Оркестрация
Airflow, Dagster, Prefect — оркестраторы, которые запускают ML-пайплайн каждый день: extract данных → compute фичей → retrain модели → deploy. DAG, scheduling, retries, алерты.
Оркестрация — чтобы пайплайн работал каждый день без тебя
Загрузка интерактивного виджета...
🗺️ Где это в общей картине
Airflow — это cron на стероидах. Он НЕ обрабатывает данные — он планирует и запускает задачи. У cron нет зависимостей между задачами, ретраев, алертов, UI для мониторинга. У Airflow — есть. Ты описываешь DAG (граф зависимостей) Python-кодом, задаёшь расписание — и Airflow каждое утро выполняет цепочку шагов, перезапуская упавшие и отправляя алерты в Slack.
Конкретный пример: каждое утро в 6:00 Airflow запускает DAG: скачать данные из прод-базы → обработать PySpark-ом → посчитать фичи → обучить модель → проверить метрики → задеплоить → уведомить в Slack. Если шаг 3 упал — Airflow перезапустит только его, а не весь пайплайн.
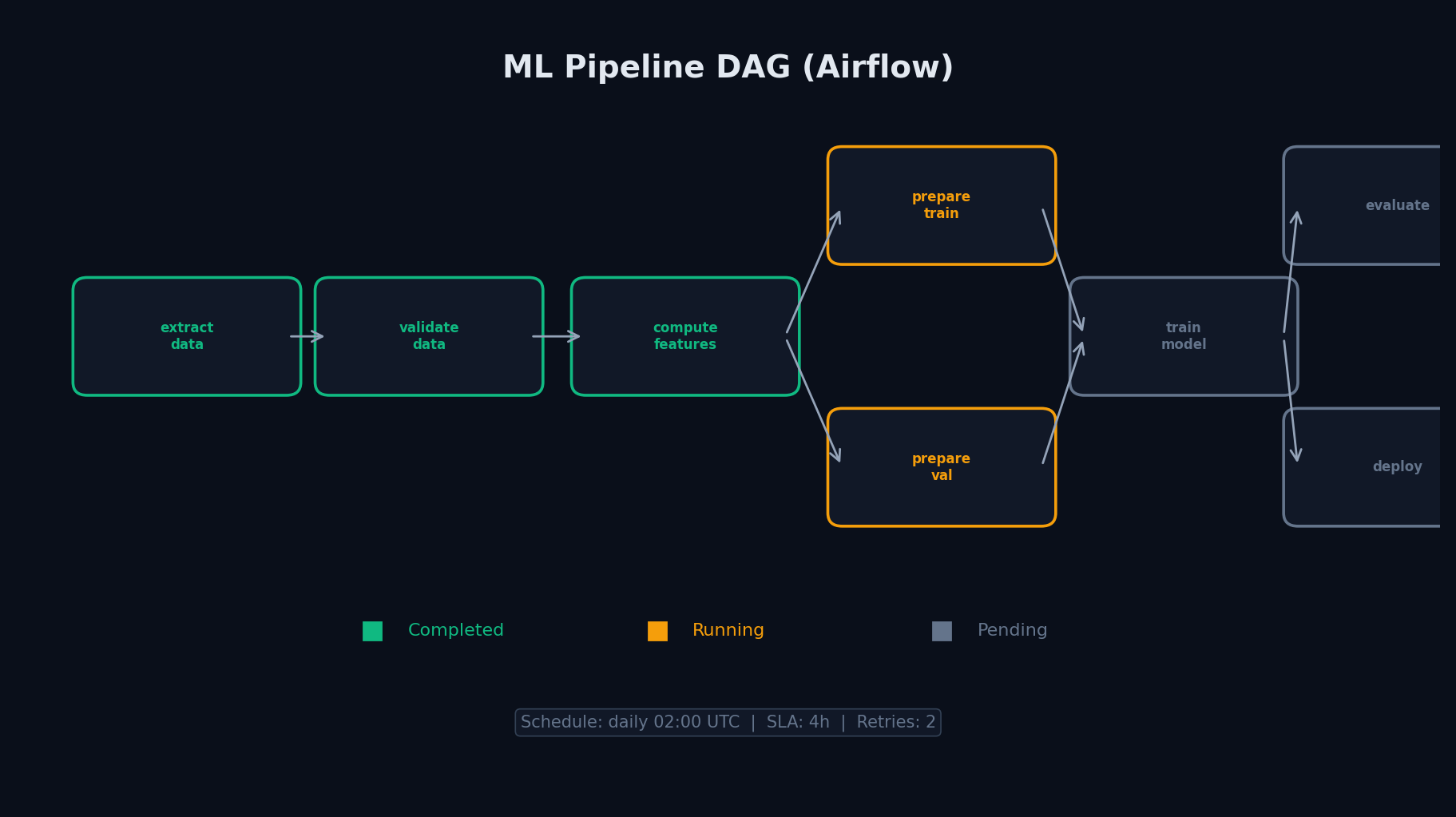
Apache Airflow — стандарт индустрии
Airflow создан в Airbnb, сейчас Apache-проект. Используется повсеместно — от стартапов до крупных компаний. Если ты будешь работать с пайплайнами — Airflow встретится почти наверняка.
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from datetime import datetime, timedelta
default_args = {
"owner": "ml-team",
"retries": 3,
"retry_delay": timedelta(minutes=5),
"email_on_failure": True,
}
with DAG(
dag_id="ml_training_pipeline",
default_args=default_args,
schedule="0 6 * * *", # каждый день в 6:00
start_date=datetime(2024, 1, 1),
catchup=False,
tags=["ml", "training"],
) as dag:
extract = BashOperator(
task_id="extract_data",
bash_command="python scripts/extract.py --date {{ ds }}",
)
train = PythonOperator(
task_id="train_model",
python_callable=train_and_log_model,
)
deploy = BashOperator(
task_id="deploy_model",
bash_command="python scripts/deploy.py",
)
# Зависимости — кто после кого
extract >> train >> deployКлючевые понятия Airflow
- DAG — граф задач без циклов. Определяет ЧТО выполнять и В КАКОМ ПОРЯДКЕ
- Task — единица работы: PythonOperator, BashOperator, SparkSubmitOperator
- Schedule — cron-выражение: "0 6 * * *" = каждый день в 6:00
- Sensor — ожидание события: файл появился в S3, данные готовы. Пайплайн не стартует раньше времени
- XCom — передача маленьких данных между задачами (пути, ID, метрики)
- Backfill — запустить пайплайн за прошлые даты при изменении логики
Dagster — современная альтернатива
Dagster — «Airflow нового поколения». Главное отличие: вместо задач (tasks) ты думаешь в терминах данных (assets). Не «задача A → задача B», а «dataset A → трансформация → dataset B». Dagster сам строит DAG из зависимостей между assets. Плюсы: встроенное тестирование, type checking, лучший developer experience. Если начинаешь с нуля — стоит рассмотреть.
import dagster as dg
import pandas as pd
@dg.asset(description="Raw events from production DB")
def raw_events() -> pd.DataFrame:
return pd.read_sql("SELECT * FROM events WHERE date = CURRENT_DATE", conn)
@dg.asset(description="User-level features for ML")
def user_features(raw_events: pd.DataFrame) -> pd.DataFrame:
# Dagster видит зависимость: user_features нужен raw_events
return raw_events.groupby("user_id").agg(
total_events=("event_id", "count"),
total_revenue=("amount", "sum"),
).reset_index()
# Dagster автоматически строит DAG: raw_events → user_featuresPrefect — Python-first оркестрация
Prefect — самый простой API. Берёшь обычную Python-функцию, добавляешь декоратор @flow — и она становится пайплайном с ретраями и мониторингом. Хорош для небольших команд, которым не нужен тяжёлый Airflow.
Что выбрать
- Airflow — стандарт. Огромная экосистема, 100+ операторов, все знают. Сложнее в настройке, но проверен годами
- Dagster — для ML-команд. Asset-oriented, встроенное тестирование. Лучший DX, но экосистема меньше
- Prefect — самый простой API. Для небольших команд и быстрого старта
- Kubeflow Pipelines — если ML-платформа на Kubernetes и нужен inference на GPU
💡 Как это в реальной работе
ML-специфика оркестрации
Для ML-инженера оркестратор — не просто «запускалка ETL». У ML-пайплайнов свои паттерны:
- Backfill для ретрейна: изменил логику фичей → нужно пересчитать фичи за последние 90 дней. Airflow backfill запускает DAG за каждую прошлую дату
- SLA на свежесть фичей: модель рекомендаций должна получить свежие фичи до 8:00. Если ETL не успел — алерт, и модель работает на вчерашних данных (degraded mode)
- Data quality gates: перед обучением — проверка: нет ли дрифта в данных (PSI), все ли источники доступны, нет ли аномалий в фичах. Если gate не пройден — модель не обучается, уведомление в Slack
- Feature freshness monitoring: sensor ждёт, пока Spark-задача посчитает фичи, прежде чем запускать обучение. Без sensor — модель может обучиться на устаревших данных
🎯 На собеседовании
Junior
Middle
Senior