) → 3) ONNX Runtime (немного работы, ~2x) → 4) TensorRT (больше работы, ~3x) → 5) INT8 quantization (калибровка, ~2x) → 6) Pruning/Distillation (обучение, ~2x). Общее ускорение может быть 10-50x.
🎯 На собеседовании
Частые вопросы
Материалы
Документация ONNX Runtime. Примеры экспорта, оптимизации, квантизации.
TensorRT SDK — layer fusion, INT8/FP16 calibration, Triton integration.
Knowledge Distillation — обучение маленькой модели на soft targets большой. Классика.