Production CV
~35 мин
Подготовка к собеседованию по CV
Вопросы Junior/Middle/Senior, system design задачи, чеклист подготовки, coding tasks.
Подготовка к собеседованию по CV
Собеседование на CV-инженера — это микс теории (архитектуры, loss-функции, метрики), практики ("обучите детектор", "оптимизируйте инференс") и system design ("спроектируйте pipeline"). Здесь собраны самые частые вопросы по уровням: junior, middle, senior.
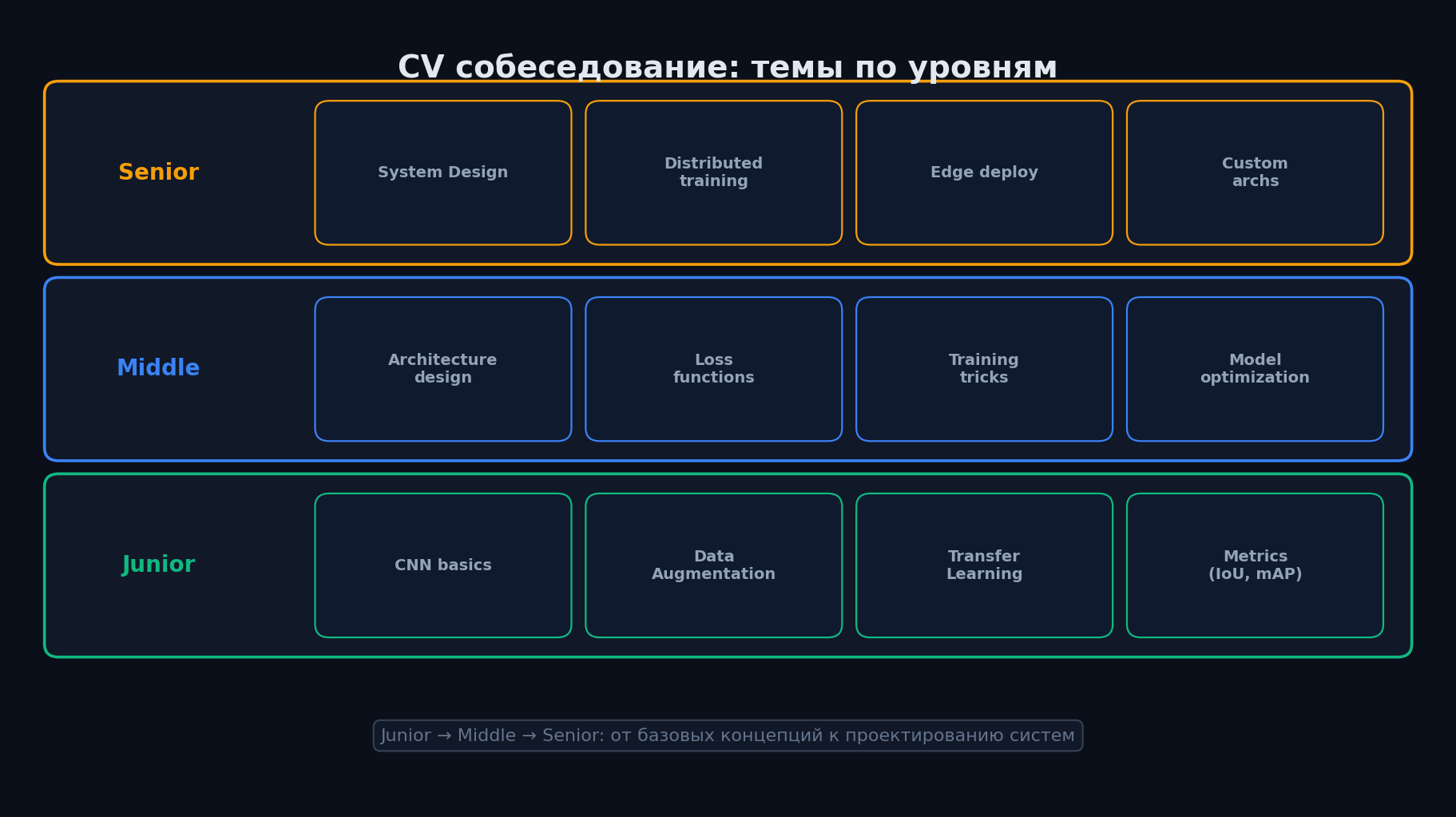
Junior — базовые концепции
- Что такое convolution? Скользящее окно (kernel) поэлементно умножается на участок входа и суммируется. Извлекает локальные паттерны (edges, textures). Параметры: kernel size, stride, padding, dilation.
- Что такое pooling и зачем? Max/Average pooling уменьшает spatial размер. Увеличивает receptive field, добавляет invariance к малым сдвигам, уменьшает число параметров.
- Что такое batch normalization? Нормализует активации по батчу: (x - μ) / σ · γ + β. Ускоряет обучение, стабилизирует градиенты. γ и β — learnable.
- Чем отличается ResNet от VGG? Skip connections (residual connections). Позволяют обучать очень глубокие сети (152+ слоёв) без vanishing gradients.
- Что такое data augmentation? Увеличение датасета через трансформации: flip, rotation, crop, color jitter, Cutout, Mixup, CutMix. Albumentations — стандартная библиотека.
- Transfer learning — что и зачем? Берём модель, предобученную на ImageNet, и fine-tune на свою задачу. Первые слои выучили общие features (edges, textures), их переиспользуем.
Middle — архитектуры и задачи
- Как работает Faster R-CNN? RPN (Region Proposal Network) генерирует proposals → ROI Pooling → classification + bbox regression. Two-stage detector.
- YOLO vs Faster R-CNN — trade-offs? YOLO: one-stage, быстрый (~5ms), немного хуже на мелких объектах. Faster R-CNN: two-stage, точнее на сложных сценах, медленнее (~50ms).
- Как работает U-Net? Encoder-decoder с skip connections между соответствующими уровнями. Encoder сжимает (downsampling), decoder расширяет (upsampling). Skips передают детали.
- Что такое FPN (Feature Pyramid Network)? Многомасштабные features: top-down pathway с lateral connections. Позволяет детектить объекты разных размеров.
- Что такое anchor boxes? Предопределённые bbox шаблоны на каждой позиции feature map. Модель предсказывает offsets и классы относительно anchors. Faster R-CNN, SSD, YOLOv2-v5.
- Anchor-free vs anchor-based? Anchor-free (FCOS, CenterNet): предсказывают центр + расстояния до границ. Проще, меньше гиперпараметров. YOLOv8 — anchor-free.
- Loss functions в detection? Classification: Cross-Entropy / Focal Loss (для class imbalance). Regression: L1, Smooth L1, GIoU, DIoU, CIoU loss.
Senior — продвинутые темы
- ViT vs CNN — когда что? ViT: много данных, глобальный контекст, масштабируемость. CNN: мало данных, edge/mobile, inductive bias. Гибриды (Swin): лучшее из обоих.
- Как работает self-attention в ViT? Патчи как токены. Q, K, V = linear projections. Attention = softmax(QK^T/√d)·V. Multi-head: параллельные attention с разными проекциями.
- Объясните Diffusion Models. Forward: добавляем шум за T шагов. Reverse: нейросеть учится убирать шум. Loss: MSE на предсказание шума. Latent Diffusion: в латентном пространстве VAE.
- Knowledge Distillation для CV. Teacher (ViT-Large) → soft targets → Student (MobileNet). KD loss = KL(softmax(teacher/T), softmax(student/T)). T — temperature.
- Как уменьшить latency модели в 10x? FP16 (2x) + TensorRT (3x) + INT8 quantization (2x) = ~12x. Или: distillation в маленькую модель + TensorRT.
- Data-centric AI в CV. Качество данных > архитектура. Label cleaning, active learning, data augmentation strategy, balancing classes, hard negative mining.
System Design вопросы
- "Спроектируйте Google Photos visual search" — embedding model → vector DB → ANN search. Batch indexing, online serving. Face clustering. Multi-modal (text + image) через CLIP.
- "Real-time детекция на 100 камерах" — edge YOLO (Jetson) → event-driven → cloud analysis. Kafka потоки. GPU autoscaling. Latency budget: 100ms edge + 500ms cloud.
- "Автоматическая модерация контента" — cascade: lightweight classifier (95% accuracy) → heavyweight для uncertain → human review для 1%. Cost-optimization.
- "Медицинская диагностика по рентгенам" — regulatory (FDA/CE), explainability (Grad-CAM), high recall requirement, human-in-the-loop, calibration.
Практические задания
- Coding: реализовать NMS, IoU, custom augmentation pipeline, simple CNN from scratch.
- Model training: fine-tune pretrained model на кастомном датасете. Правильный split, аугментации, LR schedule.
- Debugging: "модель не сходится" — проверить LR, нормализацию, data loader, label corruption.
- Production: экспорт в ONNX, бенчмарк latency, написать inference API на FastAPI.
🎯 Чеклист подготовки
Перед собеседованием
✅ Знаю архитектуры: ResNet, YOLO, U-Net, ViT, Swin, Mask R-CNN
✅ Могу объяснить: convolution, attention, skip connections, batch norm
✅ Знаю метрики: mAP, IoU, Dice, FID
✅ Знаю оптимизацию: TensorRT, ONNX, quantization, distillation
✅ Могу нарисовать system design CV-пайплайна
✅ Написал хотя бы один проект: detection/segmentation pipeline end-to-end
✅ Прочитал ключевые papers: ResNet, YOLO, ViT, CLIP, DDPM
Материалы
Stanford CS231n — полный курс для подготовки
Лучший курс для подготовки к CV-собеседованию. Covers: CNN, detection, segmentation, generation.
ViT paper — An Image is Worth 16x16 Words
Обязательное чтение для senior CV-инженера. Знание ViT спрашивают почти на каждом собеседовании.
Ultralytics YOLOv8 — Documentation
Практика с YOLO: training, export, benchmarking. Покажет real-world CV pipeline.