Self-Supervised Learning
SimCLR, DINO/DINOv2, MAE, CLIP — обучение без разметки. Контрастивное обучение, маскирование, zero-shot.
Self-Supervised Learning в CV — обучение без разметки
Разметка изображений — дорого и медленно. ImageNet размечали 25K человек. COCO — тысячи аннотаторов рисовали маски. А неразмеченных изображений в интернете — миллиарды. Self-supervised learning (SSL) учит модели извлекать полезные представления из неразмеченных данных. Затем эти представления fine-tune на целевой задаче с малым количеством меток.
В 2020–2024 SSL совершил революцию в CV: DINO, MAE, CLIP показали, что предобученные без меток модели могут превосходить supervised-бейзлайны. Это аналог того, что BERT/GPT сделали для NLP.
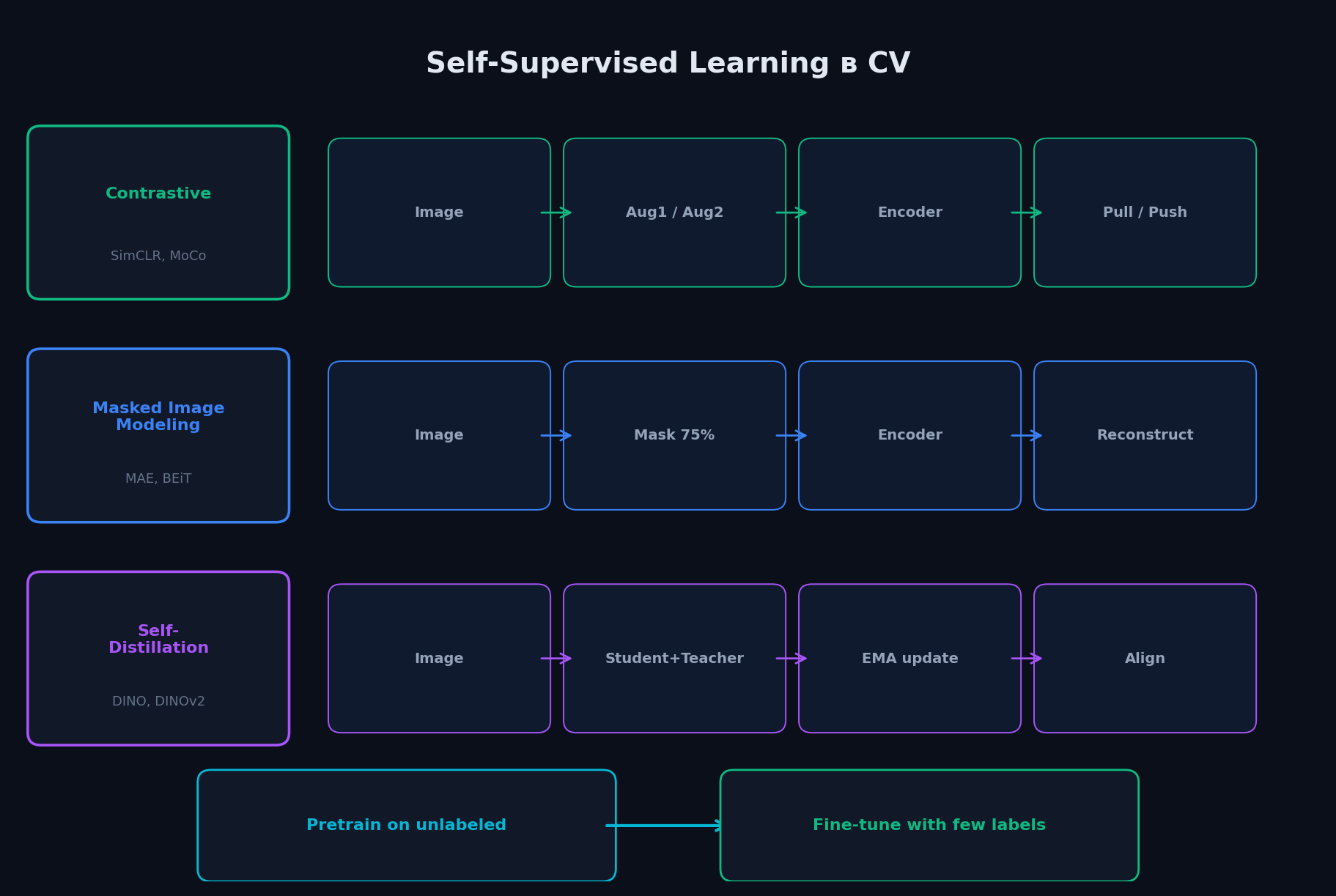
Контрастивное обучение — SimCLR
SimCLR (2020, Google) — простой, но мощный фреймворк контрастивного обучения:
- Две аугментации одного изображения — random crop, color jitter, Gaussian blur → два "вида" (views) одной картинки.
- Encoder + Projection head — оба вида проходят через один encoder (ResNet) → проекция в пространство меньшей размерности.
- NT-Xent loss — positive pair (два вида одного изображения) притягиваются, negative pairs (виды разных изображений в батче) отталкиваются.
- Большой батч — ключ к успеху — SimCLR требует батч 4096–8192 для достаточного количества negatives. Это его главное ограничение.
Self-distillation — DINO и DINOv2
DINO (2021, Meta) — self-supervised ViT без меток и без negatives:
- Student-Teacher framework — student и teacher сети с одинаковой архитектурой. Teacher обновляется через EMA (exponential moving average) весов student.
- Multi-crop strategy — teacher видит глобальные кропы (224×224), student — локальные (96×96). Student учится предсказывать глобальное из локального.
- Centering + sharpening — предотвращает mode collapse (когда модель выдаёт одинаковые представления для всех входов).
- Emergent properties — DINO ViT спонтанно выучивает семантическую сегментацию! Attention maps [CLS] токена точно выделяют объекты. Без единой маски в обучении.
DINOv2 (2023) масштабировал подход до ViT-g (1.1B параметров) на 142M кураированных изображений. Универсальный backbone для любой CV-задачи: classification, segmentation, depth estimation — всё работает с frozen features.
Маскированные автоэнкодеры — MAE
MAE (2022, Meta) — BERT для изображений:
- Маскирование 75% патчей — случайно скрываются 3/4 входных патчей. Encoder видит только оставшиеся 25%.
- Асимметричный дизайн — тяжёлый encoder обрабатывает только видимые патчи. Лёгкий decoder восстанавливает замаскированные.
- Pixel reconstruction — loss = MSE между восстановленными и оригинальными пикселями замаскированных патчей.
- Эффективность — encoder обрабатывает только 25% токенов → 3x ускорение обучения. Pre-training ViT-H на ImageNet-1K: ~3 дня на 128 V100.
- Fine-tuning — после предобучения добавляется classification head. MAE ViT-H: 87.8% top-1 на ImageNet.
CLIP — мост между текстом и изображениями
CLIP (2021, OpenAI) — мультимодальное контрастивное обучение:
- Пары (изображение, текст) — 400M пар из интернета. Image encoder (ViT/ResNet) + Text encoder (Transformer).
- Контрастивный loss — matching пары притягиваются, non-matching отталкиваются в общем пространстве.
- Zero-shot classification — "a photo of a [cat/dog/car]" → проекция в общее пространство → cosine similarity. Без fine-tuning CLIP-ViT-L: 76.2% на ImageNet!
- Open-vocabulary — CLIP понимает произвольные текстовые описания. Можно классифицировать по новым, невиданным классам.
- Фундамент для генерации — CLIP используется в DALL-E 2, Stable Diffusion как image-text alignment модуль.
Сравнение подходов
- SimCLR — контрастивное обучение. Простой, но нужен огромный батч. Хороший baseline для понимания SSL.
- DINO/DINOv2 — self-distillation без negatives. Лучшие универсальные features. Выучивает семантику без меток.
- MAE — маскирование + реконструкция. Масштабируемый pre-training. Хорош для ViT.
- CLIP — мультимодальный (text + image). Zero-shot. Основа для генеративных моделей. Но нужны пары текст-изображение.
🎯 На собеседовании
Частые вопросы
Материалы
SimCLR — основополагающая работа по контрастивному self-supervised learning в CV.
DINO — self-distillation для ViT. Показал, что SSL ViT спонтанно выучивает сегментацию.
CLIP — мультимодальная модель text-image от OpenAI. Фундамент для DALL-E 2, Stable Diffusion.