ML System Design для RecSys
Проектирование рекомендательной системы от требований до деплоя.
ML System Design для RecSys — проектируем от требований до деплоя
Загрузка интерактивного виджета...
На собеседовании часто дают задачу: «Спроектируй рекомендательную систему для X». Это не про код — это про архитектуру, компромиссы, и понимание того, как все части работают вместе.
Фреймворк ответа на system design
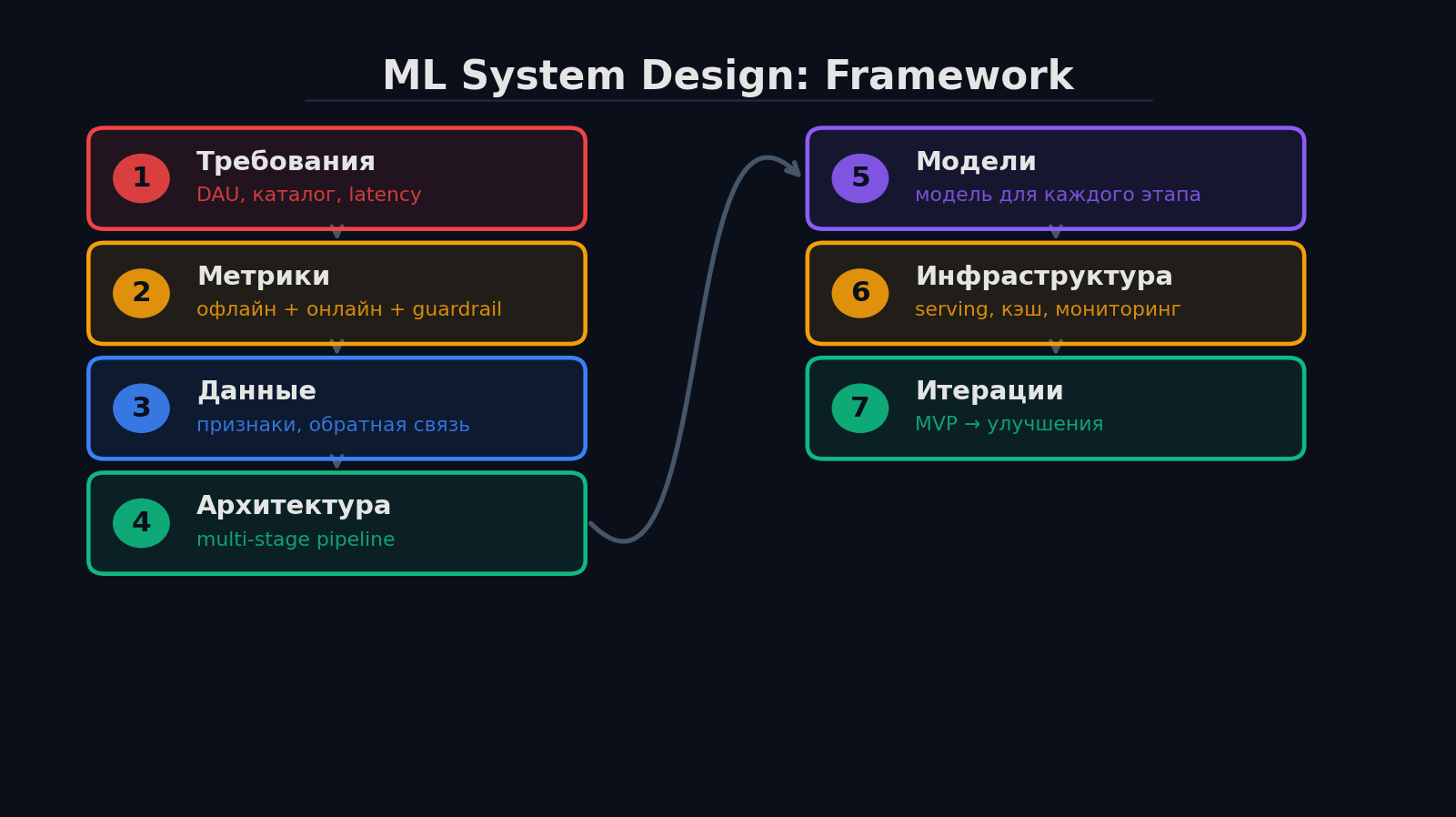
Следуй структуре, не прыгай сразу к моделям:
- 1. Уточни требования: DAU, каталог, latency, бизнес-цель
- 2. Метрики: офлайн (NDCG, HR@K) + онлайн (CTR, retention, GMV)
- 3. Данные: какие есть, неявная/явная обратная связь, признаки
- 4. Архитектура: multi-stage pipeline (candidate gen → ranking → re-ranking)
- 5. Модели: для каждого этапа — конкретная модель и почему
- 6. Инфраструктура: serving, кэширование, обновление, мониторинг
- 7. Итерации: с чего начать (MVP), как улучшать
Пример: рекомендации товаров для маркетплейса
Задача: спроектировать рекомендации на главной странице маркетплейса с 5М товаров и 2М DAU.
Шаг 1: Требования
Шаг 2: Метрики
# Capacity estimation для рекомендательного сервиса
from dataclasses import dataclass
@dataclass
class SystemDesignEstimate:
"""Шаблон расчёта нагрузки для system design интервью."""
dau: int =
requests_per_user: int = 5
catalog_size: int =
embedding_dim: int = 128
@property
def daily_requests(self) -> int:
return self.dau * self.requests_per_user # 10M
@property
def peak_rps(self) -> float:
return self.daily_requests / 86400 * 3 # ~347 RPS
@property
def ann_index_size_gb(self) -> float:
return self.catalog_size * self.embedding_dim * 4 / 1e9 # ~2.6 GB
@property
def feature_store_size_gb(self) -> float:
return (self.dau * 1024 + self.catalog_size * 512) / 1e9 # ~4.5 GB
@property
def min_instances(self) -> int:
return max(2, int(self.peak_rps / 200) + 1) # 200 RPS per instance
est = SystemDesignEstimate()
# Peak RPS: 347, ANN index: 2.6 GB, Feature store: 4.5 GB, Min instances: 3Шаг 3-4: Данные и архитектура

- Candidate gen: Two-Tower (личные) + item-CF (похожие) + популярное. ~1000 кандидатов за 20мс
- Ranking: CatBoost с 50+ признаками (user, item, context, cross). 1000 → 30 кандидатов за 50мс
- Re-ranking: MMR для diversity + бизнес-правила (промо, stock > 0, min 3 категории)
- Feature Store: Redis (онлайн-фичи за <1мс), S3 (офлайн). Feast для train-serving consistency
Шаг 5: MVP и итерации
Не проектируй идеальную систему сразу. MVP: популярное + item-based CF + простое ранжирование по CTR. Запускаешь, собираешь данные, считаешь метрики. Потом итеративно: Two-Tower, тяжёлое ранжирование с Feature Store, A/B-тесты каждого изменения.
# Конфигурация рекомендательного пайплайна
recsys_config = {
"candidate_generation": {
"sources": [
{"name": "two_tower", "model": "tt_v3.2", "k": 500, "weight": 0.5},
{"name": "item_cf", "model": "als_v2", "k": 300, "weight": 0.3},
{"name": "popular", "strategy": "7d_trending", "k": 200, "weight": 0.2},
],
"total_candidates": 1000,
"timeout_ms": 30,
},
"ranking": {
"model": "catboost_rank_v4.1",
"n_features": 87,
"timeout_ms": 80,
},
"reranking": {
"diversity": {"method": "mmr", "lambda": 0.6},
"business_rules": [
{"rule": "min_categories", "value": 3},
{"rule": "boost_new", "days": 7, "factor": 1.2},
{"rule": "filter_oos", "field": "stock"},
],
"k": 20,
},
"serving": {
"sla_p99_ms": 200,
"min_replicas": 3,
"fallback": "popularity",
},
}Мониторинг и дрифт
Модель деградирует со временем: вкусы меняются, каталог обновляется, появляются сезонные тренды. Мониторинг: следи за online-метриками (CTR, время сессии) и за распределением признаков (data drift). Если CTR упал на 5% — алерт и расследование.
- Модель переобучать регулярно: раз в день/неделю в зависимости от скорости изменения данных
- A/B-тест каждого значимого изменения — не выкатывай без проверки
- Shadow mode: новая модель работает параллельно, но результаты не показываются
- Логирование: сохраняй feature values на момент предсказания — нужны для дебага и off-policy оценки
Типичные ошибки на собесе
🎯 Суть для собеса