Оптимизация и регуляризация
SGD, Adam, LR schedulers, dropout, batch norm — как обучать нейросети эффективно.
Оптимизация нейросетей — от SGD до AdamW
Ты написал модель, выбрал loss, запустил обучение — а loss не падает, или падает, но медленно, или скачет как сумасшедший. Проблема почти всегда в оптимизаторе или learning rate. Оптимизатор — это алгоритм, который решает, как именно обновлять веса на каждом шаге. Выбор оптимизатора и его гиперпараметров — одно из самых важных решений при обучении нейросети.
SGD — стохастический градиентный спуск
Самый простой оптимизатор. На каждом шаге: вычисли градиент loss по весам, сдвинь веса в сторону антиградиента. Размер шага определяется learning rate (lr).
θ — веса, η — learning rate, ∇L — градиент loss. Простая и элегантная формула.
Проблемы чистого SGD: шумные градиенты (каждый mini-batch даёт немного разное направление), одинаковый lr для всех параметров (а некоторые параметры нуждаются в более агрессивном обновлении), застревание в седловых точках (градиент маленький, но это не минимум).
Momentum — добавляем инерцию
Идея: представь шарик, катящийся по поверхности loss. Чистый SGD телепортирует шарик на каждом шаге. Momentum даёт ему инерцию — шарик накапливает скорость в направлении, куда его постоянно толкают, и игнорирует кратковременные колебания.
v — «скорость» (экспоненциально взвешенная сумма градиентов), β ≈ 0.9 — коэффициент инерции.
Momentum ускоряет сходимость в 2-10 раз. Если 10 батчей подряд градиент указывает «вправо» — скорость растёт. Если направление меняется — скорость затухает. На практике SGD + Momentum — сильный baseline, особенно для CNN. Часто финальная точность выше, чем у Adam, но нужно дольше подбирать lr.
RMSProp → Adam → AdamW — адаптивные методы
RMSProp решает другую проблему: одинаковый lr для всех параметров. Идея: отслеживай среднеквадратичную величину градиентов для каждого параметра. Если градиенты для параметра большие — уменьшай шаг. Если маленькие — увеличивай. Каждый параметр получает свой эффективный lr. RMSProp — как GPS-навигатор: на узких улицах (параметры с большими градиентами) замедляется, на широких трассах (маленькие градиенты) ускоряется.
s — скользящее среднее квадратов градиентов. Каждый параметр получает свой «масштаб»: если градиенты большие — шаг маленький, и наоборот.
Adam (Adaptive Moment Estimation) = Momentum + RMSProp. Отслеживает и первый момент (среднее направление, как Momentum) и второй момент (среднеквадратичная величина, как RMSProp).
m — первый момент (среднее градиентов), v — второй момент (среднее квадратов). β₁ = 0.9, β₂ = 0.999.
Bias correction (m̂, v̂) компенсирует нулевую инициализацию. ε = 1e-8 предотвращает деление на 0.
Интуиция: m — это «куда мы шли последние N шагов» (усреднённое направление). v — «насколько сильно трясло на пути» (масштаб колебаний). Делим направление на масштаб = получаем нормализованный шаг. Если параметр «трясёт» (большая дисперсия градиентов) — шаг уменьшается. Если градиенты стабильны — шаг увеличивается.
AdamW — исправленная версия Adam. В обычном Adam weight decay (L2-регуляризация) работает некорректно: адаптивный lr «поглощает» штраф. AdamW декаплирует weight decay от адаптивного lr — штраф применяется напрямую к весам, а не через градиент. На практике AdamW даёт лучшую генерализацию, и это дефолтный выбор для трансформеров.
Какой оптимизатор выбрать?

Загрузка интерактивного виджета...
Загрузка интерактивного виджета...
Learning Rate Schedulers — управляем скоростью обучения
Scheduler — как расписание тренировок: первые недели бежишь быстро (высокий LR), ближе к финишу — точные, мелкие шаги (низкий LR). Фиксированный lr — плохая идея. В начале обучения нужен большой lr (быстро двигаемся к минимуму), в конце — маленький (точно настраиваемся). LR scheduler автоматически меняет lr по расписанию.
- StepLR — умножает lr на gamma каждые N эпох. Пример: lr×0.1 каждые 30 эпох. Просто, но грубо. Подходит для SGD на ResNet.
- CosineAnnealingLR — lr плавно убывает по косинусоиде от max до min. Гладкий, без резких скачков. Самый популярный для трансформеров.
- OneCycleLR — сначала lr РАСТЁТ (warmup), потом убывает. Одна «волна» за всё обучение. Позволяет использовать очень высокий peak lr. Часто даёт лучший результат за меньшее число эпох.
- Warmup — первые N шагов lr линейно растёт от 0 до целевого. Критичен для Adam/AdamW: без warmup начальные обновления слишком агрессивны (bias correction ещё не стабилизировалась). Типичный warmup = 5-10% от общего числа шагов.
import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR, OneCycleLR
# Типичный сетап: AdamW + Cosine Annealing + Warmup
optimizer = optim.AdamW(model.parameters(), lr=3e-4, weight_decay=0.01)
# Вариант 1: CosineAnnealing (нужен ручной warmup)
scheduler = CosineAnnealingLR(optimizer, T_max=num_epochs, eta_min=1e-6)
# Вариант 2: OneCycleLR (warmup встроен)
scheduler = OneCycleLR(
optimizer,
max_lr=3e-4,
epochs=num_epochs,
steps_per_epoch=len(train_loader), # шагаем КАЖДЫЙ батч!
pct_start=0.1, # 10% warmup
anneal_strategy='cos'
)
# В training loop:
for epoch in range(num_epochs):
for batch in train_loader:
loss = train_step(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler.step() # OneCycleLR — после КАЖДОГО шага!
# scheduler.step() # CosineAnnealing — после КАЖДОЙ эпохи!Частая ошибка
scheduler.step(). Модель обучается с постоянным lr, результаты хуже, а ты неделю ищешь баг в модели. Ещё одна ошибка: вызвать scheduler.step() не в том месте — OneCycleLR шагает после каждого батча, CosineAnnealing — после каждой эпохи.Регуляризация — не даём модели переобучиться
Оптимизатор минимизирует train loss. Но нас волнует val loss — качество на новых данных. Регуляризация ограничивает модель, чтобы она не запоминала обучающую выборку.
Dropout (p = 0.1–0.5) — случайно зануляет нейроны при обучении. При инференсе выключается (model.eval()). Для трансформеров стандарт p = 0.1. Для маленьких датасетов можно увеличить до 0.3–0.5.
Dropout — на каждом шаге обучения случайно «выключает» нейроны с вероятностью p (обычно 0.1–0.5). Зачем? Без dropout нейроны начинают со-адаптироваться — один нейрон учится полагаться на конкретного «соседа». Dropout ломает эту зависимость: каждый нейрон вынужден работать самостоятельно. Можно думать как ансамбль из 2^n подсетей — на каждом шаге активна случайная подсеть. На inference dropout отключается (все нейроны работают), но выходы умножаются на (1-p) для компенсации — или, чаще, используется inverted dropout (деление на (1-p) во время обучения).
BatchNorm — нормализует выход слоя по статистикам батча (среднее=0, дисперсия=1), потом масштабирует и сдвигает обучаемыми γ и β. Ускоряет обучение, действует как лёгкий регуляризатор (шум из-за mini-batch статистик). Стандарт для CNN.
Batch Normalization — нормализует выход слоя (среднее → 0, дисперсия → 1) по текущему мини-батчу, затем масштабирует обучаемыми параметрами γ и β. Зачем это нужно? Без BatchNorm каждый слой получает входы с меняющимся распределением (потому что предыдущие слои обновляют свои веса). Это как стрелять по движущейся мишени — слой не успевает адаптироваться. BatchNorm фиксирует мишень: распределение всегда ~N(0,1), а параметры γ и β позволяют сети самой решить оптимальный масштаб. Результат: можно использовать больший learning rate (стабильнее), обучение сходится быстрее, и есть лёгкий эффект регуляризации (шум от батча). ⚠️ На inference BatchNorm использует running statistics (накопленные за обучение), а не статистики текущего батча.
LayerNorm — нормализует по признакам (а не по батчу). Не зависит от batch size, работает при batch_size=1. Стандарт для трансформеров. Ставится внутри каждого attention-блока.
Weight Decay — штраф за большие веса. В AdamW: θ = θ − η·wd·θ на каждом шаге. Типичные значения: 0.01–0.1. Не применяй к bias и LayerNorm параметрам (они не должны быть маленькими).
Label Smoothing — вместо жёстких one-hot меток [0, 0, 1, 0] используем «размытые» [0.025, 0.025, 0.925, 0.025]. Предотвращает overconfidence модели, улучшает calibration. В PyTorch: nn.CrossEntropyLoss(label_smoothing=0.1).
# Правильный weight decay: не применять к bias и norm слоям
def get_param_groups(model, weight_decay=0.01):
decay, no_decay = [], []
for name, param in model.named_parameters():
if not param.requires_grad:
continue
# bias, LayerNorm, BatchNorm — без weight decay
if 'bias' in name or 'norm' in name or 'bn' in name:
no_decay.append(param)
else:
decay.append(param)
return [
{'params': decay, 'weight_decay': weight_decay},
{'params': no_decay, 'weight_decay': 0.0},
]
optimizer = optim.AdamW(get_param_groups(model), lr=3e-4)
Практические советы
LR Finder — метод Лесли Смита: начни с очень маленького lr (1e-7), экспоненциально увеличивай, записывай loss. Оптимальный lr — там, где loss падает быстрее всего (примерно в 10 раз меньше точки, где loss начинает расти). В PyTorch Lightning: tuner.lr_find(model). Экономит часы тюнинга.
Мониторинг gradient norms. Если норма градиентов взрывается (> 100) — нужен gradient clipping: torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0). Если градиенты затухают (< 1e-7) — lr слишком маленький или архитектура плохая (vanishing gradients).
Топ-5 ошибок в оптимизации
Визуализация: читаем loss curves
Loss curves — главный диагностический инструмент. Логируй train_loss и val_loss каждую эпоху (или чаще). Что они говорят:
- Train и val падают параллельно → всё хорошо, модель учится и обобщает.
- Train падает, val растёт → переобучение. Добавь регуляризацию, увеличь данные, уменьши модель.
- Обе не падают → lr слишком маленький, или модель слишком маленькая, или баг в коде.
- Loss скачет (spiking) → lr слишком большой. Уменьши lr или добавь gradient clipping.
- Loss = NaN → lr слишком большой, или числовая нестабильность. Проверь данные на NaN, уменьши lr.
- Train и val одинаковые → модель underfitting. Увеличь модель, уменьши регуляризацию, обучай дольше.
Помимо loss, логируй gradient norm (среднеквадратичная норма градиентов), learning rate (убедись что scheduler работает), accuracy / метрику на val. Используй Weights & Biases (wandb) или TensorBoard — без визуализации ты летишь вслепую.
# Логирование gradient norm — встраивай в training loop
total_norm = 0.0
for p in model.parameters():
if p.grad is not None:
total_norm += p.grad.data.norm(2).item() ** 2
total_norm = total_norm ** 0.5
print(f"Gradient norm: {total_norm:.4f}")
# Gradient clipping — ставь ПЕРЕД optimizer.step()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)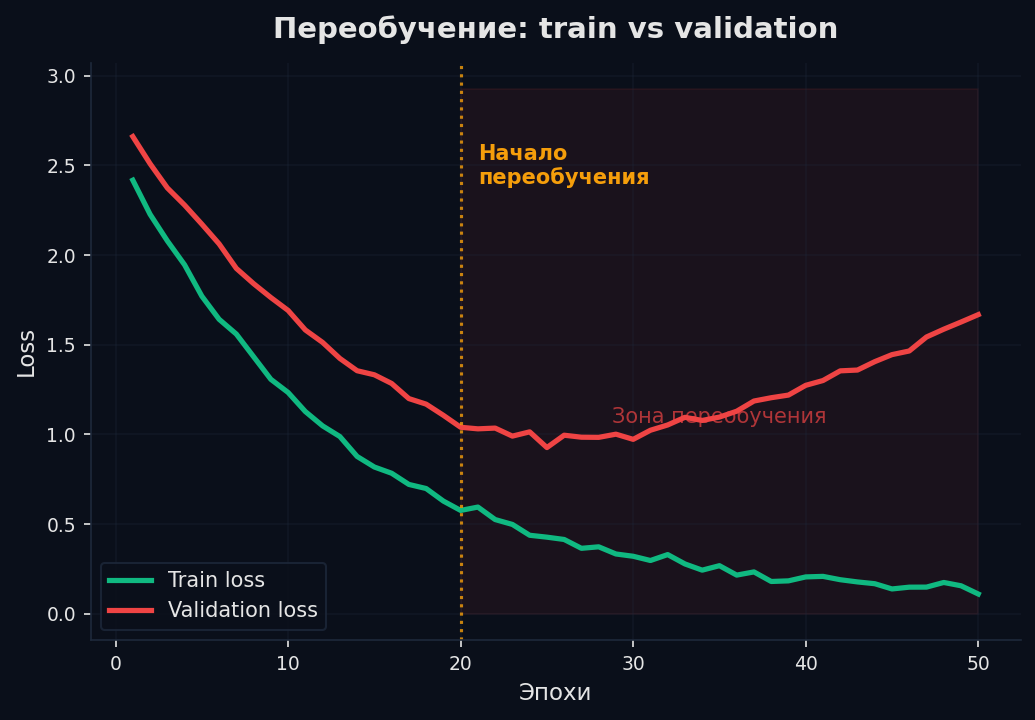
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Рецепт по умолчанию: AdamW (lr=3e-4, wd=0.01) + CosineAnnealing или OneCycleLR + warmup (5-10% шагов) + gradient clipping (max_norm=1.0). Для CNN: SGD + Momentum (lr=0.1, momentum=0.9) + StepLR. Регуляризация: Dropout (0.1-0.3) + weight decay (без bias/norm).
Главное: логируй всё (loss, lr, gradient norm), начинай с проверенных дефолтов, и только потом тюнь. LR finder экономит часы. Loss curves — твой главный диагностический инструмент. Если loss не падает — 80% что проблема в lr или баге, а не в архитектуре.
Дальше: Training Loop — как собрать полный цикл обучения на PyTorch (Dataset, DataLoader, train/eval loop, checkpoints, mixed precision).
Материалы
Конспекты Карпати: learning rate, оптимизаторы, регуляризация, мониторинг обучения. Золотой стандарт.
Все оптимизаторы и schedulers в PyTorch. Обязательная справка.
Практические советы от Карпати: как отлаживать обучение, на что смотреть, что ломается.
Оригинальная статья AdamW — почему L2 в Adam не работает и как это исправить.