Гибриды CNN + Transformer
Swin Transformer (shifted windows), ConvNeXt, EfficientNet-V2, CoAtNet. Выбор backbone для задачи.
Гибриды CNN + Transformer — лучшее из двух миров
Чистый ViT мощный, но у него есть проблемы: квадратичная сложность, отсутствие иерархии feature maps и плохая работа на малых данных. CNN, наоборот, имеет отличный inductive bias, но ограничен локальным receptive field. Гибридные архитектуры комбинируют преимущества обоих подходов — и сегодня доминируют в большинстве CV задач.
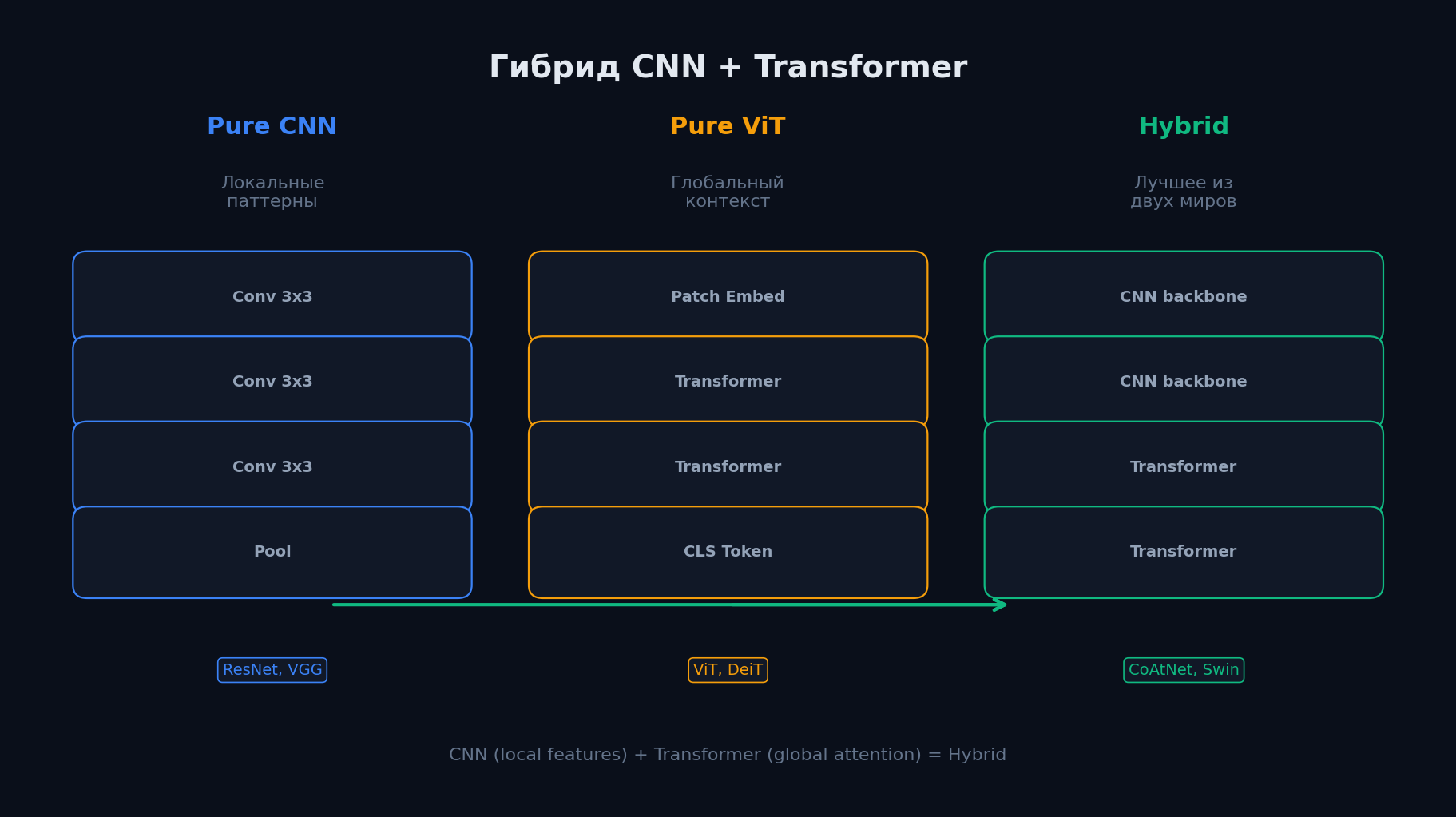
Swin Transformer — иерархия через shifted windows
Swin Transformer (2021, Microsoft) — одна из самых влиятельных архитектур. Ключевые идеи:
- Иерархическая структура — 4 стадии с уменьшением разрешения (как в CNN). Stage 1: H/4 × W/4, Stage 4: H/32 × W/32. Это даёт multi-scale feature maps для detection и segmentation.
- Window-based attention — self-attention считается не глобально, а в окнах фиксированного размера (7×7 патчей). Сложность O(n) вместо O(n²) по числу патчей.
- Shifted windows — в чётных слоях окна сдвигаются на половину размера. Это обеспечивает cross-window connections без глобального attention. Элегантное решение.
- Patch merging — между стадиями соседние патчи объединяются (аналог pooling в CNN), уменьшая разрешение вдвое.
Swin-T/S/B/L достигли SOTA на ImageNet, COCO detection, ADE20K segmentation. Swin стал де-факто backbone для dense prediction задач.
ConvNeXt — CNN наносит ответный удар
ConvNeXt (2022, Meta) задал вопрос: а может, CNN просто не модернизировали? Авторы взяли ResNet-50 и поэтапно применили к нему "трансформерные" трюки:
- Macro design — изменили соотношение блоков с (3,4,6,3) на (3,3,9,3) как в Swin.
- Patchify stem — заменили 7×7 conv + maxpool на неперекрывающуюся 4×4 conv с stride 4.
- Depthwise convolution — разделили свёртку на depthwise (пространственную) и pointwise (канальную). Аналог grouped self-attention.
- Inverted bottleneck — расширили hidden dim в 4 раза (как FFN в Transformer).
- GELU + LayerNorm — заменили ReLU на GELU, BatchNorm на LayerNorm.
- Fewer activation/norm layers — убрали лишние активации между слоями.
Результат: ConvNeXt-T достиг 82.1% top-1 на ImageNet — на уровне Swin-T, при этом оставаясь чистым CNN. ConvNeXt доказал, что разрыв ViT vs CNN был не в self-attention, а в инженерных деталях.
EfficientNet-V2 и другие гибриды
- EfficientNet-V2 — улучшенный NAS-дизайн с Fused-MBConv блоками. Progressive resizing при обучении. EfficientNet-V2-L: 85.7% top-1 на ImageNet.
- CoAtNet — гибрид: ранние стадии — depthwise conv (local), поздние — self-attention (global). Сочетает inductive bias CNN с выразительностью трансформеров.
- MaxViT — multi-axis ViT: чередует block attention и grid attention для эффективного глобального контекста с линейной сложностью.
- BEiT / BEiTv2 — BERT-стиль предобучение для ViT. Маскирование патчей + предсказание визуальных токенов. SOTA на классификации и сегментации.
Как выбрать backbone
- Классификация — ConvNeXt / Swin / EfficientNet-V2. Все примерно равны. Выбор зависит от инфраструктуры.
- Detection (COCO) — Swin + Cascade Mask R-CNN / DINO detector. Swin даёт лучшие multi-scale features.
- Segmentation — Swin + UPerNet / Mask2Former. Иерархическая структура Swin идеальна для dense prediction.
- Mobile/Edge — MobileNetV3, EfficientNet-Lite, EfficientFormer. Latency-оптимизированные.
- Простой baseline — ResNet-50 + FPN. Всё ещё отличный выбор для начала. Быстро, стабильно, хорошо изучен.
🎯 На собеседовании
Частые вопросы
Материалы
Swin Transformer — иерархический трансформер с window attention. Один из самых цитируемых CV papers.
ConvNeXt — модернизированный CNN, конкурирующий с Swin. Отличная статья про design decisions.
EfficientNet-V2 с progressive resizing и Fused-MBConv. Один из лучших по throughput.