ARGUS: Scaling RecSys Transformers
ARGUS (Яндекс) — масштабирование рекомендательных трансформеров до 1B параметров. NIP + FP, scaling laws.
ARGUS — как Яндекс масштабировал рекомендательные трансформеры до 1B параметров
ARGUS (AutoRegressive Generative User Sequential modeling) — новый подход Яндекса к обучению рекомендательных трансформеров. Впервые в индустрии удалось масштабировать энкодер пользовательской истории до 1 миллиарда параметров и показать, что scaling laws работают не только в NLP, но и в рекомендациях. Модель уже внедрена в Яндекс Музыку, Маркет и Лавку — и везде дала серьёзный прирост метрик.
Проблема: почему рекомендательные трансформеры были маленькие
В NLP трансформеры давно вышли на миллиарды параметров — GPT-4, LLaMA, Gemini. А вот в рекомендательных системах до недавнего времени энкодеры пользовательской истории редко превышали 1-10 миллионов параметров. SASRec — два трансформерных блока с hidden size ~200. Даже HSTU от Meta дотянул только до 176M. Почему?
- Данные: классические модели (SASRec, BERT4Rec) видели только положительные взаимодействия — клики, покупки, лайки. Всё остальное выбрасывалось. Это как учить GPT только на хороших текстах — мало данных.
- Задача: стандартный Next Item Prediction предсказывает следующий «позитивный» айтем. Это слишком узкая задача — нет декомпозиции на множество подзадач, как next token prediction в NLP.
- Архитектура: маленькая история, маленький контекст, нет информации о «ситуации» пользователя (устройство, страница, настройки).
Три условия scaling
Команда Яндекса сформулировала три необходимых условия для успешного масштабирования нейросетей — и все три должны выполняться одновременно:
- Много данных — триллионы взаимодействий пользователей с сервисами
- Выразительная архитектура — трансформеры с большой ёмкостью
- Максимально общая задача обучения — не узкая классификация, а фундаментальное «понимание мира»
Первые два пункта в рексистемах были всегда. Проблема была в задаче. Стандартный NIP от SASRec — слишком узкий. ARGUS решает это с помощью новой формулировки.
Ключевая идея: полная история пользователя
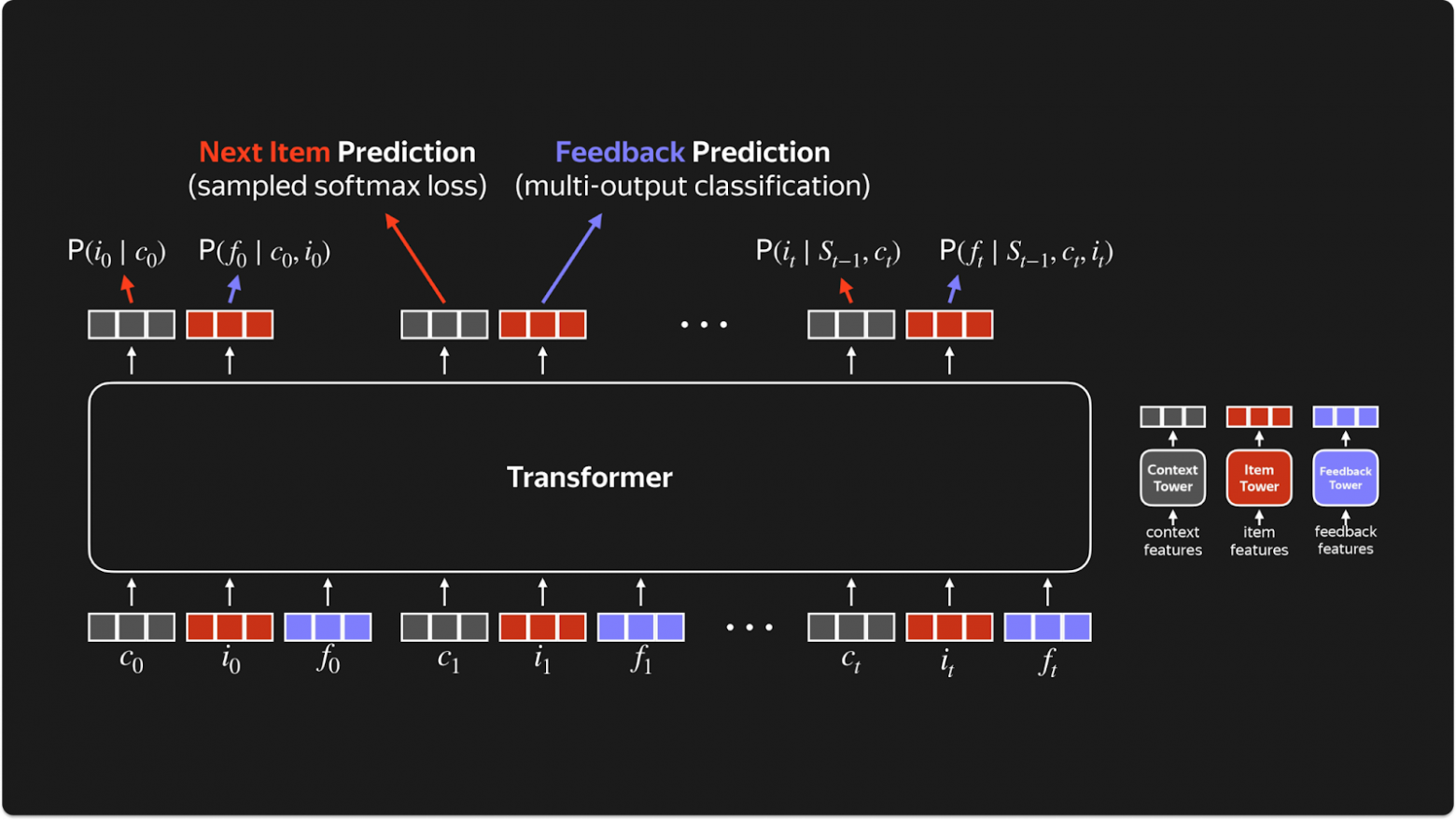
ARGUS не выбрасывает «неинтересные» события. Вместо последовательности только лайков или покупок, модель видит ВСЮ анонимизированную историю пользователя — и лайки, и скипы, и просто просмотры. Каждое событие кодируется тройкой: (context, item, feedback).
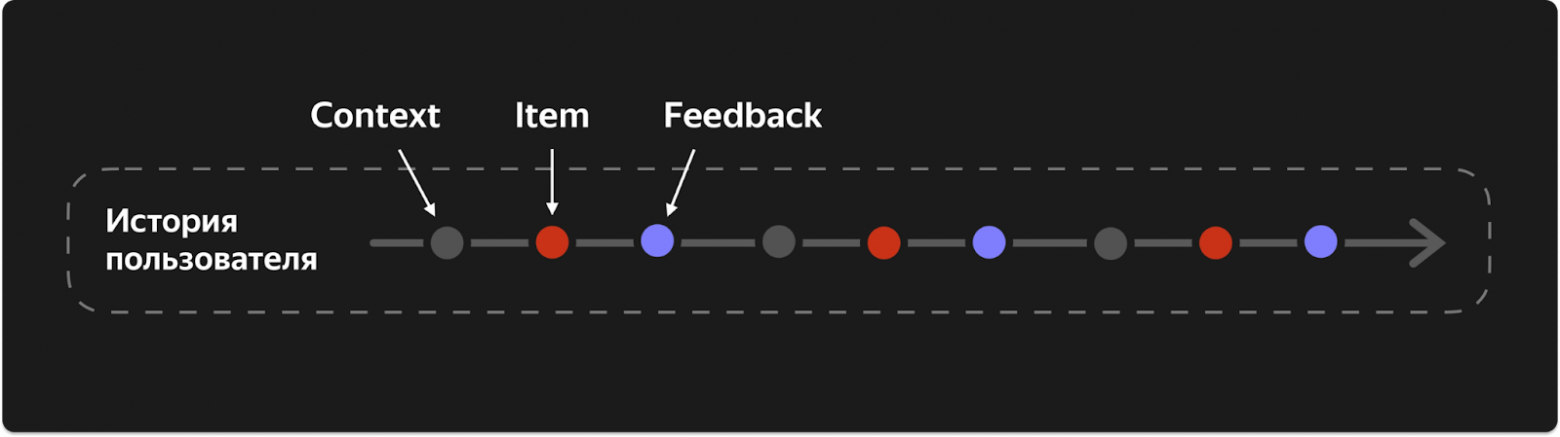
- Context — контекст взаимодействия: рекомендательный или органический трафик, какая «поверхность» (Моя волна, поиск, библиотека), настройки, устройство
- Item — объект взаимодействия (трек, товар, видео). Кодируется через item ID и unified embeddings
- Feedback — реакция пользователя: лайк, скип, доля прослушивания, добавление в плейлист
Аналогия с LLM
Две головы: NIP + FP
Вместо одной задачи ARGUS решает две одновременно — и это ключевое отличие от всех предшественников.
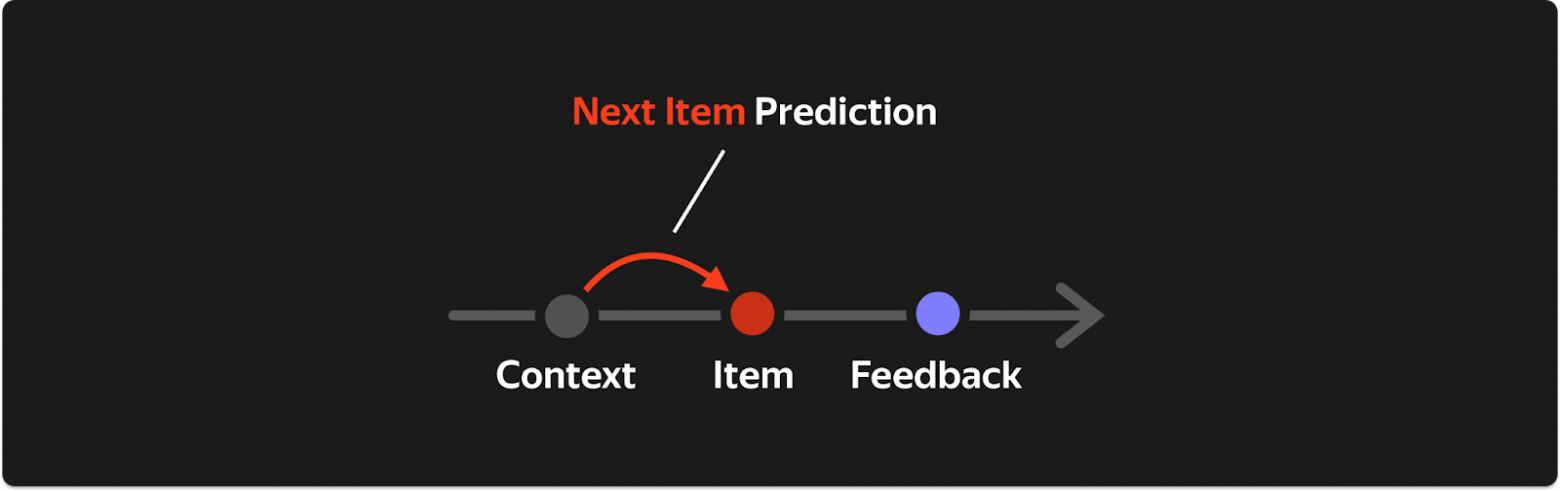
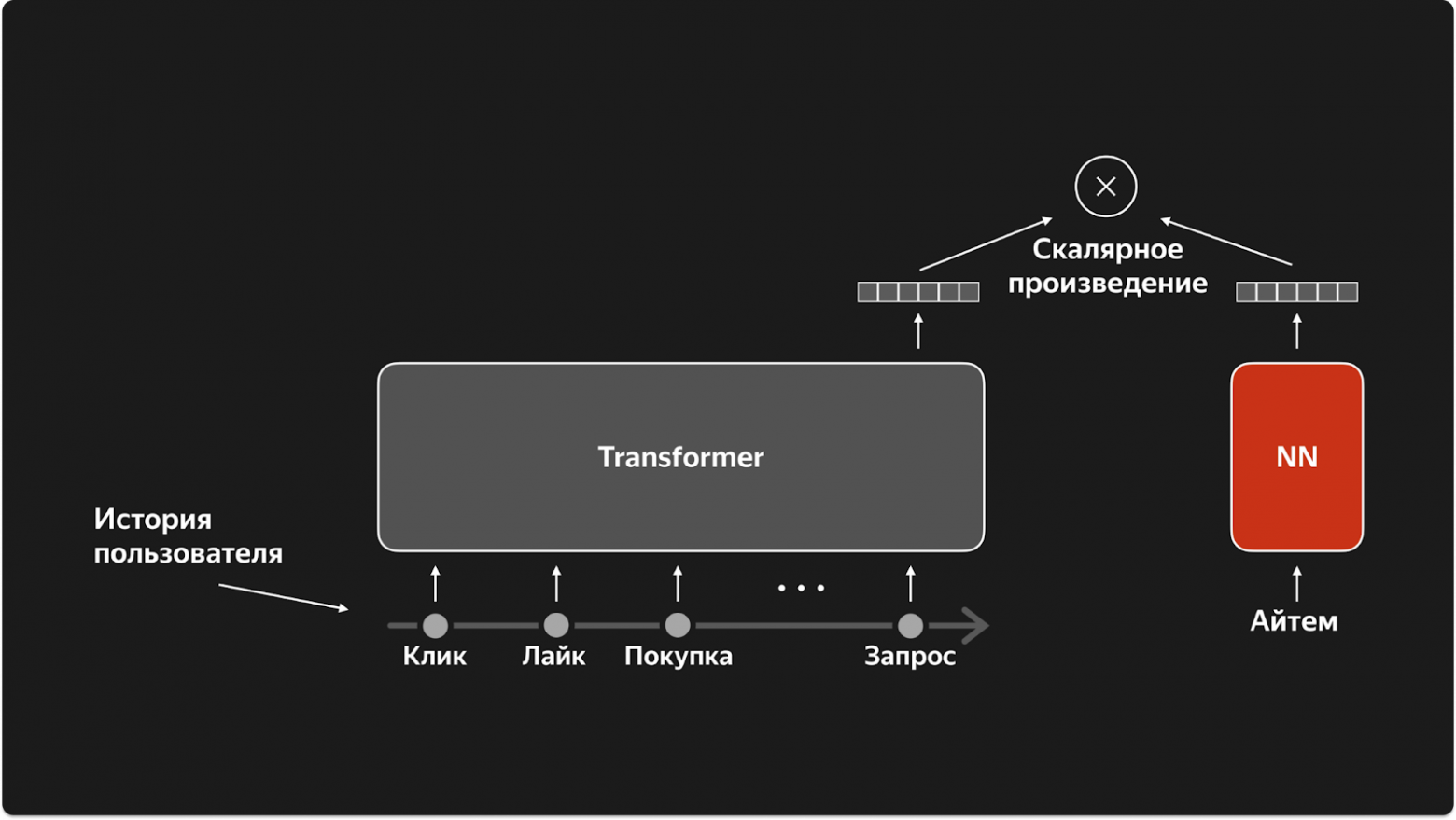
Next Item Prediction (NIP) — предсказываем, с каким айтемом будет следующее взаимодействие: P(item | history, context). Важно: в отличие от SASRec, предсказываем не только позитивные, но ВСЕ взаимодействия. Если в истории есть рекомендательный трафик — модель учится имитировать логирующую политику (действия прошлых рексистем). Если есть органический трафик — учит понимать пользователя глубже.
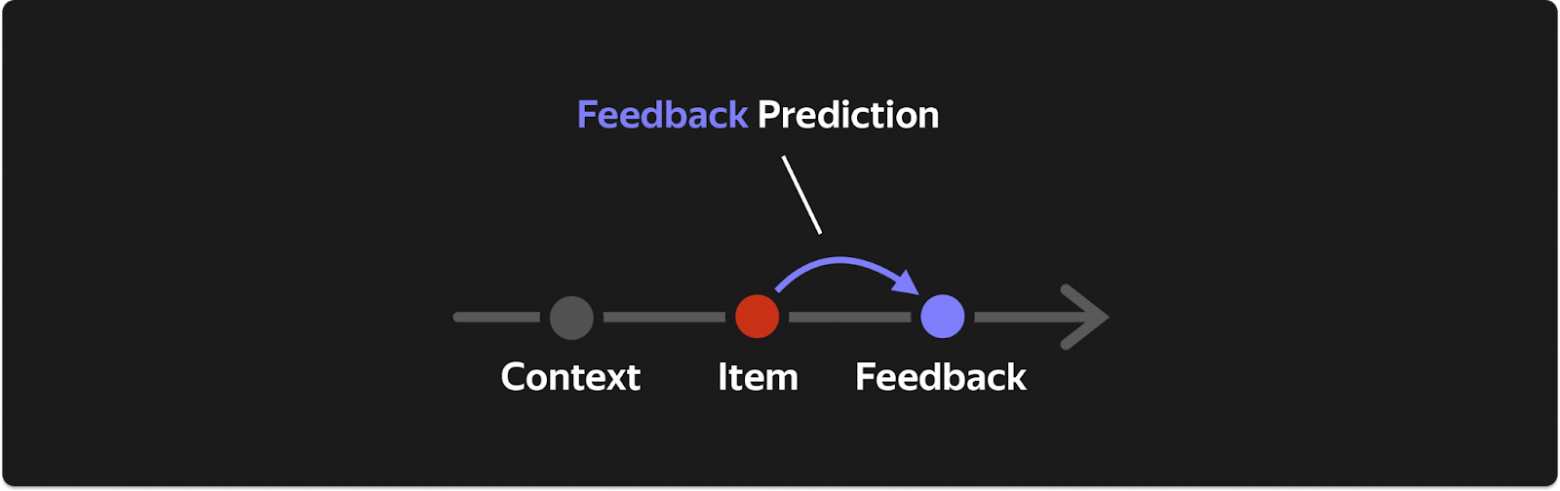
Feedback Prediction (FP) — предсказываем реакцию пользователя на айтем: P(feedback | history, context, item). Будет ли лайк? Какая доля трека будет прослушана? Это чисто про пользователя — его предпочтения, вкусы, настроение. Чем больше модель, тем лучше она учится предсказывать все типы фидбека одновременно — knowledge transfer между частым (прослушивания) и редким (лайки) сигналом.
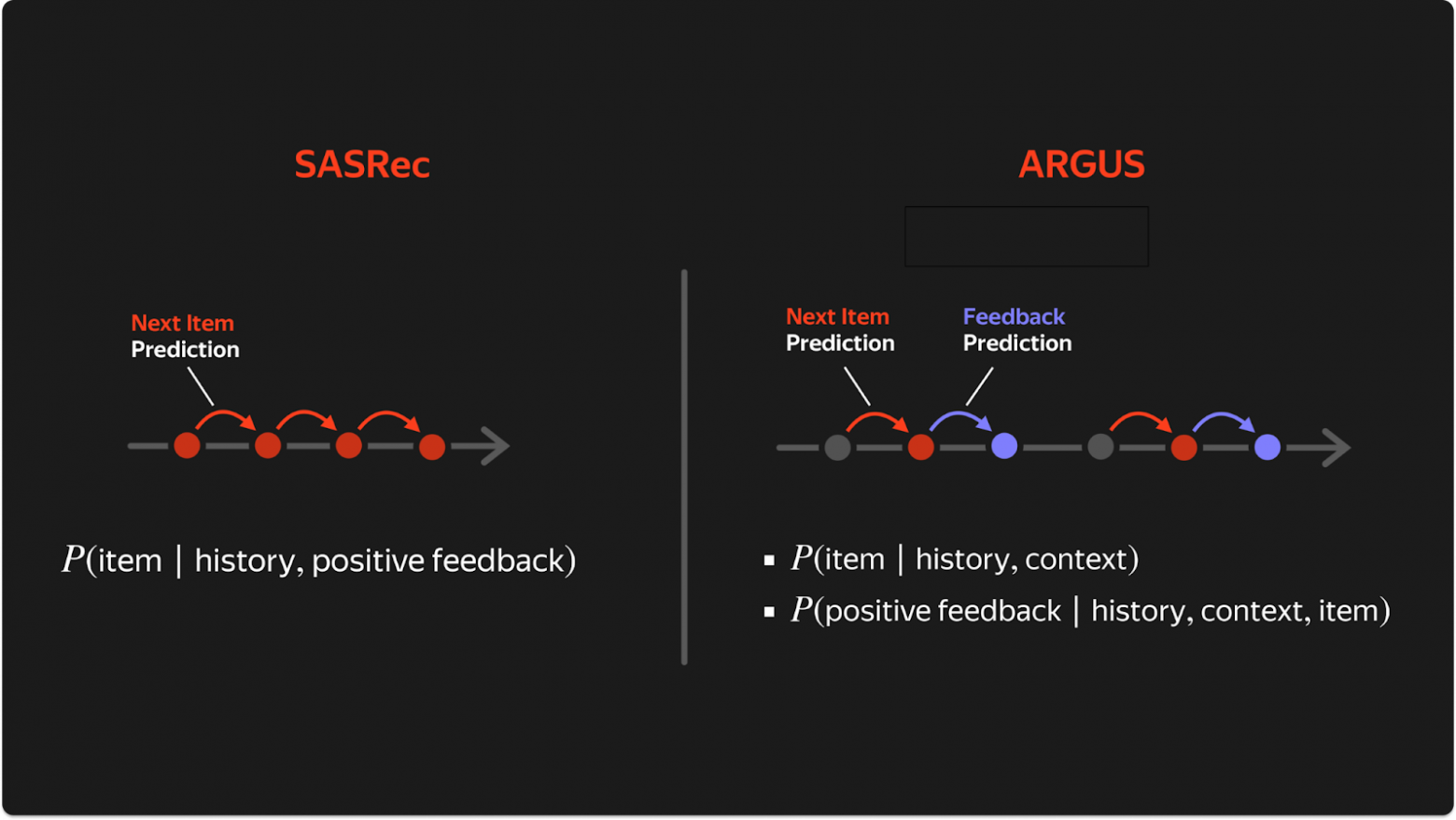
ARGUS vs SASRec — ключевое сравнение
Загрузка интерактивного виджета...
- SASRec видит только положительные взаимодействия → ARGUS видит всю историю (позитив + негатив + контекст)
- SASRec: одна задача (next positive item) → ARGUS: две задачи (NIP для всех взаимодействий + FP)
- SASRec не моделирует логирующую политику → ARGUS явно учится имитировать поведение прошлых рексистем
- SASRec не учит предпочтения пользователей → ARGUS через FP-голову учит «фундаментальные знания» о пользователях
А что HSTU от Meta?
Sampled Softmax — как обучить NIP-голову
NIP-задача формулируется как классификация по всему каталогу. Проблема: каталог — это миллионы или миллиарды айтемов. Полный softmax посчитать невозможно (в отличие от LLM, где словарь — сотни тысяч токенов). Решение — sampled softmax с logQ-коррекцией:
Sampled Softmax loss для NIP-головы. N — множество негативных семплов, Q(n) — вероятность семплирования негатива
- f(h, i) — скалярное произведение (или косинусная близость) скрытого состояния пользователя h и эмбеддинга айтема i
- τ — обучаемая температура (клипается в диапазоне [0.01, 100])
- N — негативные семплы: смесь in-batch негативов и равномерно случайных
- logQ(n) — коррекция за bias семплирования. Без неё модель начнёт «бояться» популярных айтемов, которые чаще попадают в негативы
import torch
import torch.nn.functional as F
def sampled_softmax_loss(
user_hidden, # (batch, d) — скрытое состояние пользователя
pos_item_emb, # (batch, d) — эмбеддинг позитивного айтема
neg_item_embs, # (batch, K, d) — K негативных айтемов
log_q_neg, # (batch, K) — log вероятностей семплирования
temperature=0.07, # обучаемая температура
):
"""Sampled Softmax с logQ-коррекцией (как в ARGUS NIP-head)."""
# Скоры для позитивного айтема
pos_score = (user_hidden * pos_item_emb).sum(-1, keepdim=True) / temperature
# Скоры для негативных, с коррекцией за sampling bias
neg_scores = torch.bmm(neg_item_embs, user_hidden.unsqueeze(-1)).squeeze(-1)
neg_scores = neg_scores / temperature - log_q_neg # logQ correction!
# Softmax loss: позитивный должен быть выше негативных
logits = torch.cat([pos_score, neg_scores], dim=-1) # (batch, 1+K)
labels = torch.zeros(logits.size(0), dtype=torch.long, device=logits.device)
return F.cross_entropy(logits, labels)
# В ARGUS: K=2048-8192 негативов, in-batch + random
# Без logQ коррекции: популярные айтемы наказываются непропорциональноScaling Laws для RecSys
Главный результат: ARGUS впервые показал scaling law для рекомендательных трансформеров. Четыре конфигурации — 3.2M, 42M, 151M, 1.007B параметров — и линейная зависимость качества от логарифма размера модели. Каждое увеличение даёт предсказуемый прирост. Это значит, что рекомендательные модели МОЖНО масштабировать, как LLM.

Бонус: HSTU-архитектура от Meta при 1.5x параметрах показала качество на уровне Medium трансформера. Обычный трансформер оказался не хуже (а то и лучше) кастомной архитектуры — проще, надёжнее, масштабируемее.
Авторегрессивное обучение — почему это быстро
Раньше для каждого «показа» рекомендации нужно было заново прогонять трансформер. Если у пользователя 10 000 событий за год — это 10 000 прогонов. ARGUS делает авторегрессивное обучение: один прогон трансформера с каузальной маской по всей истории — и сразу получаем скрытые состояния на все моменты времени. Ускорение: от 10 до 1000 раз.
Это позволило за те же вычислительные ресурсы обучать модели радикально большего размера. А на дообучении (fine-tuning на попарное ранжирование) — тоже один прогон: берём все показы рекомендаций за год, сопоставляем с нужными скрытыми состояниями и считаем все лоссы сразу.
Результаты: +12% TLT, +10% like likelihood

ARGUS прошёл через 5 поколений трансформеров в Яндекс Музыке. Первый ARGUS дал примерно такой же прирост метрик, как все 4 предыдущих внедрения суммарно. В режиме «Незнакомое» Моей волны:
- +12% TLT (Total Listening Time) — суммарное время прослушивания
- +10% like likelihood — вероятность лайка при включении рекомендации
- История 8K событий (раньше макс. 1.5-2K)
- Датасет: 300+ млрд прослушиваний от миллионов пользователей
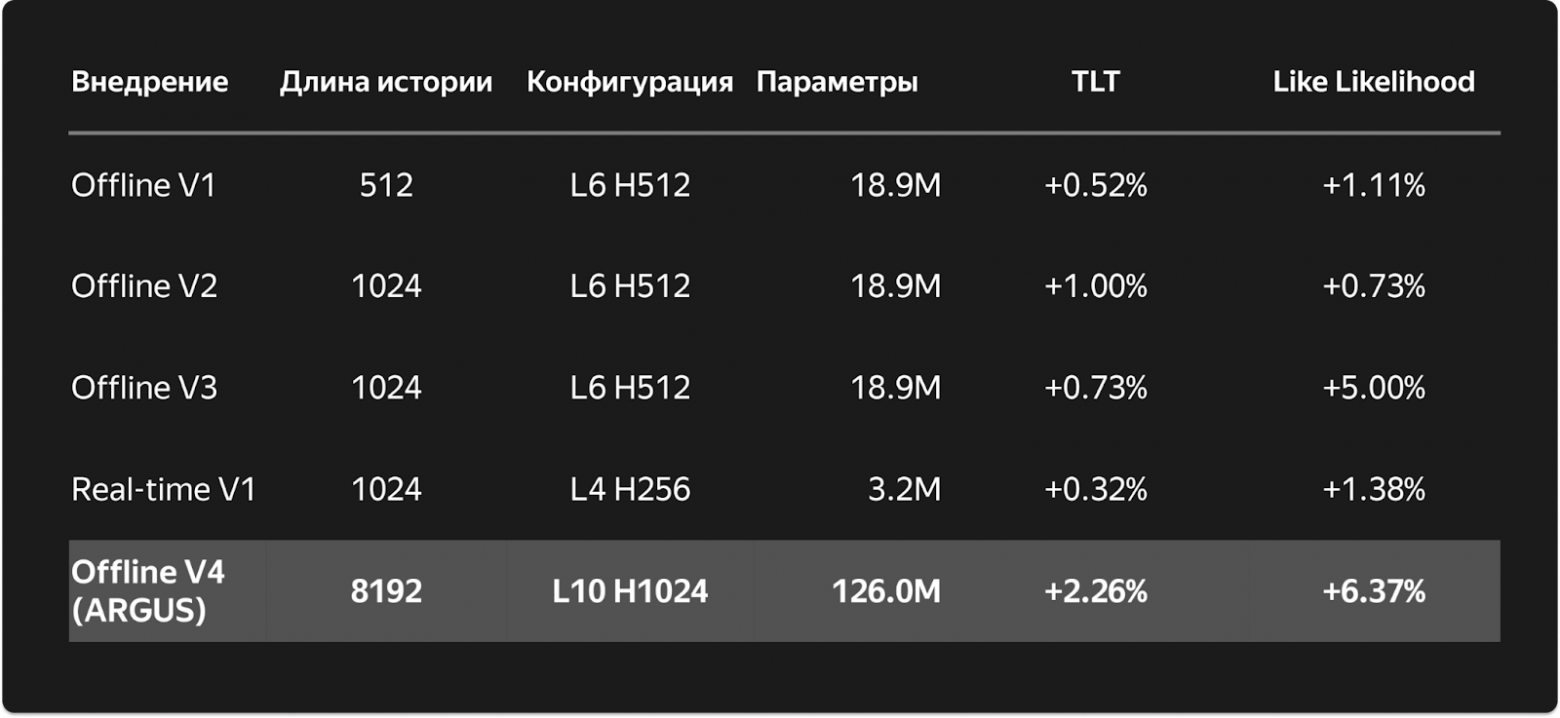
ARGUS уже внедрён в Яндекс Музыку (включая умные колонки), Маркет (и как ранжирование, и как генератор кандидатов) и Лавку. Команда Музыки адаптировала офлайн-ARGUS в рантайм-версию.
🎯 Что знать для собеседования
Материалы
Оригинальная статья — Khrylchenko et al.
Подробный разбор на русском от автора.
Предшественник: HSTU от Meta, генеративные рексистемы.
Классика: SASRec, с которым сравнивается ARGUS.