Продвинутый SQL
Оконные функции, CTE, EXPLAIN ANALYZE, индексы, партиционирование.
Продвинутый SQL — оконные функции, оптимизация и всё, что спрашивают на собесах
🗺️ Где это в общей картине
Базовый SQL (SELECT, JOIN, GROUP BY) — это 30% того, что спрашивают. Остальные 70% — оконные функции, CTE, EXPLAIN ANALYZE и индексы. Оконные функции — топ-1 тема на собеседованиях в дата-команды. Если ты не знаешь ROW_NUMBER() OVER() — будет больно.
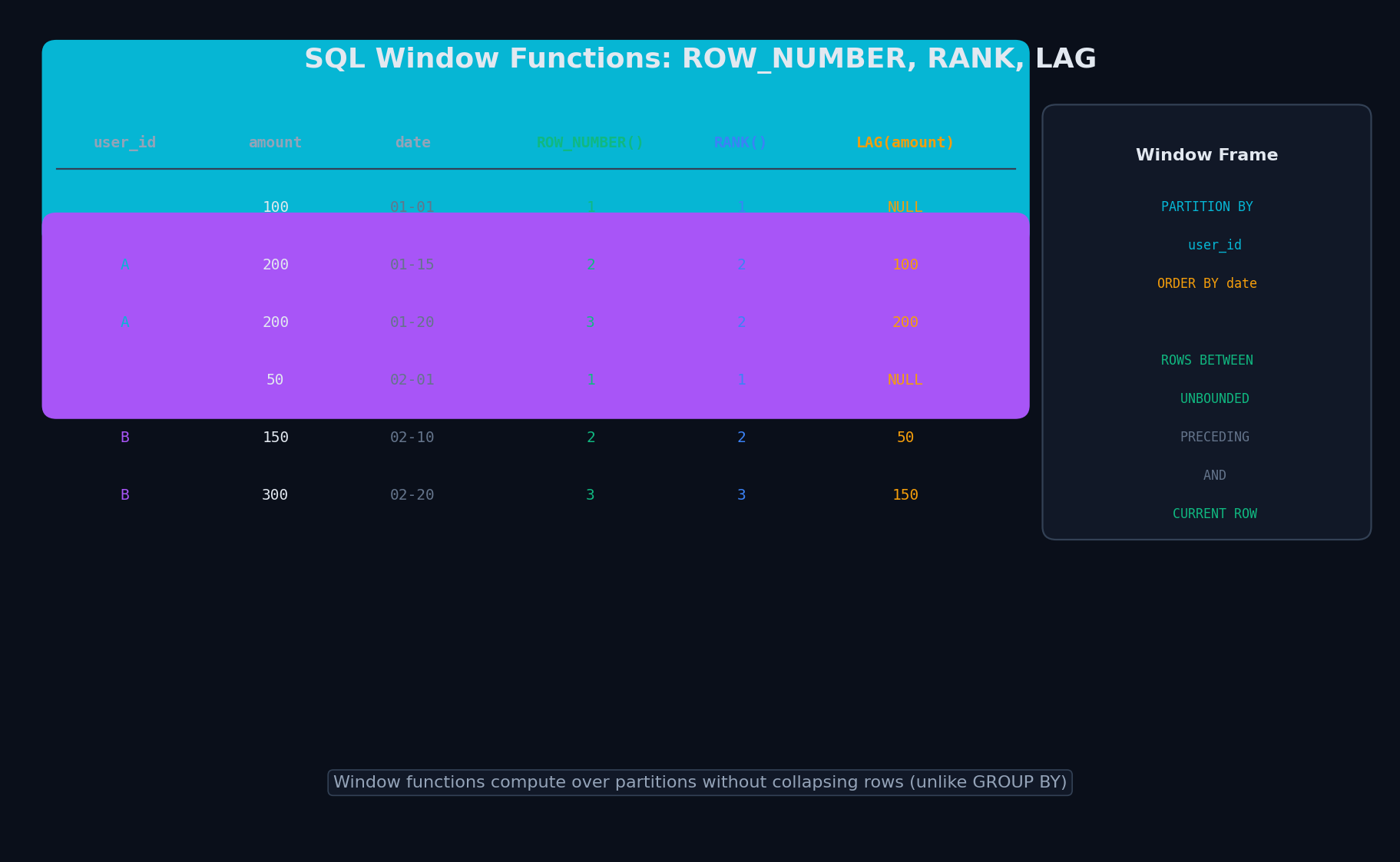
Оконные функции — считаем без потери строк
GROUP BY сворачивает строки: было 1000, стало 10 групп. А что если нужно и агрегат посчитать, и все строки оставить? Оконная функция делает именно это — каждая строка «видит» своё окно и считает агрегат, не схлопывая таблицу. Основные функции ранжирования: ROW_NUMBER (всегда уникальный номер), RANK (одинаковые значения → одинаковый ранг, потом пропуск), DENSE_RANK (без пропуска). Для аналитики: LAG/LEAD (предыдущее/следующее значение), SUM/AVG OVER (кумулятивные и скользящие агрегаты).
Классическая задача с каждого второго собеседования — дедупликация через ROW_NUMBER. А CTE (Common Table Expression) делает сложные запросы читаемыми — вместо вложенных SELECT пишешь цепочку WITH ... AS (...).
-- Дедупликация + CTE — оставить последнюю запись по пользователю
WITH ranked AS (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY user_id ORDER BY created_at DESC
) AS rn
FROM events
)
SELECT * FROM ranked WHERE rn = 1;
-- Кумулятивная сумма и day-over-day изменения
SELECT date, revenue,
SUM(revenue) OVER (ORDER BY date) AS cumulative,
revenue - LAG(revenue) OVER (ORDER BY date) AS day_change
FROM daily_revenue;🔥 Любимая задача на собесе
EXPLAIN ANALYZE и индексы — почему запрос тормозит
Запрос работает 30 секунд вместо 0.1. Почему? EXPLAIN ANALYZE покажет план: Index Scan (индекс работает, быстро) или Seq Scan (перебор всей таблицы, медленно). Каждый индекс замедляет INSERT/UPDATE, поэтому создавай их только на столбцы из WHERE и JOIN ON.
-- B-tree (по умолчанию) — для =, <, >, BETWEEN
CREATE INDEX idx_orders_user ON orders(user_id);
-- Составной — порядок столбцов важен!
-- Работает для WHERE user_id = X AND created_at > Y
-- НЕ работает для WHERE created_at > Y (без user_id)
CREATE INDEX idx_orders_user_date ON orders(user_id, created_at);
-- Частичный — только подмножество строк (меньше, быстрее)
CREATE INDEX idx_active ON orders(user_id) WHERE status = 'active';Партиционирование — делим таблицу на части
Таблица events на 500 млн строк — даже с индексом запросы медленные. Партиционирование разбивает таблицу на физические части (обычно по дате). Запрос WHERE created_at > '2024-01-01' просканирует только нужные партиции. В PostgreSQL: CREATE TABLE ... PARTITION BY RANGE (created_at), затем создаёшь партиции по месяцам. В ClickHouse и BigQuery партиционирование встроено и работает автоматически.
-- Партиционирование по дате (PostgreSQL)
CREATE TABLE events (
id BIGSERIAL, user_id INT,
event_type TEXT, created_at TIMESTAMPTZ
) PARTITION BY RANGE (created_at);
CREATE TABLE events_2024_01 PARTITION OF events
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
CREATE TABLE events_2024_02 PARTITION OF events
FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');
-- Запрос автоматически сканирует ТОЛЬКО нужные партиции🎯 На собесе
Транзакции — всё или ничего
Транзакция — группа SQL-команд, которая выполняется целиком или не выполняется вообще. ACID: Atomicity (атомарность — всё или ничего), Consistency (согласованность), Isolation (изоляция — параллельные транзакции не мешают), Durability (сохранность — данные не потеряются после commit).
BEGIN;
UPDATE features SET value = 0.95 WHERE user_id = 123 AND feature = 'score';
INSERT INTO predictions (user_id, model_version, result) VALUES (123, 'v2.1', 0.87);
COMMIT;
-- Если что-то сломалось → ROLLBACK; — обе операции отменятся🎯 Для ML
Блокировки — когда два процесса хотят одно и то же
Когда два процесса одновременно обновляют одну строку — БД ставит блокировку. Shared lock (FOR SHARE) — можно читать параллельно. Exclusive lock (FOR UPDATE) — только один пишет. Deadlock — два процесса ждут друг друга, БД убивает одного.
⚠️ Как избежать deadlock
Материалы
Подробный разбор оконных функций с примерами.
Лучший ресурс по SQL-индексам и оптимизации.
Практика SQL на Stepik с автопроверкой.
Визуальное объяснение оконных функций.
Курс PostgreSQL с практическими примерами.