PyTorch: train loop на практике
Dataset, DataLoader, train step, checkpoints, inference — полный цикл обучения модели с кодом.
Training Loop — полный цикл обучения в PyTorch
PyTorch не даёт тебе model.fit() как Keras — ты собираешь training loop руками. Это даёт полный контроль: gradient accumulation, mixed precision, custom logging, любые хаки. Но и ответственность за каждый шаг. В этой ноде — от тензоров до production-ready training loop.
Тензоры и autograd — основа PyTorch
Тензор — это многомерный массив (как numpy array), но с двумя суперсилами: работает на GPU и умеет автоматически считать градиенты.
import torch
# Тензор с включённым отслеживанием градиентов
x = torch.tensor([2.0, 3.0], requires_grad=True)
y = (x ** 2).sum() # y = 4 + 9 = 13
y.backward() # вычисли градиенты dy/dx
print(x.grad) # tensor([4., 6.]) — dy/dx = 2x
# Autograd строит граф вычислений автоматически.
# Каждая операция (+, *, mm, relu) записывается в граф.
# .backward() проходит по графу в обратном порядке (backprop).Ключевое: requires_grad=True включает запись операций. nn.Parameter (внутри nn.Module) — это тензор с requires_grad=True по умолчанию. Все веса модели — это nn.Parameter. При вызове loss.backward() PyTorch автоматически вычисляет градиенты для всех параметров.
Граф вычислений — динамический
if, for, while в forward — граф адаптируется. В TensorFlow 1.x граф был статическим (define-and-run). Динамический граф = проще дебажить, проще экспериментировать.
Dataset и DataLoader — подготовка данных
PyTorch разделяет что (Dataset — как достать один пример) и как (DataLoader — как собрать батч, перемешать, загрузить параллельно).
from torch.utils.data import Dataset, DataLoader
class TextDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len=128):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
# Возвращает ОДИН пример (тензоры)
tokens = self.tokenizer(
self.texts[idx],
max_length=self.max_len,
padding='max_length',
truncation=True,
return_tensors='pt'
)
return {
'input_ids': tokens['input_ids'].squeeze(0),
'attention_mask': tokens['attention_mask'].squeeze(0),
'label': torch.tensor(self.labels[idx], dtype=torch.long),
}
# DataLoader собирает примеры в батчи
train_loader = DataLoader(
dataset,
batch_size=32,
shuffle=True, # перемешивать каждую эпоху
num_workers=4, # параллельная загрузка (4 процесса)
pin_memory=True, # ускоряет CPU→GPU трансфер
drop_last=True, # отбросить неполный последний батч
)num_workers — сколько процессов параллельно готовят следующий батч, пока GPU считает текущий. Типичное значение: 4-8. Если 0 — загрузка в основном процессе (медленно). На Windows часто приходится ставить 0 из-за проблем с multiprocessing.
pin_memory=True — выделяет данные в закреплённой (non-pageable) RAM. Перенос на GPU через .to(device) становится асинхронным и быстрым. Включай всегда, если обучаешь на GPU.
collate_fn — кастомная функция для сборки батча. По умолчанию DataLoader просто стакает тензоры. Нужна, если примеры разной длины (NLP) или нестандартной формы.
# collate_fn для текстов разной длины (dynamic padding)
def collate_fn(batch):
input_ids = [item['input_ids'] for item in batch]
labels = torch.stack([item['label'] for item in batch])
# Паддим до длины самого длинного в батче (а не до max_len)
input_ids = torch.nn.utils.rnn.pad_sequence(input_ids, batch_first=True)
return {'input_ids': input_ids, 'labels': labels}
loader = DataLoader(dataset, batch_size=32, collate_fn=collate_fn)Training Loop — пошаговый разбор
Каждая итерация training loop состоит из 5 шагов: forward (предсказание) → loss (оценка ошибки) → backward (вычисление градиентов) → step (обновление весов) → zero_grad (обнуление градиентов). Порядок критичен.
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# ─── Setup ───────────────────────────────────────────────────────────
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
])
train_data = datasets.MNIST('data', train=True, download=True, transform=transform)
val_data = datasets.MNIST('data', train=False, transform=transform)
train_loader = DataLoader(train_data, batch_size=128, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_data, batch_size=256, num_workers=4, pin_memory=True)
model = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(256, 128), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(128, 10),
).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=0.01)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10)
# ─── Training ────────────────────────────────────────────────────────
best_acc = 0.0
for epoch in range(10):
# Train
model.train()
total_loss = 0.0
for x, y in train_loader:
x, y = x.to(device), y.to(device) # данные на GPU
logits = model(x) # 1. forward
loss = criterion(logits, y) # 2. loss
loss.backward() # 3. backward (compute gradients)
optimizer.step() # 4. update weights
optimizer.zero_grad() # 5. clear gradients
total_loss += loss.item() * x.size(0)
# Eval
model.eval()
correct = 0
with torch.no_grad():
for x, y in val_loader:
x, y = x.to(device), y.to(device)
correct += (model(x).argmax(1) == y).sum().item()
acc = correct / len(val_data)
scheduler.step()
avg_loss = total_loss / len(train_data)
print(f"Epoch {epoch+1:2d} | loss={avg_loss:.4f} | val_acc={acc:.2%} | lr={scheduler.get_last_lr()[0]:.2e}")
# Save best
if acc > best_acc:
best_acc = acc
torch.save(model.state_dict(), 'best_model.pt')
print(f"Best val accuracy: {best_acc:.2%}")
# → ~98.3% за 10 эпох на MLP. CNN даст 99.5%+Почему zero_grad() ПОСЛЕ step()?
backward() → step() → zero_grad() и zero_grad() → backward() → step() оба корректны. Но zero_grad() после step() — чуть лучше для gradient accumulation: ты можешь вызвать backward() несколько раз перед step(), и градиенты будут накапливаться. С PyTorch 1.7+ можно optimizer.zero_grad(set_to_none=True) — быстрее, т.к. не заполняет нулями, а удаляет .grad.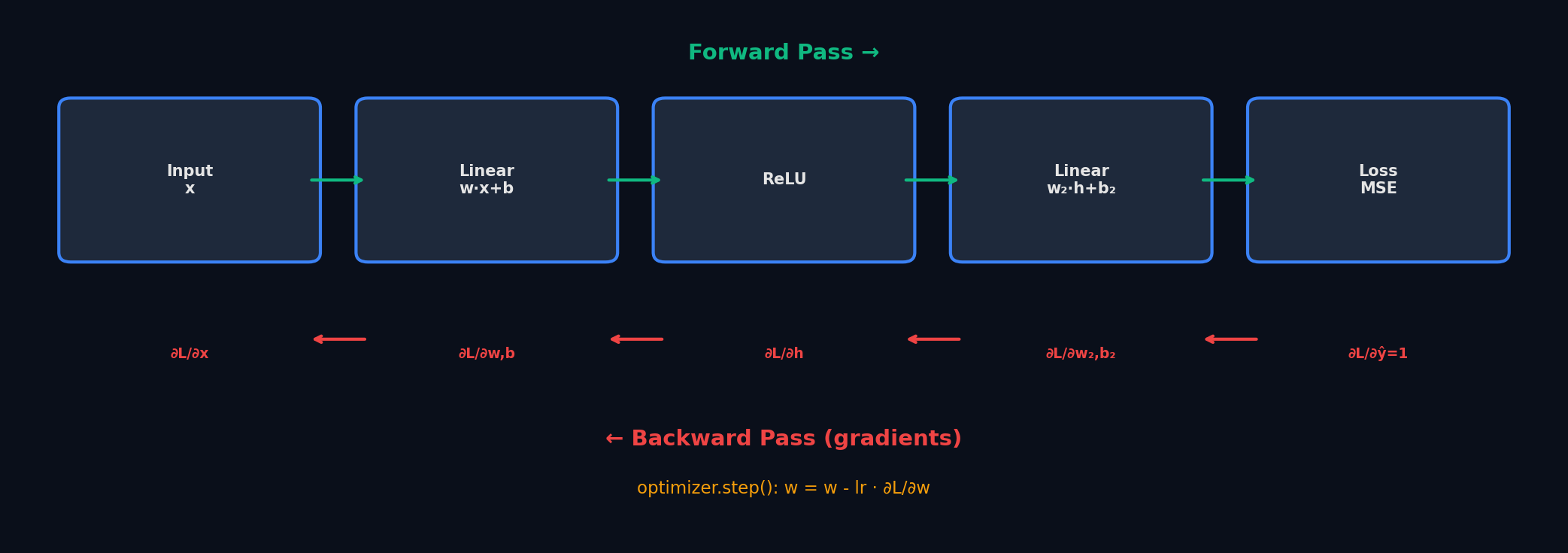
Eval loop и метрики
model.eval() — переключает модель в режим инференса. Dropout выключается, BatchNorm использует running statistics (а не статистики текущего батча). Забыть model.eval() — классическая ошибка: accuracy на валидации будет занижена из-за Dropout.
torch.no_grad() — отключает запись графа вычислений. Не нужны градиенты → экономим 50%+ GPU памяти и ускоряем вычисления. При инференсе — всегда используй torch.no_grad() (или torch.inference_mode() — ещё быстрее, но нельзя потом вычислить градиенты).
from sklearn.metrics import classification_report
@torch.no_grad()
def evaluate(model, loader, device):
model.eval()
all_preds, all_labels = [], []
total_loss = 0.0
for x, y in loader:
x, y = x.to(device), y.to(device)
logits = model(x)
total_loss += criterion(logits, y).item() * x.size(0)
all_preds.append(logits.argmax(1).cpu())
all_labels.append(y.cpu())
preds = torch.cat(all_preds).numpy()
labels = torch.cat(all_labels).numpy()
avg_loss = total_loss / len(loader.dataset)
print(f"Val loss: {avg_loss:.4f}")
print(classification_report(labels, preds, digits=3))
return avg_lossGradient Accumulation — большой batch без памяти
Хочешь effective batch size 512, но в GPU помещается только 64? Gradient accumulation: делай backward() несколько раз перед step(). Градиенты накапливаются в .grad. Результат математически эквивалентен большому батчу.
accumulation_steps = 8 # effective batch = 64 * 8 = 512
for i, (x, y) in enumerate(train_loader):
x, y = x.to(device), y.to(device)
logits = model(x)
loss = criterion(logits, y)
loss = loss / accumulation_steps # нормализуем loss!
loss.backward() # градиенты накапливаются
if (i + 1) % accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
optimizer.zero_grad()
scheduler.step() # если per-step schedulerНе забудь разделить loss!
loss / accumulation_steps — критически важно. Без этого градиенты будут в N раз больше, чем при реальном батче 512. Эффективный lr увеличится, обучение может разойтись.Mixed Precision — ускорение в 2x бесплатно
Современные GPU (Volta+, RTX 20xx+) имеют Tensor Cores, которые считают fp16 в 2-8x быстрее fp32. Mixed precision: forward и backward в fp16 (быстро), обновление весов в fp32 (точно). PyTorch torch.amp делает это автоматически.
from torch.amp import autocast, GradScaler
scaler = GradScaler() # масштабирует loss чтобы fp16 градиенты не underflow
for x, y in train_loader:
x, y = x.to(device), y.to(device)
with autocast(device_type='cuda'): # forward в fp16
logits = model(x)
loss = criterion(logits, y)
scaler.scale(loss).backward() # backward в fp16
scaler.unscale_(optimizer) # вернуть градиенты в fp32
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
scaler.step(optimizer) # step в fp32
scaler.update() # обновить масштаб
optimizer.zero_grad()Результат: ~2x ускорение, ~40% экономия GPU RAM, качество не падает (потеря точности компенсируется GradScaler). Используй всегда при обучении на GPU. Единственное ограничение: некоторые операции (softmax, loss, нормализация) автоматически остаются в fp32 для стабильности.
Checkpoints — сохранение и загрузка модели
Обучение может упасть (OOM, kill процесса, баг). Сохраняй чекпоинты, чтобы не начинать сначала. state_dict — словарь {имя_параметра: тензор}. Сохраняй и модель, и оптимизатор, и scheduler.
# ─── Сохранение (каждые N эпох + лучшая модель) ─────────────────
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'best_acc': best_acc,
'scaler_state_dict': scaler.state_dict(), # если mixed precision
}
torch.save(checkpoint, f'checkpoint_epoch{epoch}.pt')
# ─── Загрузка (resume training) ─────────────────────────────────
checkpoint = torch.load('checkpoint_epoch5.pt', map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
start_epoch = checkpoint['epoch'] + 1
best_acc = checkpoint['best_acc']
# ─── Только для инференса (легковесный) ─────────────────────────
torch.save(model.state_dict(), 'model_weights.pt')
model.load_state_dict(torch.load('model_weights.pt', map_location=device))map_location — не забывай!
torch.load(..., map_location=device) — если обучал на GPU, а загружаешь на CPU (или другой GPU). Без этого получишь ошибку или модель уедет не на тот девайс.
GPU — базовые правила
Модель и данные должны быть на одном устройстве. Модель на GPU, данные на CPU → ошибка. Всегда: model.to(device) + x.to(device), y.to(device) внутри loop.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MyModel().to(device)
# Multi-GPU (простой вариант — DataParallel)
if torch.cuda.device_count() > 1:
model = torch.nn.DataParallel(model) # автоматически делит батч между GPU
# Внимание: model.module — оригинальная модель (для save/load)
# Мониторинг GPU
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(f"Memory: {torch.cuda.memory_allocated()/1e9:.1f} GB / {torch.cuda.get_device_properties(0).total_mem/1e9:.1f} GB")DataParallel — самый простой multi-GPU: реплицирует модель на каждый GPU, делит батч, собирает результаты. Минус: GPU 0 перегружен (собирает градиенты). Для серьёзного multi-GPU используй DistributedDataParallel (DDP) — каждый GPU в отдельном процессе, равномерная нагрузка, масштабируется линейно.
OOM на GPU?
torch.utils.checkpoint) — пересчитывает активации при backward вместо хранения. Медленнее на ~30%, но экономит 60-80% памяти.
5. Если ничего не помогает — нужна GPU побольше или multi-GPU.Inference — используем обученную модель
Два обязательных момента: model.eval() (выключить Dropout/BatchNorm training mode) и torch.no_grad() (не строить граф, экономить память).
# Inference — production-ready
model.load_state_dict(torch.load('best_model.pt', map_location=device))
model.eval()
@torch.inference_mode() # быстрее torch.no_grad(), PyTorch 1.9+
def predict(x: torch.Tensor) -> torch.Tensor:
x = x.to(device)
logits = model(x)
probs = torch.softmax(logits, dim=-1)
return probs.cpu() # результат обратно на CPU
# Для одного примера — добавь batch dimension
image = transform(pil_image).unsqueeze(0) # [C, H, W] → [1, C, H, W]
probs = predict(image)
predicted_class = probs.argmax(1).item()🎯 На собеседовании
Junior
Middle
Senior
model.module.state_dict() — сохраняешь оригинальную модель, не обёртку. Иначе при загрузке без DataParallel получишь ошибки ключей.Собираем всё вместе
Production-ready training loop: Dataset + DataLoader (num_workers, pin_memory) → forward → loss → backward → step → zero_grad → eval с model.eval() + no_grad() → checkpoints (model + optimizer + scheduler) → mixed precision (autocast + GradScaler) → gradient accumulation (если не хватает VRAM). Это покрывает 95% задач.
Если не хочешь писать boilerplate руками — используй PyTorch Lightning (абстрагирует loop, multi-GPU, logging) или HuggingFace Trainer (для NLP). Но пойми каждый шаг прежде чем использовать фреймворк — иначе не сможешь дебажить, когда что-то сломается.
Предыдущая нода: Оптимизация — SGD, Adam, schedulers, регуляризация. Дальше: применяй эти знания в конкретных архитектурах — CNN, RNN, Transformer.
Материалы
Официальный быстрый старт: тензоры, autograd, нейросеть, training loop. Обязательно к прочтению.
Лучшая статья о debugging training: от overfitting одного батча до полного пайплайна. Обязательно.
Официальный гайд по torch.amp: autocast, GradScaler, подводные камни.
Строим autograd с нуля. После этого видео forward/backward станут кристально понятны.