Multi-stage ранжирование
Candidate generation → pre-ranking → ranking → re-ranking. Архитектура production-пайплайна.
Multi-Stage Ranking — как за 200 мс выбрать 10 из 50 миллионов
Загрузка интерактивного виджета...
У тебя 50 миллионов товаров в каталоге. Показать нужно 10. Самая точная модель ранжирования тратит 1 мс на один айтем — значит, прогнать через неё весь каталог займёт 14 часов. Пользователь столько ждать не будет.
Можно взять простую модель, которая работает за микросекунды — но она будет слишком тупой и не учтёт важные сигналы. Дилемма: быстро, но плохо или хорошо, но невозможно медленно.
Решение — каскад моделей: каждый следующий этап точнее предыдущего, но обрабатывает меньше кандидатов. Лёгкая модель из 50M оставляет 1000, модель потяжелее — 200, тяжёлая — 50, бизнес-правила финализируют 10. Это и есть multi-stage ranking — архитектурный паттерн, без которого ни одна рекомендательная система не работает в продакшне.
Большая картина: четыре этапа каскада
Любой production-пайплайн рекомендаций состоит из четырёх этапов. Каждый — компромисс между скоростью и качеством:
1. Candidate Generation (50M → 1000, ~10 мс). Самый быстрый этап. Из всего каталога отбираем ~1000 потенциально интересных кандидатов. Модели лёгкие — Two-Tower, ANN-поиск. Главное требование: recall — не пропустить релевантные айтемы. 2. Pre-Ranking (1000 → 200, ~10 мс). Лёгкая модель (GBDT с базовыми фичами) быстро отсеивает явно слабых кандидатов. Не везде есть — нужен, когда основная модель слишком дорогая для 1000 штук. 3. Ranking (200 → 50, ~50 мс). Главная модель. Тяжёлый бустинг или нейросеть с десятками признаков, включая cross-features (user × item). Здесь происходит основная «интеллектуальная» работа. 4. Re-Ranking (50 → 10, ~5 мс). Финальная доработка: diversity, бизнес-правила, freshness, deduplication. Часто не ML, а набор правил поверх скоров.

Аналогия: ты ищешь квартиру в Москве. Шаг 1 — фильтры на ЦИАН: район, цена, площадь (из 100 000 → 500 объявлений за секунду). Шаг 2 — быстро пролистываешь фотки, отсеиваешь явно плохие (500 → 50). Шаг 3 — внимательно читаешь описание, проверяешь карту, метро, отзывы (50 → 10). Шаг 4 — «эту не буду, потому что рядом стройка; эту подниму, потому что заезд завтра» (бизнес-правила и контекст).
Candidate Generation: 50 миллионов → 1000 за 10 мс
Задача первого этапа — recall: из всего каталога вытащить ~1000 кандидатов так, чтобы среди них точно были релевантные. Если нужный айтем не попал в эту тысячу — никакое ранжирование его не спасёт. Recall на этапе генерации кандидатов — самая критичная метрика всего пайплайна.
Основной инструмент — Two-Tower модель + ANN-индекс. User-tower кодирует пользователя в вектор, item-tower — каждый айтем. Все item-эмбеддинги хранятся в ANN-индексе (FAISS, ScaNN, HNSW). При запросе: считаем user-эмбеддинг (1 forward pass), ищем ближайших соседей в индексе (~10 мс на 50M векторов). Подробнее об архитектуре — в ноде Two-Tower.
Но одного канала мало. В продакшне candidate generation — это несколько источников, работающих параллельно: • Two-Tower — персональные рекомендации на основе истории пользователя • Item-based CF — «похожие на последние просмотренные» (хорошо для сессионных рекомендаций) • Популярное — бейзлайн для холодного старта, новых пользователей • Тренды — айтемы, набирающие популярность прямо сейчас Каждый канал возвращает свой список кандидатов. Результаты объединяются, дедуплицируются и передаются дальше.
import asyncio
async def multi_source_retrieval(user_id: str, n: int = 1000) -> list[str]:
"""Параллельный запуск нескольких каналов candidate generation."""
# Все каналы стартуют одновременно — укладываемся в бюджет
two_tower, item_cf, popular = await asyncio.gather(
two_tower_retrieve(user_id, n=500), # персональные
item_cf_retrieve(user_id, n=300), # похожие на последние
popular_retrieve(n=200), # популярное (cold start)
)
# Объединяем со взвешенными скорами
merged: dict[str, float] = {}
for item_id, score in two_tower:
merged[item_id] = merged.get(item_id, 0) + score * 0.5
for item_id, score in item_cf:
merged[item_id] = merged.get(item_id, 0) + score * 0.3
for item_id, score in popular:
merged[item_id] = merged.get(item_id, 0) + score * 0.2
# Топ-N по объединённому скору
top_n = sorted(merged, key=merged.get, reverse=True)[:n]
return top_nPre-Ranking: 1000 → 200 за 10 мс
Pre-ranking нужен, когда основная модель ранжирования слишком дорогая для 1000 кандидатов. Если ranking-модель тратит 0.5 мс на айтем — 1000 × 0.5 мс = 500 мс, это за пределами бюджета. Pre-ranking сокращает список до 200, и ranking укладывается в 100 мс.
Модель должна быть лёгкой, но умнее, чем candidate generation. Типичные варианты: • GBDT с базовыми фичами — категория айтема, популярность, CTR за последнюю неделю, возраст пользователя. Десяток признаков, неглубокие деревья. CatBoost/LightGBM на 1000 примеров отрабатывают за миллисекунды. • Маленькая нейросеть — 2-3 слоя, без тяжёлых cross-features. Быстрее батч-инференса тяжёлой модели. • Distilled model — «ученик», обученный повторять скоры основной ranking-модели, но с меньшей архитектурой.
Ключевое отличие от candidate generation: pre-ranker видит больше фичей (не только эмбеддинги, но и статистику по айтему), но меньше, чем полноценный ranker. Ключевое отличие от ranking: pre-ranker не вычисляет дорогие cross-features (user × item кросс-статистики, real-time агрегаты).
Ranking: 200 → 50 — главная модель
Ranking — это сердце пайплайна. Модель работает только с 200 кандидатами, поэтому может себе позволить тяжёлые вычисления: десятки и сотни признаков, cross-features, real-time статистику.
Что делает ranking-модель сильнее pre-ranker: • Cross-features (user × item) — «сколько раз этот юзер кликал на товары этой категории за последний час», «средняя оценка этого айтема среди пользователей с похожим профилем». Эти фичи дорого считать, но они дают основной прирост качества. • Эмбеддинги из нескольких моделей — Two-Tower эмбеддинг + BERT-эмбеддинг описания + visual-эмбеддинг картинки. • Контекстные фичи — время суток, день недели, устройство, геолокация. • Real-time агрегаты — CTR айтема за последний час, кликстрим юзера за текущую сессию.
Типичные модели:
• Градиентный бустинг (CatBoost, XGBoost) — рабочая лошадка. 100-500 фичей, обучается за минуты, инференс быстрый. Покрывает 80% кейсов.
• Deep & Cross Network, DeepFM — нейросети, которые автоматически находят полезные кросс-фичи. Хорошо, когда ручной feature engineering не масштабируется.
• Multi-task модели — одновременно предсказывают click, add-to-cart, purchase. Финальный скор = взвешенная комбинация: score = w₁·P(click) + w₂·P(cart) + w₃·P(buy).

import numpy as np
def build_ranking_features(user: dict, item: dict, context: dict) -> np.ndarray:
"""Признаки для ranking-модели — дорогие, но точные."""
features = []
# User features
features.append(user['age'])
features.append(user['days_since_registration'])
features.append(user['total_purchases_30d'])
# Item features
features.append(item['price'])
features.append(item['avg_rating'])
features.append(item['views_last_24h'])
# Cross-features (user × item) — главный источник качества
features.append(user['clicks_in_category'].get(item['category'], 0))
features.append(user['purchases_in_brand'].get(item['brand'], 0))
features.append(item['ctr_in_user_segment'].get(user['segment'], 0))
# Context
features.append(context['hour_of_day'])
features.append(context['is_weekend'])
features.append(context['device_type'])
return np.array(features)
# Ranking: предсказываем P(click) × P(purchase)
# scores = ranker.predict(features_matrix) # 200 items × 12 features
# top_50 = np.argsort(scores)[::-1][:50]Re-Ranking: бизнес-логика и diversity
Ranking-модель оптимизирует метрику (CTR, conversion) — но бизнесу нужно больше. Если в топ-10 попали 10 похожих кроссовок — пользователь подумает, что у магазина ничего нет, и уйдёт. Re-ranking решает проблемы, которые ML-модель не видит.
Diversity — одна из главных задач. Алгоритм MMR (Maximal Marginal Relevance): на каждом шаге выбираем айтем, который и релевантен (высокий скор от ranker), и непохож на уже выбранные:
score_mmr = λ · relevance(item) − (1−λ) · max_similarity(item, selected)
При λ=1 — чистая релевантность, при λ=0 — максимальное разнообразие. Обычно λ ≈ 0.7.
Что ещё делает re-ranking: • Бизнес-правила — промо-товары поднимаются наверх, 18+ контент фильтруется для детских аккаунтов, товары не в наличии скрываются • Freshness — если всё время показывать одно и то же, пользователь заскучает. Новые айтемы получают бонус к скору • Deduplication — убираем дубли (один товар от разных продавцов, один фильм в разных подборках) • Exploration — 5-10% слотов отдаём «исследовательным» рекомендациям — айтемам, про которые система мало знает. Это helps собрать данные и не застрять в «пузыре» • Fairness — равномерное представление продавцов/авторов, чтобы не монополизировать выдачу
def mmr_rerank(
items: list[str],
scores: dict[str, float],
similarity: callable,
k: int = 10,
lambd: float = 0.7,
) -> list[str]:
"""Maximal Marginal Relevance — баланс релевантности и diversity."""
selected = []
remaining = set(items)
for _ in range(k):
best_item, best_score = None, -float('inf')
for item in remaining:
relevance = scores[item]
# Максимальное сходство с уже выбранными
max_sim = max(
(similarity(item, s) for s in selected),
default=0.0,
)
mmr = lambd * relevance - (1 - lambd) * max_sim
if mmr > best_score:
best_item, best_score = item, mmr
selected.append(best_item)
remaining.remove(best_item)
return selectedLatency budget: 200 мс на всё
Весь пайплайн должен уложиться в 100-200 мс (p99). Это жёсткое ограничение: каждые 100 мс задержки в e-commerce снижают конверсию на ~1%. Latency budget — распределение этого времени между этапами.
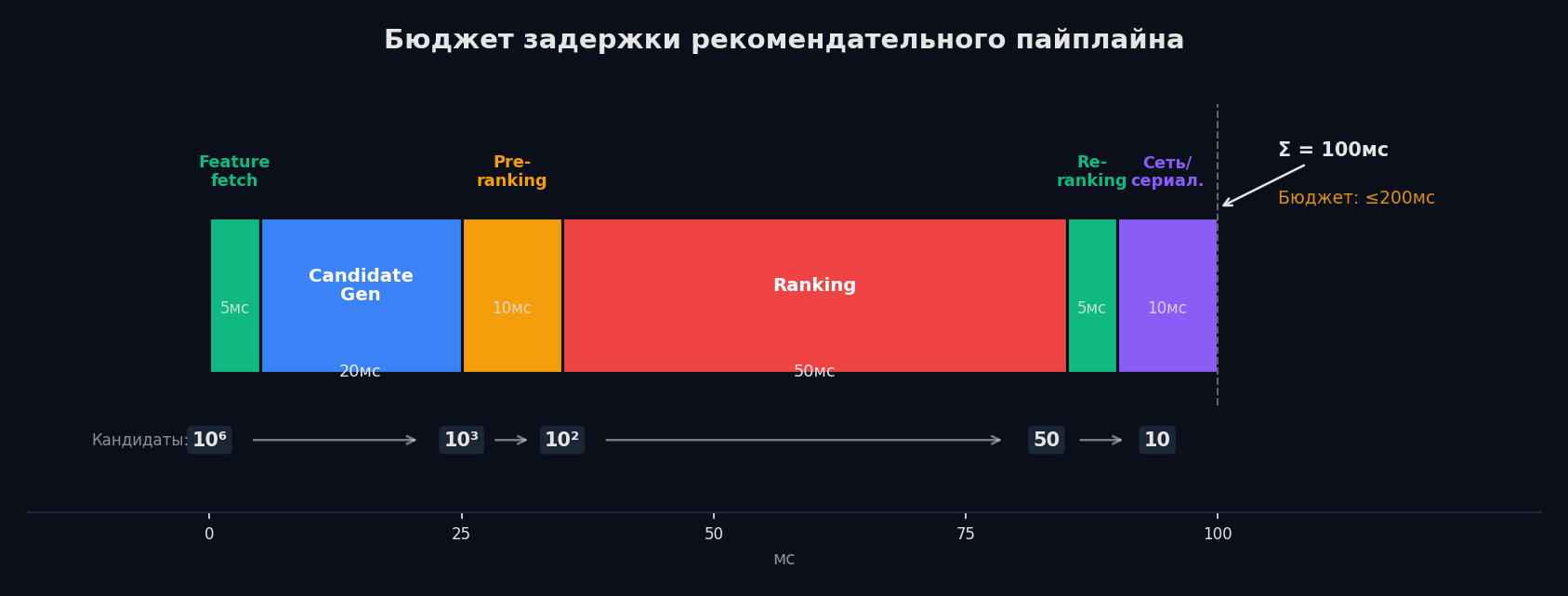
Типичное распределение для бюджета в 150 мс: | Этап | Время | Что ограничивает | |---|---|---| | Candidate generation | ~15 мс | ANN-поиск, параллельные каналы | | Pre-ranking | ~10 мс | Лёгкая модель, батч-инференс | | Feature computation | ~30 мс | Запросы к feature store (Redis/кэш) | | Ranking | ~50 мс | Тяжёлая модель, 200 кандидатов | | Re-ranking | ~5 мс | Правила, MMR | | Network + serialization | ~15 мс | gRPC, protobuf | | Итого | ~125 мс | Запас ~25 мс на джиттер |
Как укладываться в бюджет: • Параллельность — каналы candidate generation запускаются одновременно (asyncio.gather), feature computation идёт параллельно с pre-ranking • Кэширование — item-эмбеддинги, офлайн-фичи, user-профили хранятся в Redis/Memcached. Обновление — батчами каждые 5-15 минут • Батч-инференс — не по одному айтему, а пачкой. GPU особенно выигрывает от батчей • Таймауты — если канал candidate generation не ответил за 20 мс, идём без него. Graceful degradation важнее, чем ожидание
Полный pipeline в коде
from dataclasses import dataclass
import time
@dataclass
class PipelineStats:
stage: str
items_in: int
items_out: int
latency_ms: float
class MultiStageRanker:
"""Production multi-stage ranking pipeline."""
def __init__(self, retriever, pre_ranker, ranker, re_ranker):
self.retriever = retriever # Two-Tower + ANN (multi-source)
self.pre_ranker = pre_ranker # Light GBDT
self.ranker = ranker # Heavy model (CatBoost / deep)
self.re_ranker = re_ranker # Diversity + business rules
def recommend(self, user_id: str, context: dict, k: int = 10):
stats = []
# Stage 1: Candidate Generation (50M → 1000)
t0 = time.monotonic()
candidates = self.retriever.retrieve(user_id, n=1000)
stats.append(PipelineStats('retrieval', , len(candidates),
(time.monotonic() - t0) * 1000))
# Stage 2: Pre-Ranking (1000 → 200)
t0 = time.monotonic()
pre_scores = self.pre_ranker.predict(user_id, candidates)
top_200 = sorted(zip(candidates, pre_scores),
key=lambda x: x[1], reverse=True)[:200]
stats.append(PipelineStats('pre_ranking', len(candidates), 200,
(time.monotonic() - t0) * 1000))
# Stage 3: Ranking (200 → 50)
t0 = time.monotonic()
items_200 = [c for c, _ in top_200]
features = self.build_features(user_id, items_200, context)
scores = self.ranker.predict(features)
top_50 = sorted(zip(items_200, scores),
key=lambda x: x[1], reverse=True)[:50]
stats.append(PipelineStats('ranking', 200, 50,
(time.monotonic() - t0) * 1000))
# Stage 4: Re-Ranking (50 → k)
t0 = time.monotonic()
result = self.re_ranker.rerank([c for c, _ in top_50], k=k)
stats.append(PipelineStats('re_ranking', 50, k,
(time.monotonic() - t0) * 1000))
total_ms = sum(s.latency_ms for s in stats)
# Логируем: retrieval 12ms, pre_ranking 8ms, ranking 45ms, re_ranking 3ms
return result, stats🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Multi-stage ranking — это архитектурный паттерн: каскад моделей от самой быстрой (candidate generation, весь каталог) до самой точной (ranking, сотни кандидатов). Каждый этап — компромисс скорость/качество, и у каждого своя метрика: recall для CG, NDCG для ranking, diversity + бизнес-KPI для re-ranking.
Если запомнить одну вещь: самая частая ошибка — улучшить ranking, но забыть про recall candidate generation. Если нужный айтем не попал в тысячу кандидатов, никакая модель ранжирования не поможет. Качество пайплайна определяется его самым слабым звеном.
Этот пайплайн — стандартный вопрос на system design собеседованиях. «Нарисуй архитектуру рекомендательной системы» = нарисуй 4 этапа с указанием моделей, количества кандидатов и latency budget на каждом. Следующий шаг на роадмапе — Sequential RecSys, где разберём, как учитывать последовательность действий пользователя в ранжировании.
Материалы
Часть курса Google по рекомендациям: re-ranking, diversity, fairness. Чётко и практично.
Архитектура рекомендаций Netflix: candidate generation, ranking, business rules pipeline.
Two-Tower + ANN для candidate generation в масштабе YouTube. Ключевая статья по retrieval-стадии.
Обзор multi-stage подхода в Авито: candidate generation, ranking, re-ranking на реальных данных.