Мониторинг и Observability
Data drift, model drift, Prometheus/Grafana, алерты, Evidently.
Мониторинг ML — ловим деградацию до того, как бизнес позвонит
Загрузка интерактивного виджета...
Модель задеплоили, метрики отличные. Через 3 месяца конверсия просела на 15%. Начали разбираться — оказалось, модель деградировала из-за изменения данных (drift), но никто не заметил. Мониторинг ML — это не только Prometheus с Grafana для latency и errors. Это ещё data drift, prediction drift, model staleness — вещи, которых в классическом DevOps просто нет.
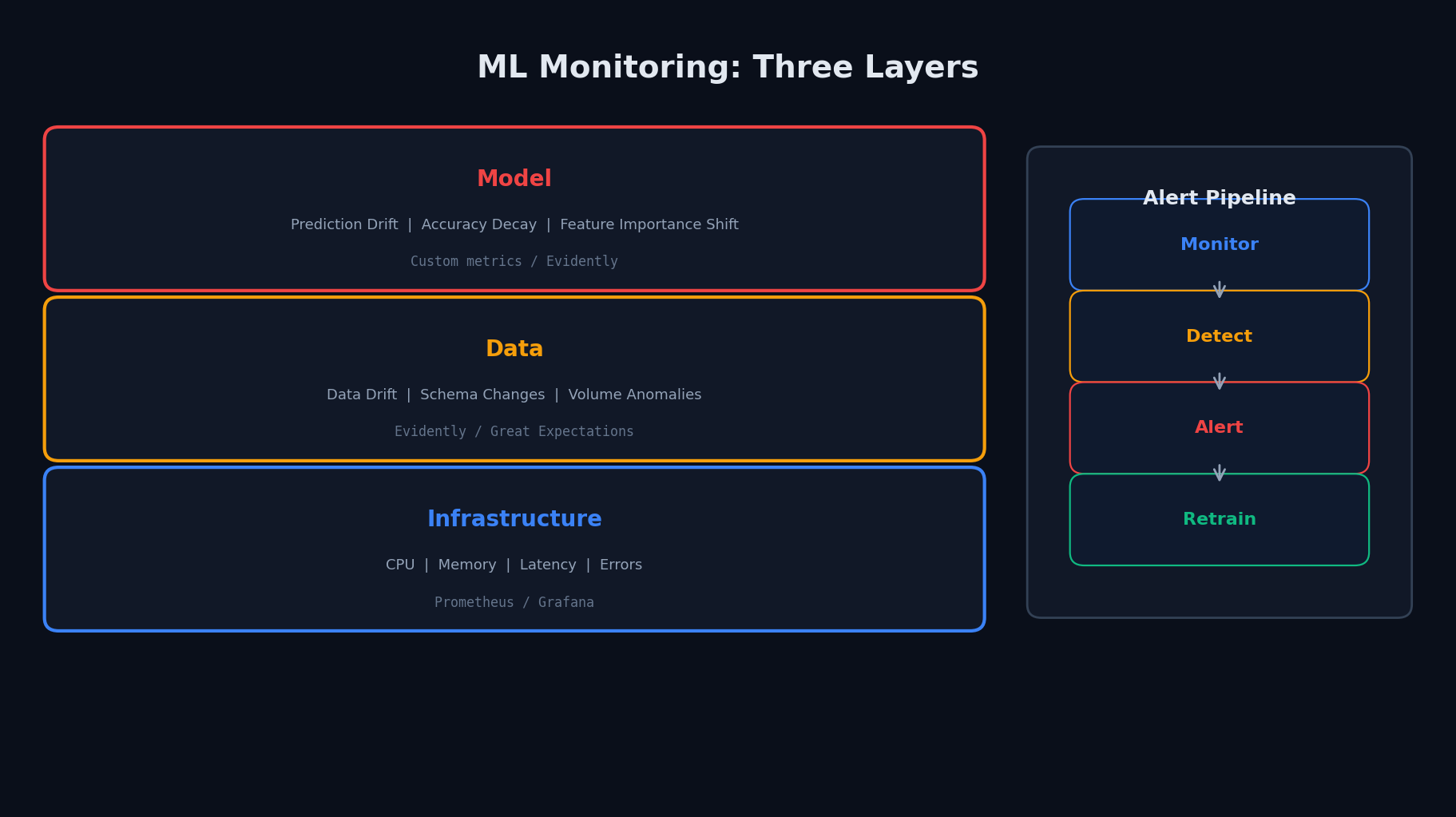
Что мониторить — четыре уровня
- Infrastructure — CPU/GPU, memory, latency p50/p95/p99, error rate, throughput. Стандартный мониторинг сервиса
- Data — распределение фичей сдвинулось? Новые NULL-ы? Схема изменилась? Объём данных в норме?
- Model — распределение предсказаний изменилось? Confidence упал? Модель давно не переобучалась?
- Business — CTR, конверсия, revenue, retention — метрики, ради которых всё затевалось
Data Drift и Concept Drift
Data drift — распределение входных фичей P(X) изменилось по сравнению с обучающей выборкой. Модель обучена на данных до пандемии, а в 2020 поведение радикально изменилось. Детектируется метриками PSI (Population Stability Index: < 0.1 — ок, 0.1-0.25 — стоит посмотреть, > 0.25 — сильный drift) и KS-тестом (Kolmogorov-Smirnov). Concept drift — ещё хуже: данные могут выглядеть так же, но связь P(Y|X) изменилась. Раньше «клики» коррелировали с покупкой, после редизайна — нет.
- Gradual drift — медленные изменения: сезонность, инфляция. Детектируется скользящими метриками
- Sudden drift — резкий скачок: пандемия, редизайн. Детектируется алертами на резкое падение
- Recurring drift — циклические изменения: праздники, выходные. Можно учесть при обучении
Evidently — мониторинг ML из коробки
Evidently — Python-библиотека для отчётов о drift и качестве модели. Даёшь ей train-данные (эталон) и prod-данные (текущие) — она сравнивает распределения и генерирует HTML-отчёт. TestSuite даёт автоматическую проверку True/False — если drift обнаружен, отправляешь алерт в Slack.
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset, TargetDriftPreset
from evidently.test_suite import TestSuite
from evidently.test_preset import DataDriftTestPreset
# HTML-отчёт с графиками распределений
report = Report(metrics=[DataDriftPreset(), TargetDriftPreset()])
report.run(reference_data=train_df, current_data=prod_df)
report.save_html("drift_report.html")
# Автоматическая проверка — True/False
tests = TestSuite(tests=[DataDriftTestPreset()])
tests.run(reference_data=train_df, current_data=prod_df)
if not tests.as_dict()["summary"]["all_passed"]:
send_alert("🚨 Data drift detected!")Prometheus + Grafana — мониторинг сервиса
Prometheus собирает метрики, Grafana визуализирует. Для ML-сервиса добавляем специфичные метрики поверх стандартных (latency, errors): распределение confidence (Histogram с бакетами 0.1-1.0), количество предсказаний по версиям модели (Counter с лейблами). Алерты настраиваются в Prometheus: p99 latency > 500ms, error rate > 5%, median confidence < 0.3 — всё это сигналы о проблемах.
from prometheus_client import Counter, Histogram
PREDICTIONS = Counter(
'model_predictions_total', 'Total predictions',
['model_version', 'result']
)
LATENCY = Histogram(
'model_prediction_seconds', 'Prediction latency',
buckets=[0.01, 0.05, 0.1, 0.25, 0.5, 1.0]
)
CONFIDENCE = Histogram(
'model_confidence', 'Confidence distribution',
buckets=[0.1, 0.2, 0.3, 0.5, 0.7, 0.9, 1.0]
)
@app.post("/predict")
async def predict(request: PredictRequest):
with LATENCY.time():
result = model.predict_proba(request.features)
PREDICTIONS.labels(model_version="v2.3", result="success").inc()
CONFIDENCE.observe(float(max(result[0])))💡 Как это в реальной работе
💡 Чек-лист: что мониторить
🎯 На собесе