A/B-тесты в RecSys
Interleaving, on-policy vs off-policy, метрики вовлечённости, долгосрочные эффекты.
A/B-тесты в рекомендациях — почему всё сложнее, чем кажется
Загрузка интерактивного виджета...
Ты натренировал новую модель. Офлайн-метрики выросли: NDCG +2%, Recall@10 +3%. Значит ли это, что пользователи будут довольнее? Не факт. Офлайн-метрики и бизнес-результат расходятся постоянно: модель может лучше ранжировать исторические данные, но хуже работать на живом трафике из-за feedback loops, position bias или сдвига распределения.
Единственный способ проверить — A/B-тест на реальных пользователях. Но A/B-тесты для рекомендательных систем радикально сложнее, чем для обычных фичей (цвет кнопки, текст заголовка). Почему? Потому что рекомендации создают петли обратной связи: модель рекомендует → пользователь кликает → модель учится на кликах → рекомендует ещё агрессивнее. Стандартные предположения A/B-тестов (независимость наблюдений, стационарность) нарушаются.
В этой ноде — полная картина A/B-тестирования для RecSys: от базовой механики (контроль vs treatment) до продвинутых техник (interleaving, guardrail-метрики). Разберём подводные камни, которые убивают эксперименты: неправильное сплитование, novelty effect, сезонность.
Большая картина: как устроен A/B-тест для рекомендаций
A/B-тест — это контролируемый эксперимент. Пользователей случайно делят на две группы: Контроль (A): видит текущую модель рекомендаций — ту, что уже в продакшне. Treatment (B): видит новую модель — ту, которую ты хочешь проверить. После достаточного количества наблюдений сравниваем метрики между группами. Если разница статистически значима — новая модель действительно лучше (или хуже), а не случайно повезло.
Звучит просто, но для RecSys есть три фундаментальных отличия от «обычных» A/B-тестов: 1. Метрики многомерны. Нельзя смотреть только CTR — пользователь может кликать кликбейт и уходить через 5 секунд. Нужно отслеживать десятки метрик одновременно: engagement, retention, revenue, diversity. 2. Эффект проявляется не сразу. Изменение цвета кнопки влияет на конверсию мгновенно. Изменение модели рекомендаций может повлиять на retention только через недели — когда пользователь либо останется, либо уйдёт. 3. Модели взаимодействуют с данными. Если модель рекомендует только популярные фильмы → пользователи кликают популярное → модель получает ещё больше данных про популярное → цикл замыкается. A/B-тест измеряет не статичную «качество модели», а динамику всей системы.
Сплитование: по пользователям, не по запросам
Критический момент, который ломает эксперименты: сплит должен быть по user_id, а не по отдельным запросам. Если один и тот же пользователь иногда видит модель A, иногда модель B — это катастрофа. Ты не сможешь понять, какая модель повлияла на его поведение. Пользователь видит странную «прыгающую» ленту, его UX ухудшается, и ты меряешь не качество модели, а степень раздражения.
Стандартный подход: берём hash(user_id) % 100 и назначаем пользователя в группу. Хеш детерминирован — один и тот же пользователь всегда попадает в одну группу. Это также позволяет запускать несколько экспериментов параллельно, разделяя «слоты» (0-49 — эксперимент 1, 50-99 — эксперимент 2).
import hashlib
def assign_group(user_id: str, experiment: str, num_groups: int = 2) -> int:
"" .
user_id .
experiments seed .
""
key = f"{experiment}:{user_id}"
hash_val = int(hashlib.md5(key.encode()).hexdigest(), 16)
return hash_val % num_groups
# Пользователь 42 всегда в одной группе для данного эксперимента
print(assign_group("user_42", "recsys_v2")) # → 0 (контроль)
print(assign_group("user_42", "recsys_v2")) # → 0 (тот же результат)
print(assign_group("user_42", "recsys_v3")) # → 1 (другой эксперимент — другая группа)Сетевые эффекты — когда сплит по user_id недостаточен
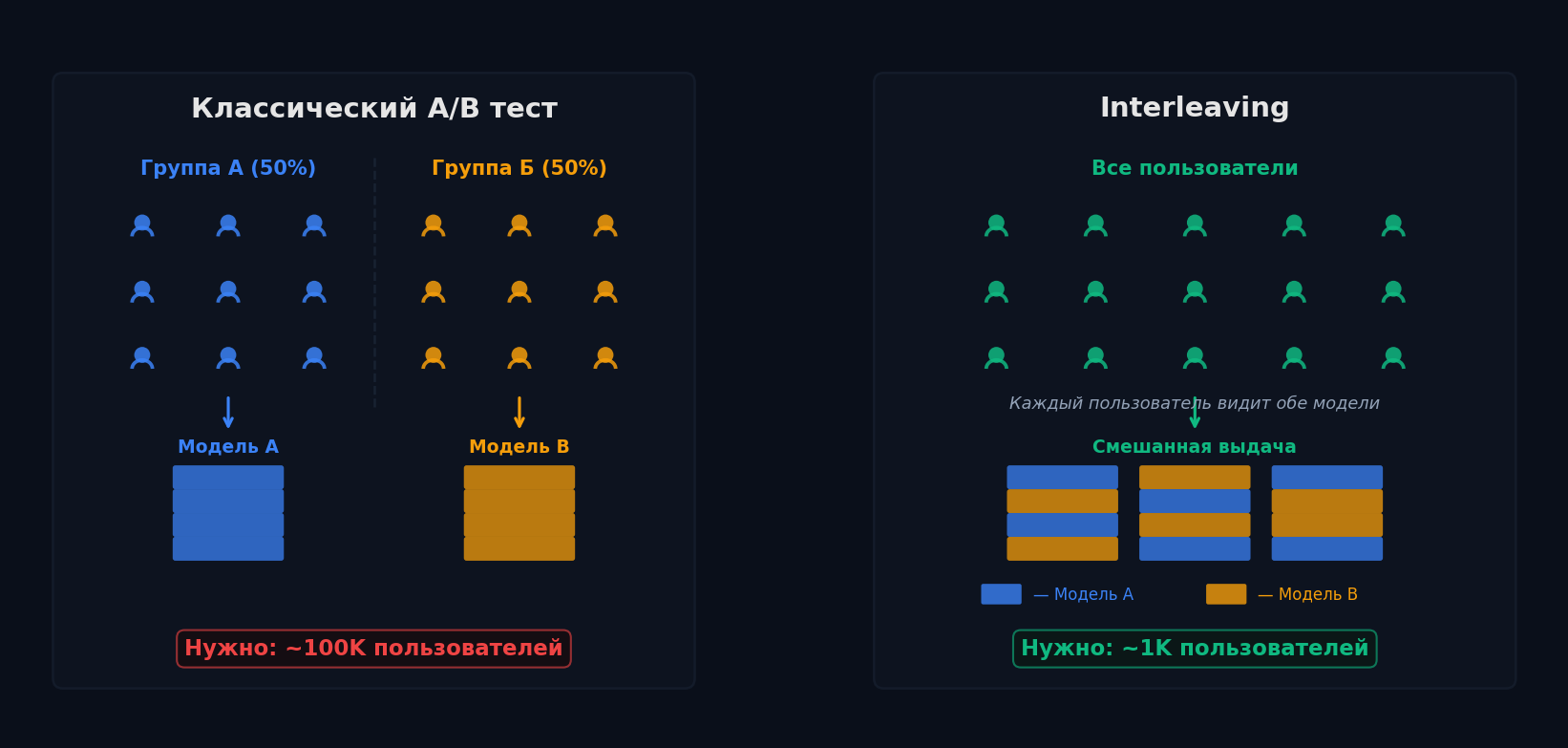
Interleaving — сравниваем модели в 100× быстрее
Классический A/B-тест делит пользователей пополам. Проблема: разные пользователи — разное поведение. Кто-то кликает на всё подряд, кто-то — раз в неделю. Эта межпользовательская дисперсия огромна и «заглушает» тонкую разницу между моделями. Чтобы увидеть +0.5% CTR, нужны сотни тысяч пользователей и недели эксперимента.
Interleaving решает эту проблему радикально: вместо разделения пользователей, каждый пользователь видит результаты обеих моделей вперемешку в одном списке. Модель A предложила [X, Y, Z], модель B — [Y, W, X]. Interleaved список: [X, Y, W, Z, ...]. Каждый клик пользователя — «голос» за ту модель, которая предложила этот айтем.
Почему это быстрее? Сравнение происходит внутри одного пользователя — межпользовательская дисперсия полностью убирается. Netflix показал: interleaving обнаруживает различия между моделями в 100 раз быстрее классического A/B. Вместо 2 недель на 1 миллионе пользователей — 1 день на 10 тысячах.
def team_draft_interleaving(ranking_a: list, ranking_b: list, k: int) -> dict:
""Team-Draft Interleaving: .
:
. , .
""
interleaved = []
team_a, team_b = set(), set()
i, j = 0, 0
while len(interleaved) < k:
if len(team_a) <= len(team_b):
# Очередь модели A: добавляем первый айтем, которого ещё нет
while i < len(ranking_a) and ranking_a[i] in set(interleaved):
i += 1
if i < len(ranking_a):
interleaved.append(ranking_a[i])
team_a.add(ranking_a[i])
i += 1
else:
while j < len(ranking_b) and ranking_b[j] in set(interleaved):
j += 1
if j < len(ranking_b):
interleaved.append(ranking_b[j])
team_b.add(ranking_b[j])
j += 1
return {"interleaved": interleaved, "team_a": team_a, "team_b": team_b}
# Пример: две модели ранжируют фильмы
result = team_draft_interleaving(
ranking_a=["Inception", "Matrix", "Interstellar", "Tenet"],
ranking_b=["Matrix", "Inception", "Arrival", "Blade Runner"],
k=4,
)
# interleaved: [Inception, Matrix, Interstellar, Arrival]
# team_a: {Inception, Interstellar}, team_b: {Matrix, Arrival}
# Если юзер кликнул Inception и Matrix → score 1:1 (tie)
# Если кликнул Inception и Arrival → score 1:1 (tie)
# Если кликнул Inception и Interstellar → score 2:0 → модель A лучшеInterleaving ≠ замена A/B
Novelty effect — когда первые результаты обманывают
Запустил A/B-тест. Через 3 дня — CTR в treatment группе +8%! Победа? Нет. Подожди. Это классический novelty effect: пользователи видят новые, непривычные рекомендации и начинают кликать из любопытства. Через неделю-две эффект исчезает — engagement возвращается к базовому уровню или даже падает ниже.
Обратная ситуация — change aversion: новая модель меняет привычную ленту, пользователи раздражены, CTR падает. Через 2 недели привыкают, и метрики восстанавливаются. Если ты остановил тест на 3-й день — ты убил хорошую модель.
Как бороться: 1. Минимальная длительность — 2 полные недели. Это покрывает рабочие дни + выходные (паттерн потребления отличается). Идеально — 3-4 недели. 2. Смотри на тренд, а не на среднее. Строй график метрики по дням. Если в первые дни +8%, а потом выходит на +2% — реальный эффект ≈ +2%. 3. Burn-in period. Первые 2-3 дня эксперимента — исключай из анализа. Считай статистику только после стабилизации.
Метрики: что именно сравниваем
CTR — первое, что приходит в голову. И первая ловушка. Пользователь кликает кликбейт, разочаровывается, уходит. CTR вырос, а retention упал. Хорошая рекомендательная система оптимизирует долгосрочную ценность, не мгновенные клики.
Метрики выстраиваются по горизонтам: Краткосрочные (дни): CTR, время сессии, глубина просмотра, количество взаимодействий за визит. Реагируют быстро, но могут быть обманчивы. Среднесрочные (недели): Retention D7/D14/D30, конверсия в покупку, средний чек, частота возвращений. Главные метрики для большинства продуктов. Долгосрочные (месяцы): LTV (Lifetime Value), diversity потребления (не скатился ли пользователь в «пузырь»), churn rate. Самые ценные, но труднее всего измерить — A/B-тест такой длительности непрактичен.
Как выбрать primary metric (основную метрику решения)? Это зависит от продукта: • E-commerce: revenue per user, конверсия в покупку • Стриминг (видео/музыка): время просмотра/прослушивания, retention • Новостная лента: время на платформе, количество сессий в день • Маркетплейс: GMV (Gross Merchandise Volume), retention обеих сторон (покупатели + продавцы)
Sample size и длительность — сколько ждать
Два самых частых вопроса: «сколько пользователей нужно?» и «сколько дней держать тест?». Ответ зависит от четырёх параметров: 1. Baseline метрика (p₀). Текущий CTR = 5%. Чем выше базовый уровень, тем легче заметить изменение. 2. Минимальный детектируемый эффект (MDE). Какой прирост хотим заметить? +0.5 процентных пункта? +1%? Чем меньше MDE, тем больше нужно данных. 3. Уровень значимости (α). Вероятность ложного срабатывания (false positive). Стандарт: α = 0.05 (5%). 4. Мощность теста (1−β). Вероятность обнаружить реальный эффект, если он есть. Стандарт: 0.8 (80%).
from scipy import stats
import numpy as np
def sample_size_proportions(p0: float, mde: float,
alpha: float = 0.05, power: float = 0.8) -> int:
"" A/B (CTR).
p0: baseline CTR (, 0.05 = 5%)
mde: (, 0.005 = +0.5 ..)
""
p1 = p0 + mde
z_alpha = stats.norm.ppf(1 - alpha / 2) # двусторонний тест
z_beta = stats.norm.ppf(power)
# Формула для z-теста пропорций
p_avg = (p0 + p1) / 2
n = ((z_alpha * np.sqrt(2 * p_avg * (1 - p_avg)) +
z_beta * np.sqrt(p0 * (1 - p0) + p1 * (1 - p1))) / mde) ** 2
return int(np.ceil(n))
# Пример: CTR = 5%, хотим заметить +0.5 п.п. (MDE = 0.005)
n = sample_size_proportions(p0=0.05, mde=0.005)
print(f"Нужно {n:,} пользователей в каждой группе")
# → ~31,000 на группу → 62,000 всего
# Хотим заметить +0.2 п.п. (MDE = 0.002)
n_small = sample_size_proportions(p0=0.05, mde=0.002)
print(f"MDE 0.2 п.п.: {n_small:,} на группу")
# → ~190,000 на группу — в 6× больше!Длительность = sample_size / DAU × 2. Если нужно 60K пользователей на группу и DAU = 100K → тест займёт ~2 дня по трафику. Но из-за novelty effect и сезонности минимум — 2 полные недели, чтобы покрыть циклы рабочие/выходные. Никогда не запускай A/B-тест в Чёрную пятницу, перед Новым годом или в период акций — сезонность исказит результаты.
Guardrail-метрики: что НЕ должно сломаться
Primary metric выросла — отлично. Но что если при этом latency увеличилась в 3 раза? Или crash rate подскочил? Или жалобы в поддержку удвоились? Guardrail-метрики — это «красные линии», которые новая модель не должна пересекать.
Типичные guardrails для рекомендательных систем: • Latency p99 — время ответа для 99-го перцентиля. Если рекомендации стали медленнее → пользователь уходит, не дождавшись • Error rate — процент запросов с ошибкой. Новая модель может быть нестабильнее • Coverage — какую долю каталога система рекомендует. Если coverage упала → модель скатилась к узкому набору популярных айтемов • Diversity — насколько разнообразны рекомендации. Рост CTR за счёт «кликбейтных» повторов — плохо • Retention (как guardrail) — даже если primary metric = revenue, retention не должен падать • Жалобы / отписки / uninstalls — прямой сигнал о проблемах
Правило: эксперимент проходит, только если primary metric значимо выросла И ни один guardrail не пробит. Если CTR +3%, но latency p99 выросла на 200ms — эксперимент не проходит. Сначала чини latency, потом перезапускай.
Поправка на множественное сравнение
Полный пример: от гипотезы до решения
import numpy as np
from scipy import stats
def ab_test_analysis(control: dict, treatment: dict, alpha: float = 0.05):
"""Анализ A/B-теста для рекомендаций: z-test для CTR + доверительный интервал."""
ctr_c = control['clicks'] / control['views']
ctr_t = treatment['clicks'] / treatment['views']
# Pooled proportion и z-test
p_pool = (control['clicks'] + treatment['clicks']) / (control['views'] + treatment['views'])
se = np.sqrt(p_pool * (1 - p_pool) * (1/control['views'] + 1/treatment['views']))
z_stat = (ctr_t - ctr_c) / se
p_value = 2 * (1 - stats.norm.cdf(abs(z_stat)))
# Относительный lift и 95% доверительный интервал
lift = (ctr_t - ctr_c) / ctr_c
se_lift = np.sqrt(ctr_t*(1-ctr_t)/treatment['views'] + ctr_c*(1-ctr_c)/control['views'])
ci_low = (ctr_t - ctr_c) - 1.96 * se_lift
ci_high = (ctr_t - ctr_c) + 1.96 * se_lift
return {
"ctr_control": f"{ctr_c:.4f}",
"ctr_treatment": f"{ctr_t:.4f}",
"lift": f"{lift:+.2%}",
"p_value": f"{p_value:.4f}",
"significant": p_value < alpha,
"ci_95": f"[{ci_low:+.4f}, {ci_high:+.4f}]",
}
# Сценарий: новая модель рекомендаций для e-commerce
# 2 недели, 50K пользователей в каждой группе
control = {"clicks": 5100, "views": } # CTR = 5.10%
treatment = {"clicks": 5350, "views": } # CTR = 5.35%
result = ab_test_analysis(control, treatment)
print(result)
# {'ctr_control': '0.0510', 'ctr_treatment': '0.0535',
# 'lift': '+4.90%', 'p_value': '0.0097', 'significant': True,
# 'ci_95': '[+0.0006, +0.0044]'}
#
# Решение: lift = +4.9%, p < 0.01, CI не включает 0 → раскатываем.
# НО! Проверяем guardrails: latency p99, error rate, retention D7.Собираем всё вместе
Полный pipeline валидации новой модели рекомендаций: Шаг 1. Офлайн-метрики — NDCG, Recall@K на hold-out. Если хуже текущей модели → не тратим трафик. Шаг 2. Off-policy evaluation — по логам старой модели оцениваем, как бы работала новая (IPS, doubly robust). Фильтруем совсем плохих кандидатов. Шаг 3. Interleaving — быстрый скрининг на малом трафике (1-5% аудитории, 2-3 дня). Отвечает: «ранжирует ли новая модель лучше?» Шаг 4. A/B-тест — полноценный эксперимент с бизнес-метриками. Сплит по user_id, 2-4 недели, primary metric + guardrails. Шаг 5. Раскатка — если A/B пройден → постепенная раскатка (10% → 50% → 100%) с мониторингом guardrails.
Если запомнить одну вещь: A/B-тест для рекомендаций — это не «сравни CTR за 3 дня». Это минимум 2 недели, сплит по user_id, десяток guardrail-метрик и обязательная проверка на novelty effect. Поспешные решения на основе коротких тестов — главная причина провалов в продакшне.
🎯 На собеседовании
Junior
Middle
Senior
Материалы
Как Netflix использует interleaving для быстрого сравнения моделей рекомендаций. Ключевая статья.
Полный туториал по A/B-тестированию от авторов книги. Покрывает sample size, MDE, guardrails, pitfalls.
Практический опыт A/B-тестирования рекомендательных систем на русском языке.
Обзор проблем A/B-тестов в RecSys: network effects, delayed feedback, novelty effect.