Transformer Architecture
Интерактивный гайд: от проблемы seq2seq до GPT и BERT. Визуализируйте attention weights, исследуйте positional encoding, наблюдайте causal mask в действии.
Зачем нужен Transformer?
До 2017 года задачи обработки последовательностей (перевод, суммаризация, генерация текста) решались с помощью RNN (LSTM, GRU) и seq2seq моделей с attention. Но у RNN было две фундаментальные проблемы:
Последовательная обработка
RNN обрабатывает токены по одному: токен t зависит от токена t−1. Невозможно распараллелить → медленное обучение на длинных последовательностях.
Затухание градиентов
Информация о далёких токенах «затухает» при проходе через много шагов. LSTM частично решает это, но для 1000+ токенов всё равно проблемы.
В 2017 году Vaswani et al. представили статью "Attention Is All You Need", предложив архитектуру Transformer — полностью основанную на механизме внимания, без рекуррентных связей. Это позволило параллельно обрабатывать все позиции и эффективно моделировать зависимости на любом расстоянии.
Историческое значение
Transformer стал основой для GPT, BERT, T5, LLaMA, и по сути всех современных языковых моделей. Идея self-attention оказалась настолько универсальной, что Transformer адаптировали и для компьютерного зрения (ViT), аудио (Whisper), белков (AlphaFold) и генерации изображений (DiT).
Общая архитектура Encoder-Decoder
Оригинальный Transformer состоит из двух частей: Encoder (кодирует входную последовательность) и Decoder (генерирует выходную последовательность токен за токеном).
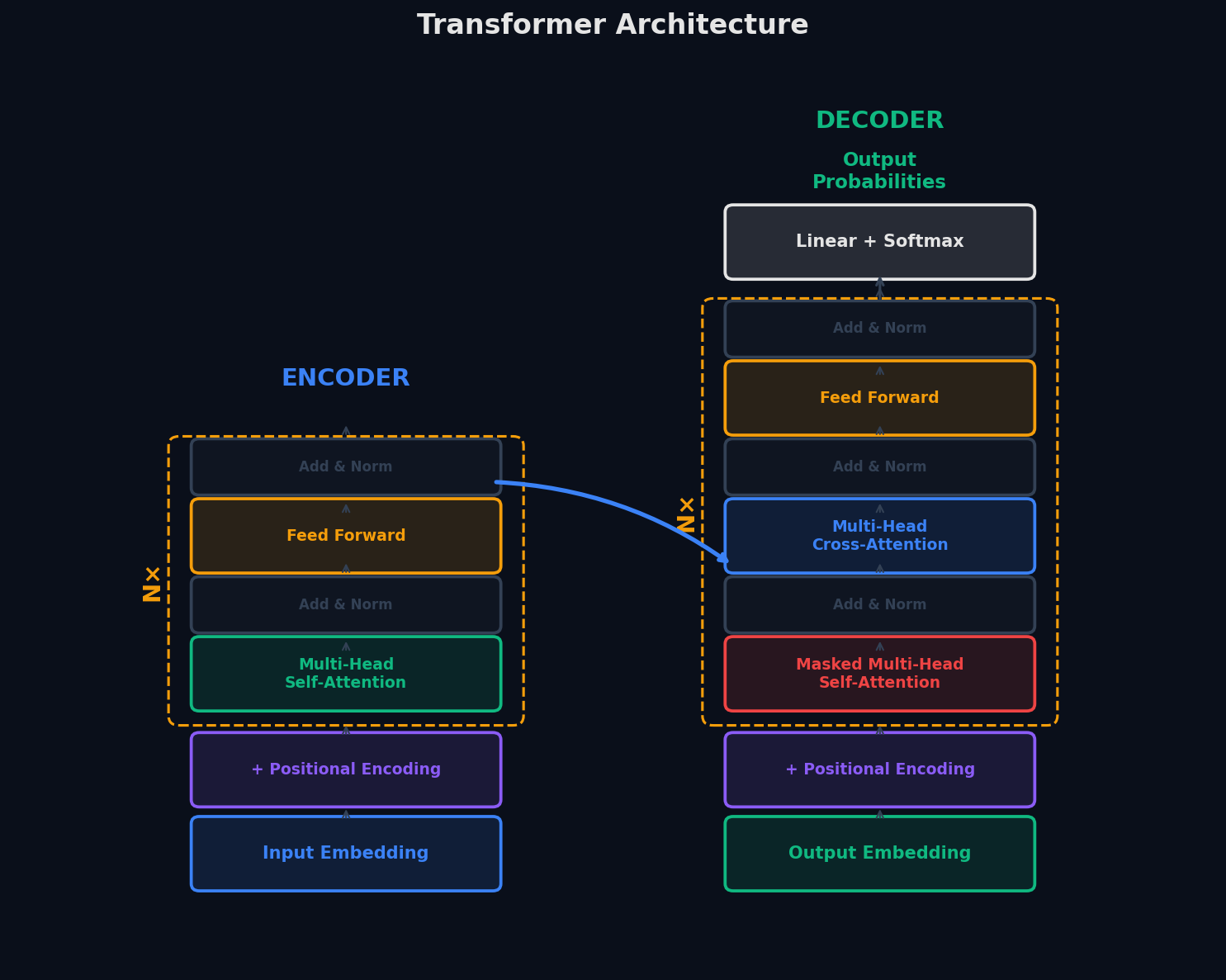
И encoder, и decoder состоят из N одинаковых слоёв (в оригинале N=6). Каждый слой encoder содержит:
- Multi-Head Self-Attention — каждый токен «смотрит» на все остальные
- Feed-Forward Network — полносвязная сеть, применяемая к каждой позиции независимо
- Residual connections + Layer Norm — вокруг каждого подслоя
Decoder содержит те же компоненты плюс Cross-Attention — слой, который обращает внимание на выход encoder.
Ключевое отличие от RNN
В Transformer все позиции обрабатываются параллельно. Нет «скрытого состояния», передаваемого от шага к шагу. Вместо этого — self-attention позволяет каждому токену напрямую взаимодействовать с каждым другим.
Embeddings + Positional Encoding
Поскольку Transformer не имеет рекуррентности, он не знает порядок токенов — для него "кот ел рыбу" и "рыбу ел кот" неразличимы без дополнительной информации. Поэтому к embedding каждого токена добавляется Positional Encoding — вектор, кодирующий позицию.
В оригинальной статье используются синусоидальные функции с разными частотами:
Чётные измерения: синус
Нечётные измерения: косинус
Каждое измерение embedding использует синусоиду с разной частотой. Низкие измерения (малые i) — высокая частота (быстрая осцилляция). Высокие измерения — низкая частота. Это создаёт уникальный «отпечаток» для каждой позиции.
Почему именно sin/cos?
Vaswani et al. выбрали эту схему потому что PE(pos+k) можно выразить как линейную функцию от PE(pos) — модель потенциально может учить относительные позиции. В BERT используют обучаемые позиционные embeddings, а в RoPE (LLaMA) — повороты в комплексной плоскости.
Self-Attention (Scaled Dot-Product)
Self-Attention — сердце Transformer. Каждый токен создаёт три вектора: Query (что я ищу?), Key (что я предлагаю?), Value (что я содержу?).
Линейные проекции входных embeddings в пространства Q, K, V
Attention score между токенами i и j — это скалярное произведение q_i и k_j, нормализованное на √d_k (размерность ключа). Затем softmax превращает scores в веса, и взвешенная сумма values даёт финальный output:
Scaled Dot-Product Attention — основная формула
Деление на √d_k необходимо для стабилизации градиентов: без нормализации скалярные произведения растут с размерностью, и softmax насыщается (все веса → 0 или 1).
Аналогия: поиск в базе данных
Query = поисковый запрос. Keys = заголовки документов. Вы вычисляете «релевантность» запроса к каждому документу (QK^T), нормализуете (softmax), и берёте взвешенную комбинацию содержимого документов (Values).
Softmax превращает вектор scores в распределение вероятностей:
Softmax: экспоненциальная нормализация
Multi-Head Attention
Одна «голова» attention может сфокусироваться только на одном типе взаимодействия (например, синтаксическая связь). Чтобы модель одновременно улавливала разные паттерны, Multi-Head Attention запускает h независимых attention-голов параллельно:
Конкатенация выходов всех голов + линейная проекция
Каждая голова имеет свои проекционные матрицы
В оригинальном Transformer: d_model=512, h=8 голов, каждая работает в d_k = d_model/h = 64 измерениях. Суммарная вычислительная сложность примерно такая же, как у одной «полноразмерной» attention головы.
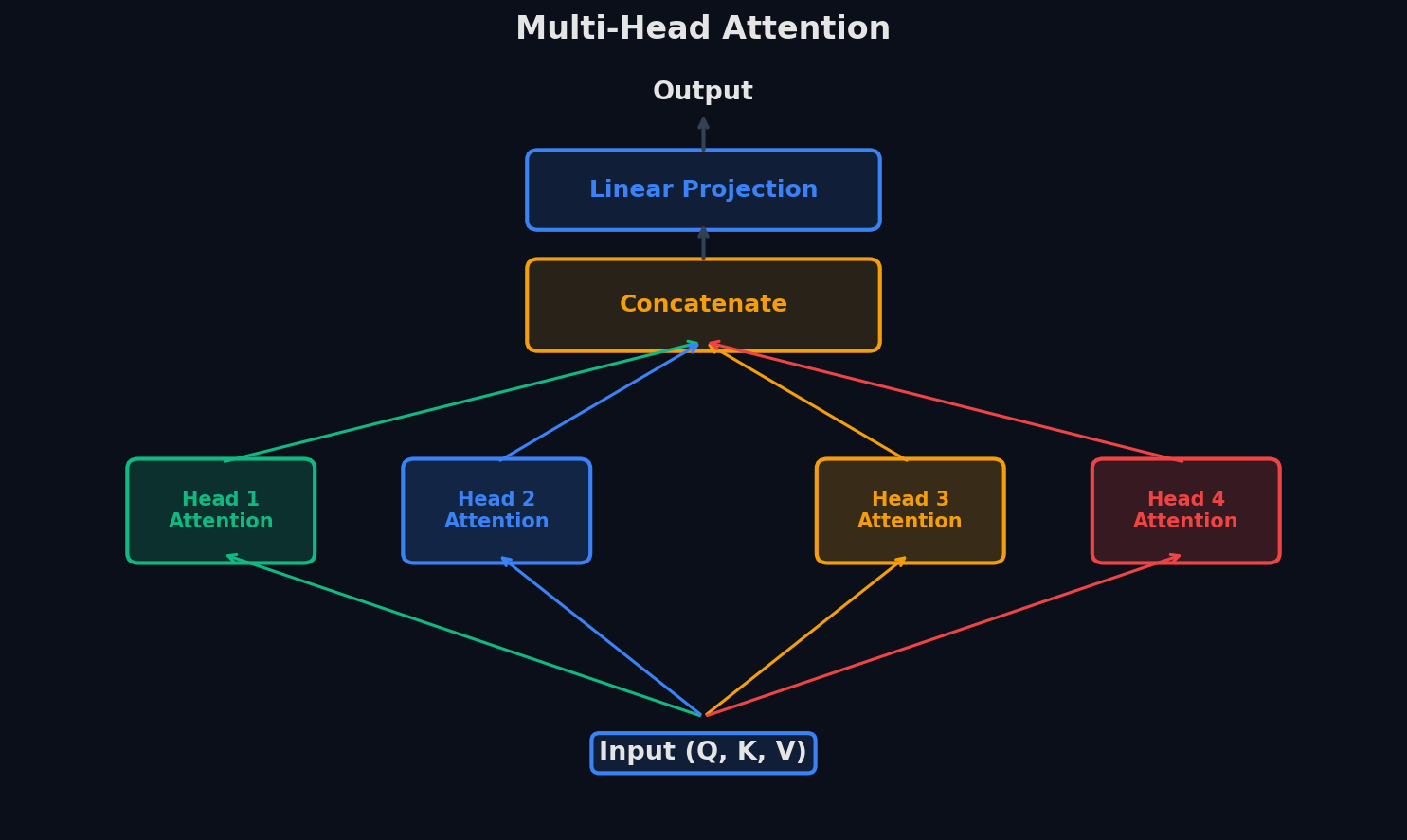
Что учат разные головы?
Исследования показывают, что головы специализируются: одни отслеживают синтаксические зависимости (подлежащее→сказуемое), другие — позиционную близость, третьи — coreference (местоимение→антецедент). Это emergent behavior — никто не программирует роли, головы находят полезные паттерны сами.
Feed-Forward Network, Layer Norm, Residual Connections
После Multi-Head Attention выход проходит через Position-wise FFN — полносвязную сеть, применяемую к каждой позиции независимо (один и тот же набор весов для всех позиций):
Feed-Forward Network (оригинал). В GPT/LLaMA: GELU или SwiGLU вместо ReLU
Внутренняя размерность FFN обычно в 4 раза больше d_model: d_ff = 4 × d_model = 2048. Это «расширение» позволяет модели выучить нелинейные трансформации представлений.
Residual Connections добавляют вход подслоя к его выходу: output = x + Sublayer(x). Это решает проблему затухания градиентов в глубоких сетях (аналогично ResNet).
Post-Norm (оригинал). Pre-Norm: LayerNorm(x) → Sublayer → + x
Layer Normalization нормализует активации по последнему измерению (d_model) для каждого токена независимо. Стабилизирует обучение, особенно в глубоких моделях.
μ и σ² — среднее и дисперсия по d_model; γ, β — обучаемые параметры
Residual Stream (1 слой Encoder)
«+» = residual connection. Информация течёт и через подслои, и напрямую через skip connections.
Pre-Norm vs Post-Norm
Оригинальный Transformer использует Post-Norm: LN(x + Sublayer(x)). Современные модели (GPT-2+, LLaMA) используют Pre-Norm: x + Sublayer(LN(x)). Pre-Norm стабильнее, не требует learning rate warmup.
Decoder: Masked Attention + Cross-Attention
Decoder отличается от Encoder двумя важными аспектами:
1. Masked Self-Attention (Causal Mask)
При генерации токена на позиции t модель не должна «подсматривать» в будущее. Все позиции j > t маскируются: score(t, j) = −∞ → softmax даёт 0. Результат — нижнетреугольная матрица attention. Это обеспечивает корректную авторегрессионную генерацию.
2. Cross-Attention (Encoder-Decoder Attention)
Queries приходят из decoder, а Keys и Values — из выхода encoder. Это позволяет каждому генерируемому токену «обращать внимание» на входную последовательность. Например, при переводе "Hello world" → "Привет мир": decoder на позиции "мир" обращает внимание на "world" в encoder.
Cross-Attention: Q от decoder, K и V от encoder
Порядок подслоёв в каждом слое Decoder:
- Masked Multi-Head Self-Attention + Add & Norm
- Multi-Head Cross-Attention + Add & Norm
- Feed-Forward Network + Add & Norm
Авторегрессионная генерация
Decoder работает шаг за шагом: на каждом шаге подаёт все сгенерированные токены, предсказывает следующий, добавляет его к входу и повторяет. Causal mask гарантирует, что при обучении (когда весь target известен) модель не «жульничает».
Современные варианты Transformer
Оригинальная Encoder-Decoder архитектура трансформировалась в три основных семейства:
| Encoder-only | Decoder-only | Encoder-Decoder | |
|---|---|---|---|
| Модели | BERT, RoBERTa, DeBERTa | GPT, LLaMA, Mistral | T5, BART, mT5 |
| Attention | Bidirectional (видит всё) | Causal (видит только прошлое) | Bidirectional + Causal |
| Обучение | MLM (маскированные токены) | Next-token prediction | Span corruption / denoising |
| Задачи | Классификация, NER, QA | Генерация текста, чат | Перевод, суммаризация |
| Преимущества | Глубокое понимание контекста | Масштабируемость, universality | Гибкость формата |
Decoder-only модели (GPT, LLaMA) доминируют в 2023–2025. Основная идея: одна простая цель обучения (предсказание следующего токена) и масштабирование данных + параметров. Scaling laws (Kaplan et al.) показали, что performance растёт предсказуемо с ростом модели.
На собеседовании
Частые вопросы: (1) Чем отличается BERT от GPT? (Bidirectional vs Causal attention). (2) Почему GPT не может делать MLM? (Causal mask не позволяет видеть будущие токены). (3) Зачем scaling? (Scaling laws, emergent abilities при росте параметров).
Загрузка интерактивного виджета...