PySpark
Обработка данных, которые не влезают в память одной машины: DataFrame API, Spark SQL, broadcast join, partitioning. Типичная ML-задача: собрать user-level фичи из 500 ГБ логов за 10 минут.
PySpark — обработка данных, которые не помещаются в память
Загрузка интерактивного виджета...
🗺️ Где это в общей картине
PySpark — это НЕ база данных и НЕ язык программирования. Это Python API для Apache Spark — движка распределённых вычислений. Суть простая: у тебя 500 ГБ логов пользователей, нужно посчитать retention. Pandas не справится — у него одна машина и оперативная память кончится. Spark раскидывает эти 500 ГБ на 50 машин, каждая обрабатывает свой кусок, результат собирается обратно. PySpark — это просто способ писать Spark-код на Python вместо Scala или Java.
В крупных компаниях PySpark используется каждый день для ETL, feature engineering, подготовки данных для ML. Если ты работаешь с данными больше нескольких гигабайт — рано или поздно встретишь Spark.
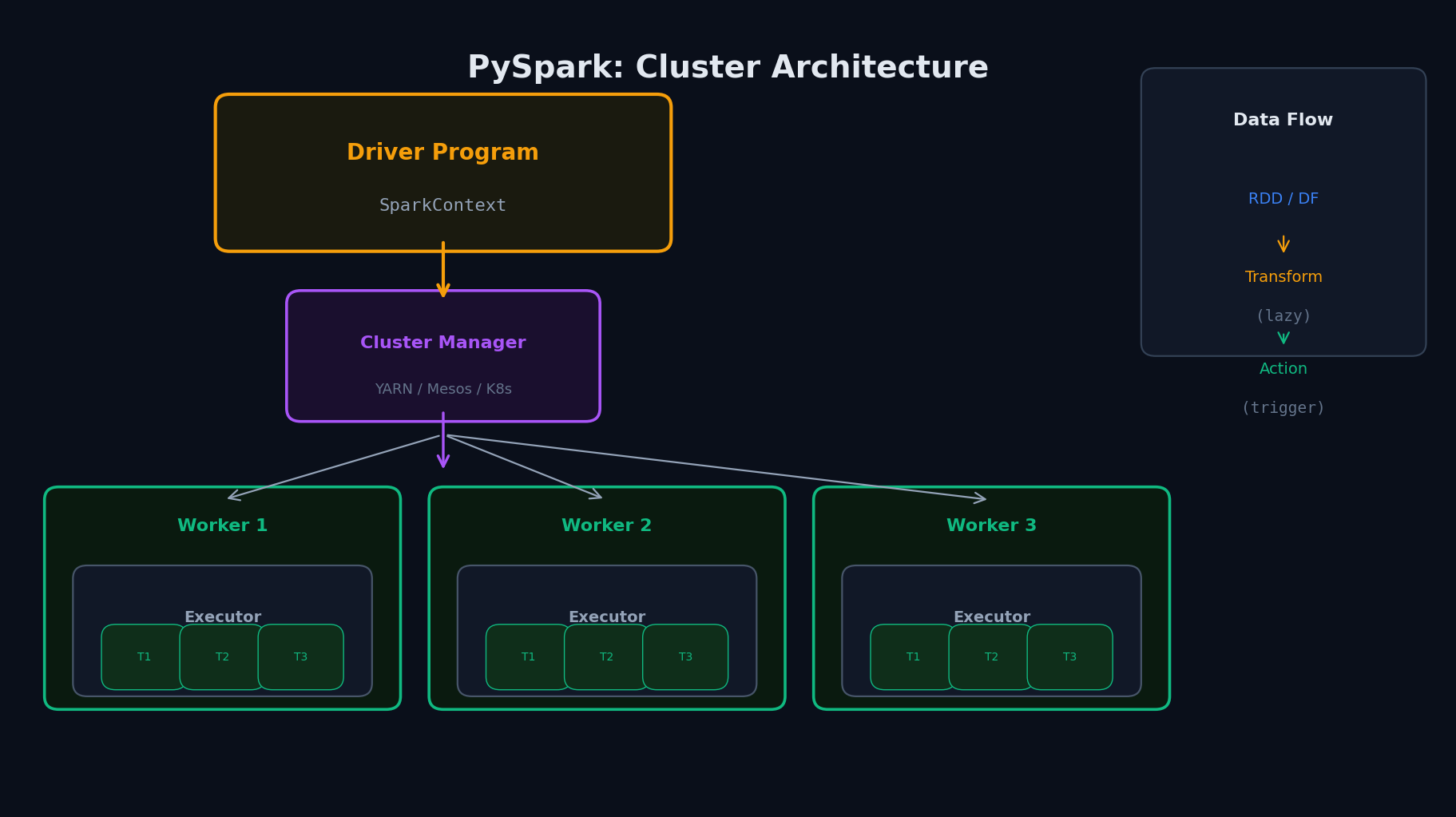
Когда нужен Spark, а когда хватит pandas
- Данные < 1-5 ГБ → pandas. Быстрее запустить, проще отлаживать, хватает одной машины
- Данные 5-500 ГБ → PySpark или Polars. Pandas уже не тянет, Spark раскидает по кластеру
- Данные > 500 ГБ → однозначно Spark. Альтернатив мало
- Ежедневная обработка по расписанию → Spark. Запускается через Airflow, хорошо интегрирован с S3/HDFS
Как устроен Spark (кратко)
- Driver — главный процесс: читает твой код, строит план выполнения (DAG), раздаёт задачи Workers
- Executor — рабочий процесс на узле кластера: выполняет задачи, хранит данные в памяти
- Partition — кусок данных на одном Executor-е. DataFrame из 100 ГБ → 200 партиций по 500 МБ на разных машинах
- Lazy evaluation — Spark НЕ выполняет код, пока ты не попросишь результат (count, show, write). Он сначала строит план и оптимизирует его
DataFrame API — основной интерфейс
Синтаксис похож на pandas, но под капотом — распределённые вычисления. Типичная задача ML-инженера: собрать user-level фичи из таблицы событий. Spark читает данные из S3 в формате Parquet, считает агрегаты по кластеру и записывает результат обратно.
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
spark = SparkSession.builder
.appName("FeatureEngineering")
.config("spark.sql.shuffle.partitions", 200)
.getOrCreate()
# Читаем из S3 (Parquet — стандартный формат для Spark)
events = spark.read.parquet("s3://data-lake/events/")
# Считаем фичи — синтаксис как pandas, работает на кластере
user_features = events
.filter(F.col("event_date") >= "2024-01-01")
.groupBy("user_id")
.agg(
F.count("*").alias("purchase_count"),
F.sum("amount").alias("total_spent"),
F.avg("amount").alias("avg_order"),
F.countDistinct("product_id").alias("unique_products")
)
# Сохраняем обратно в S3
user_features.write
.mode("overwrite")
.parquet("s3://data-lake/features/user_features/")Spark SQL — если привык к SQL
Можно не учить DataFrame API и писать обычный SQL. Spark выполнит его распределённо. Для ML-инженеров, которые пришли из аналитики, это удобнее.
events.createOrReplaceTempView("events")
result = spark.sql(""
SELECT user_id, COUNT(*) AS total_events,
SUM(CASE WHEN event_type = 'purchase' THEN 1 ELSE 0 END) AS purchases
FROM events
WHERE event_date >= '2024-01-01'
GROUP BY user_id
"")Оптимизация — самое важное для собеса
⚠️ Shuffle — главный тормоз
Три главных приёма оптимизации: broadcast join для маленьких таблиц, правильное партиционирование и избегание collect().
from pyspark.sql.functions import broadcast
# ❌ JOIN двух больших таблиц — shuffle обеих
result = big_events.join(big_users, "user_id")
# ✅ broadcast маленькой таблицы (< 10 МБ) — без shuffle
result = big_events.join(broadcast(small_dim), "category_id")
# ✅ coalesce для уменьшения партиций (без shuffle)
df.coalesce(10).write.parquet("output/")
# ❌ НИКОГДА: collect() на большом DataFrame — OOM
# ✅ Вместо этого: limit() или take()
sample = df.limit(100).toPandas()Партиционирование на диске
При записи в Parquet можно разбить файлы по значению столбца (обычно по дате). При чтении Spark загрузит только нужные файлы. Запрос за один день читает 1 партицию вместо 365.
- Партиционируй по столбцам, по которым часто фильтруешь: дата, регион, тип события
- НЕ партиционируй по user_id — получишь миллионы крошечных файлов (small files problem)
- Оптимальный размер файла: 128 МБ — 1 ГБ
- Parquet — стандарт: колоночное хранение, сжатие, pushdown фильтров. Не используй CSV в Spark
💡 Как это в реальной работе
PySpark для ML: специфичные задачи
В ML-проектах PySpark используется не только для стандартного ETL. Вот задачи, которые встречаются именно у ML-инженеров:
- Партиционирование эмбеддингов: 100M эмбеддингов по 768 измерений — это ~300 ГБ. Партиционируй по user_segment или hash(user_id) % N, чтобы ANN-индекс (FAISS) строился на каждой партиции отдельно
- Approximate joins для больших таблиц: exact join двух таблиц по 500M строк убьёт кластер shuffle-ом. Решение: broadcast меньшую таблицу, или используй approx_count_distinct / bloomFilterAggregate для предфильтрации
- Feature engineering на масштабе: оконные функции для time-based фичей (last_7d_purchases), percentile_approx для квантилей без OOM, countDistinct с approx для кардинальности
- Train/test split на кластере: stratified split по target + времени, чтобы не было data leakage. sampleBy() для стратификации, monotonically_increasing_id() для воспроизводимости
🎯 На собеседовании
Junior
Middle
Senior