Neural Collaborative Filtering
NCF, GMF, MLP-based подходы — переход от матричной факторизации к нейросетям.
Neural Collaborative Filtering — когда линейности недостаточно
Загрузка интерактивного виджета...
Матричная факторизация — мощный инструмент: раскладываем матрицу взаимодействий на два набора эмбеддингов и предсказываем через скалярное произведение. Но скалярное произведение — это линейная операция. Оно предполагает, что вклад каждого латентного фактора суммируется независимо. А реальные предпочтения так не работают.
Представь: пользователь любит научную фантастику (фактор 1 высокий) и комедии (фактор 2 высокий). Матричная факторизация предскажет, что ему понравится фильм, который одновременно sci-fi и комедия. Но что если на самом деле ему нравятся *или* серьёзная фантастика, *или* чистые комедии, а sci-fi комедии он терпеть не может? Скалярное произведение такую нелинейную комбинацию факторов не поймает — для этого нужна нейросеть.
Neural Collaborative Filtering (NCF) — семейство подходов, где скалярное произведение заменяется на нейронную сеть. Это даёт модели свободу выучить произвольную функцию взаимодействия между пользователем и айтемом. В этой ноде разберём три ключевые архитектуры (GMF, MLP, NeuMF), negative sampling для implicit feedback, two-tower подход для production и практическую реализацию на PyTorch.
Большая картина: от эмбеддингов к предсказанию
Любая нейросетевая CF-модель следует одной схеме: 1. Embedding lookup — пользователь и айтем превращаются в плотные вектора через таблицы эмбеддингов (nn.Embedding) 2. Interaction function — вектора комбинируются: поэлементное умножение, конкатенация, что угодно 3. Neural layers — результат проходит через один или несколько слоёв нейросети 4. Prediction — финальный скор (вероятность взаимодействия) Матричная факторизация — частный случай этой схемы, где шаги 2-3 сведены к dot product. NCF обобщает её, заменяя dot product на обучаемую нейросеть.
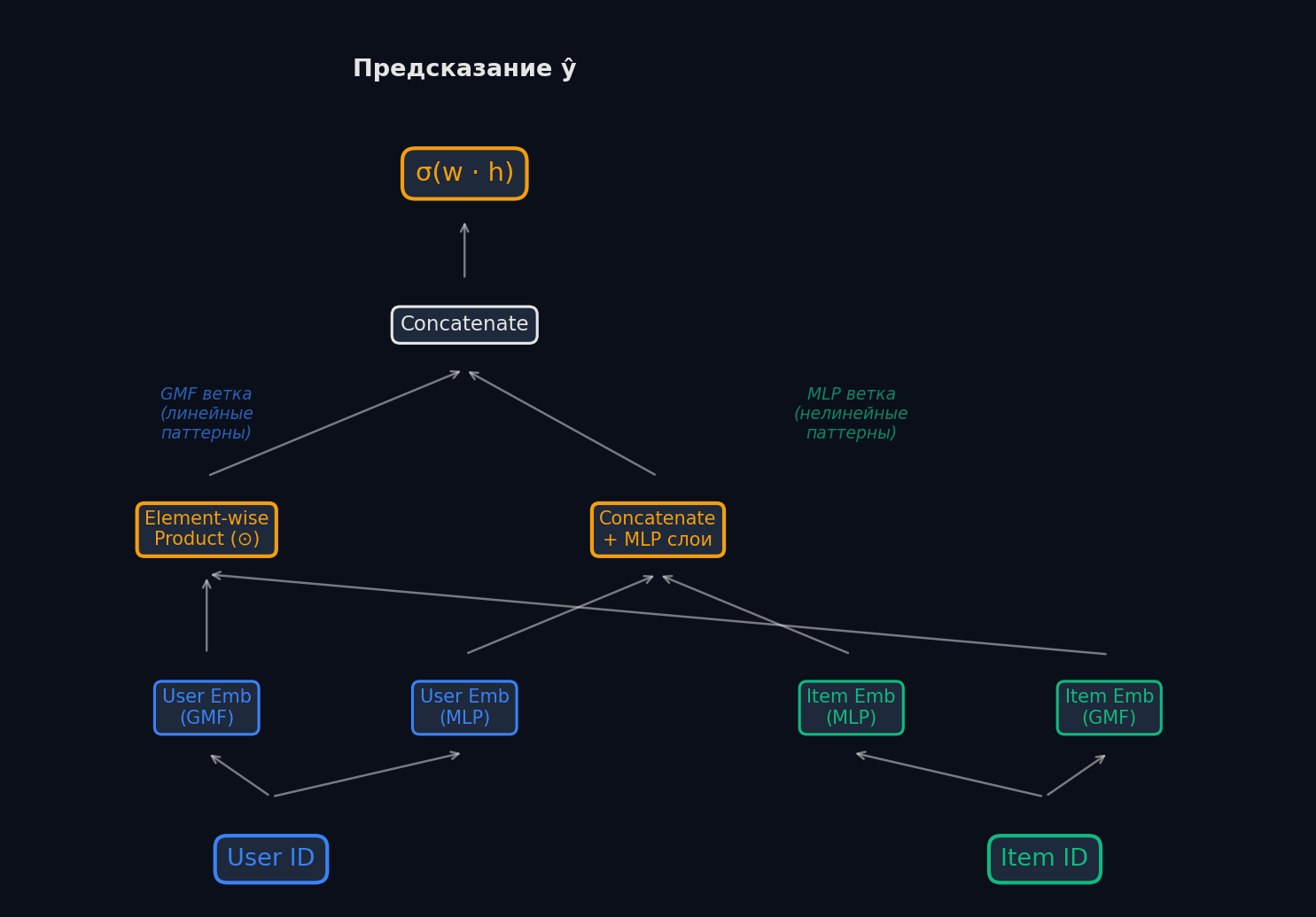

GMF — Generalized Matrix Factorization
GMF — первый кирпичик NCF. Идея: вместо фиксированного скалярного произведения берём поэлементное умножение (element-wise product, ⊙) эмбеддингов и пропускаем результат через линейный слой с активацией.
p_u — эмбеддинг пользователя, q_i — эмбеддинг айтема, ⊙ — поэлементное умножение, h — обучаемый вектор весов, σ — сигмоида
Зачем вектор h? Если h = [1, 1, …, 1], то GMF сводится к обычной матричной факторизации (dot product). Но h обучаемый — он позволяет модели придавать разные веса разным латентным факторам. Фактор «жанр» может быть важнее фактора «год выпуска» — h это выучит. GMF — мост между классической MF и полноценным нейросетевым подходом.
MLP-ветка — нелинейные взаимодействия через полносвязную сеть
GMF ловит взвешенные поэлементные паттерны, но взаимодействие между разными измерениями эмбеддингов остаётся линейным. MLP-ветка решает эту проблему: конкатенируем эмбеддинги пользователя и айтема и пропускаем через несколько полносвязных слоёв с нелинейными активациями.
z₀ — конкатенация эмбеддингов, z_l — выход l-го слоя, L — число слоёв. Типичная архитектура: сужающаяся «воронка» (например, 128→64→32)
Почему конкатенация, а не поэлементное умножение? Конкатенация сохраняет всю информацию из обоих эмбеддингов и позволяет сети самой выучить, как их комбинировать. Поэлементное умножение фиксирует структуру взаимодействия (i-й фактор user с i-м фактором item). MLP через конкатенацию может выучить произвольные кросс-факторные зависимости: «фактор 3 у пользователя + фактор 7 у айтема → высокий скор».
Архитектура MLP обычно строится как сужающаяся башня: каждый следующий слой вдвое меньше предыдущего (tower pattern). Это заставляет сеть постепенно сжимать информацию, выделяя самые важные паттерны. Например, для эмбеддингов размерности 64: concat(64, 64) = 128 → 64 → 32 → 16 → 1.
NeuMF — объединение GMF и MLP
GMF хорош в линейных паттернах, MLP — в нелинейных. NeuMF (Neural Matrix Factorization) объединяет их: обе ветки работают параллельно, каждая со своими эмбеддингами, а их выходы конкатенируются и проходят через финальный слой.
Выход GMF (поэлементное произведение) и выход последнего слоя MLP конкатенируются → линейный слой → сигмоида
Ключевой момент: у GMF и MLP разные эмбеддинги. Это не случайность — если использовать одни и те же эмбеддинги, модель будет ограничена: оптимальные эмбеддинги для dot product и для MLP — разные. Разделение даёт каждой ветке свободу выучить свои представления.
Pretrain → Fine-tune. Авторы NCF (He et al., 2017) предложили двухэтапное обучение: 1. Pretrain: обучаем GMF и MLP по отдельности до сходимости 2. Объединяем: инициализируем NeuMF весами pretrained GMF и MLP 3. Fine-tune: дообучаем NeuMF целиком с маленьким learning rate Это важно, потому что случайная инициализация объединённой модели может застрять в плохом локальном минимуме. Pretrain даёт хорошую стартовую точку.
Negative sampling — откуда взять «плохие» примеры
В implicit feedback у тебя есть только положительные сигналы: клики, покупки, просмотры. Пользователь не кликнул на товар — это значит, что товар ему не нравится? Или что он его не видел? Ты не знаешь. Но модели нужны и «нулевые» пары для обучения — иначе она выучит предсказывать 1 для всего.
Negative sampling — берём случайные пары (user, item), с которыми пользователь не взаимодействовал, и используем как негативные примеры. Обычно на каждый положительный пример сэмплируем 4-10 негативных. Это превращает задачу в бинарную классификацию: отличить реальные взаимодействия от случайных пар.
Uniform vs Popularity-based sampling: • Uniform — каждый несмотренный айтем с равной вероятностью. Просто, но большинство негативов будут очевидно нерелевантными (рэкомендуем бабушке тяжёлый метал — модель легко различает). • Popularity-based — чаще сэмплируем популярные айтемы как негативы. Логика: если пользователь *не* взаимодействовал с популярным айтемом, который он наверняка *видел* — это более «информативный» негатив. Модели приходится выучить тонкие различия, а не очевидные. На практике: popularity-based с вероятностью ∝ (freq)^0.75 (сглаженная частота) даёт лучшие результаты, чем uniform.
⚠️ Ловушка negative sampling
Two-Tower модель — архитектура для production
NeuMF красиво работает в офлайне, но есть проблема: для предсказания нужно прогнать пару (user, item) через MLP. Если у тебя 100 миллионов айтемов и нужно найти топ-100 за 50мс — прогнать 100M пар через нейросеть физически невозможно.
Two-tower (двухбашенная) модель решает это архитектурно: • User tower — энкодер пользователя: берёт user_id, историю, признаки → выдаёт user-вектор • Item tower — энкодер айтема: берёт item_id, атрибуты → выдаёт item-вектор • Скор — dot product или косинус между векторами Ключевое отличие от NeuMF: башни независимы. Нет общих слоёв, которые видят user и item одновременно. Это ограничивает выразительность (нет нелинейного взаимодействия на этапе retrieval), но даёт огромное преимущество в скорости.
Почему это быстро? Item-вектора вычисляются заранее (офлайн) и складываются в индекс приближённого поиска ближайших соседей (ANN — Approximate Nearest Neighbors). При запросе нужно вычислить только user-вектор (один forward pass) и найти ближайшие item-вектора в индексе. ANN-библиотеки (FAISS, ScaNN, HNSW) находят топ-100 из 100M за единицы миллисекунд.
Two-tower — стандартная архитектура для candidate generation (первый этап рекомендаций). Она отбирает тысячи кандидатов из миллионов, а затем более сложная модель (с кросс-фичами, attention, контекстом) ранжирует их в финальный топ.
Размерность эмбеддингов — как выбрать
Размерность эмбеддингов (embedding dim) — ключевой гиперпараметр. Типичные значения: 32-256. Trade-offs: • Маленький dim (16-32): быстро обучается, мало памяти, меньше переобучения. Но может не хватить «ёмкости» — модель не сможет выразить сложные предпочтения. Подходит для малых каталогов (< 100K айтемов). • Большой dim (128-256): больше выразительности, ловит тонкие паттерны. Но: (1) больше параметров → нужно больше данных, иначе переобучение; (2) ANN-поиск замедляется; (3) хранение 100M айтемов × 256 float32 = ~100 GB. • Эмпирическое правило: dim ≈ (число уникальных айтемов)^(1/4). Для 1M айтемов — около 32. Для 100M — около 100.
В two-tower моделях размерность ещё критичнее: она определяет размер ANN-индекса и скорость поиска. Поэтому в production часто используют Product Quantization (PQ) — сжатие векторов, которое уменьшает размер индекса в 4-16× с минимальной потерей качества.
Практика: NeuMF на PyTorch
import torch
import torch.nn as nn
class NeuMF(nn.Module):
def __init__(self, n_users: int, n_items: int,
gmf_dim: int = 32, mlp_dim: int = 32,
mlp_layers: list[int] = [64, 32, 16]):
super().__init__()
# GMF ветка — свои эмбеддинги
self.gmf_user = nn.Embedding(n_users, gmf_dim)
self.gmf_item = nn.Embedding(n_items, gmf_dim)
# MLP ветка — свои эмбеддинги
self.mlp_user = nn.Embedding(n_users, mlp_dim)
self.mlp_item = nn.Embedding(n_items, mlp_dim)
# MLP слои: сужающаяся башня
layers = []
input_dim = mlp_dim * 2 # конкатенация
for hidden in mlp_layers:
layers += [nn.Linear(input_dim, hidden), nn.ReLU(), nn.Dropout(0.2)]
input_dim = hidden
self.mlp = nn.Sequential(*layers)
# Финальный слой: GMF_out + MLP_out → 1
self.head = nn.Linear(gmf_dim + mlp_layers[-1], 1)
def forward(self, user_ids, item_ids):
# GMF: поэлементное умножение
gmf_out = self.gmf_user(user_ids) * self.gmf_item(item_ids)
# MLP: конкатенация → башня
mlp_input = torch.cat([
self.mlp_user(user_ids),
self.mlp_item(item_ids)
], dim=-1)
mlp_out = self.mlp(mlp_input)
# Объединяем и предсказываем
combined = torch.cat([gmf_out, mlp_out], dim=-1)
return torch.sigmoid(self.head(combined)).squeeze(-1)
# ---------- Обучение ----------
model = NeuMF(n_users=10000, n_items=50000)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.BCELoss()
# Пример батча: positive + negative пары
user_ids = torch.tensor([0, 0, 1, 1, 2, 2])
item_ids = torch.tensor([10, 999, 20, 888, 30, 777])
labels = torch.tensor([1., 0., 1., 0., 1., 0.]) # 1=клик, 0=негатив
preds = model(user_ids, item_ids)
loss = loss_fn(preds, labels)
loss.backward()
optimizer.step()Обрати внимание: у GMF и MLP разные таблицы эмбеддингов (gmf_user/gmf_item vs mlp_user/mlp_item). Это принципиально — каждая ветка учит свои представления. MLP-ветка строится как сужающаяся башня с Dropout для регуляризации. В production добавь: batch-негативы (вместо случайных), learning rate scheduler, early stopping по NDCG на валидации.
MF vs NCF — когда нейросети оправданы
Rendle et al. (2020) показали в статье «Neural Collaborative Filtering vs. Matrix Factorization Revisited», что хорошо настроенный MF бьёт наивный NCF. Это важный урок: архитектура ≠ автоматическое качество. Когда использовать что: • MF достаточно: мало данных (< 1M взаимодействий), нет side features, нужна скорость и простота. MF с правильной регуляризацией — сильный бейзлайн. • NCF оправдан: миллионы взаимодействий, есть дополнительные фичи (можно добавить к эмбеддингам), MF-бейзлайн «упёрся в потолок», есть GPU для обучения. В production чаще всего used two-tower как candidate generation + более сложная модель (GBDT, deep cross-network, transformer) как ranker.
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
Neural CF — это семейство моделей, которые заменяют линейное скалярное произведение в матричной факторизации на нейросеть. GMF обобщает MF через обучаемые веса поэлементного произведения. MLP ловит нелинейные взаимодействия через конкатенацию + полносвязные слои. NeuMF объединяет оба подхода.
Если запомнить одну вещь: архитектура без правильного обучения — ничто. Negative sampling, embedding dimension, pretrain/fine-tune — эти «скучные» детали определяют качество больше, чем выбор между GMF и MLP. А в production решает не мощность модели, а скорость inference — поэтому two-tower с ANN доминирует как candidate generation.
Дальше: Two-Tower подробно разберёт архитектуру двухбашенной модели и ANN-индексы, а Sequential RecSys покажет, как учитывать порядок взаимодействий через attention-механизмы.
Материалы
Оригинальная статья NCF: GMF, MLP, NeuMF. Обязательна к прочтению.
Критический анализ: правильно настроенный MF бьёт наивный NCF. Отрезвляющее чтение.
Реализация NeuMF с пошаговыми объяснениями и рабочим кодом.
Обзор two-tower архитектуры от Google: от идеи до production deployment.
Библиотека для ANN-поиска. Стандарт де-факто для two-tower retrieval в production.